
A-sustainable-deep-learning-framework-for-object-recognition

A sustainable deep learning framework for object recognition using multi-layers deep features fusion and selection
Google Scholar Link -> https://scholar.google.com/citations?user=F5u_Z5MAAAAJ
Paper Link -> https://www.mdpi.com/2071-1050/12/12/5037
Feature Extraction
In proposed method, we first employed VGG-VeryDeep-19 model for feature extraction. Each model has different layers and hence the output may vary from model to model. We exploited this advantage of DeepCNN and extracted feature using FC-7 layer. And finally the average pooling is performed for noise
removal. A feature vector of length 1x4096 is obtained for each image. Secondly we applied Inception-V3 for feature extraction, and the feature are extracted using “avg_pool” layer. A feature vector of length 1x2048 is obtained as the output.

Main Model
Deep Learning Features Extraction
Feature Extraction using VGG-19
Feature Extraction using InceptionV3
Feature Extraction using TL
In the feature extraction step, we are employing TL. Using TL, we retrain both specific CNN models (VGG19 and InceptionV3) on the selected datasets. For training, we set a 60:40 approach along with labeled data. Furthermore, we perform preprocessing, in which we resize the images according to the input layer of each model. Later, we select the input convolutional layer and output layer as feature mapping. For VGG19, we choose the first convolutional layer as an input layer and FC7 as an output. After that, the CNN activation is performed, and we obtain training and testing vectors. On feature layer FC7, a resultant feature vector is obtained of dimension denoted by and utilized in the next process. A modified architecture of VGG19 is also shown in Figure 3. For Inception V3, we select the first convolutional layer as input and the Average Pool layer as a Feature Map. Similar to VGG19, we perform TL and retrain this model on the selected datasets, and apply the CNN activation on the Average Pool layer. On this layer, we obtain a feature vector of dimension and denoted by Both training and testing vectors proceed for the next features fusion process. The modified architecture of Inception V3 is shown in Figure 2. In this figure, it is shown that the last three layers are removed before retrained on the selected datasets for this work.
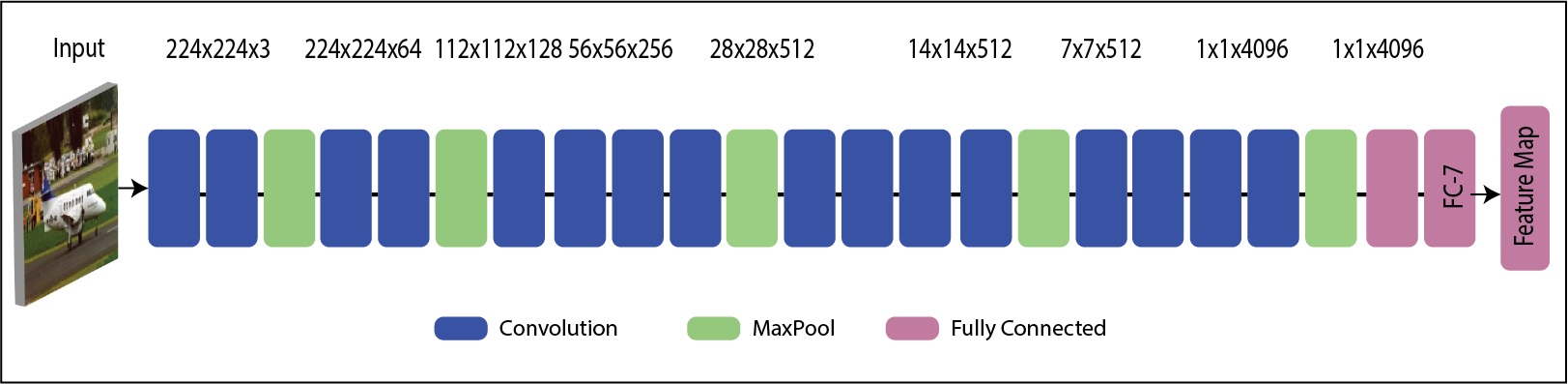
Modified VGG-19 architecture for features extraction

Modified Inceptionv3 architecture for features extraction
Feature Fusion
The fusion of multiple features in one matrix is the latest research area of pattern recognition. The primary purpose of feature fusion is to obtain a stronger feature vector for classification. From the latest research, it is noticed that the fusion process improves the overall accuracy, but on the other side, its main disadvantage is high computational time (sec). However, our usual priority is to improve the classification accuracy. For this purpose, we implement a new Parallel Maximum Covariance (PMC) approach for features fusion. In this approach, we need to equalize the length of both extracted feature vectors. Later, we find the maximum covariance for fusion in a single matrix.
Consider two deep learning feature vectors and of dimensions and, where denotes the number of images, indicates VGG19 deep learning feature vector length of and denotes Inception V3 feature vector of dimension , respectively. To make the length of vectors equal, we first find out the maximum length vector and perform average value padding. The average feature is calculated from a higher length vector. Let be an arbitrary unit column vector presenting a pattern in field and indicates a random unit column vector representing a pattern in the field, respectively. For time series projection on row vectors are defined as follows:

Where, is the covariance value among and whose and features are 263 and . Hence, the feature pair and of maximum covariance is saved in the 264 final fused vector. However, it is possible that few of the feature pairs are redundant. This process is 265 continued until all pairs are compared with each other. In the end, a fused vector is obtained 266 denoted by of dimensions where denotes the feature-length, which varies based on 267 the selected features. In this work, the fused feature-length is for the Caltech101 dataset, 268 for Birds dataset, and for Butterflies dataset.
4.3. Feature Selection






Results
 Caltech Dataset Results
Caltech Dataset Results
 Butterflies Dataset Results
Butterflies Dataset Results
 Birds Dataset Results
Birds Dataset Results
Please cite us, if you use these codes , Codes written and used for Object Detection and Classifications paper
contact us if facing any issue
Rashidcui@ciitwah.edu.pk
Rashid047571@gmail.com
引用格式
Muhammad Rashid (2025). A-sustainable-deep-learning-framework-for-object-recognition (https://github.com/rashidrao-pk/A-sustainable-deep-learning-framework-for-object-recognition-using-multi-layers-deep-features-fusion), GitHub. 检索时间: .
MATLAB 版本兼容性
平台兼容性
Windows macOS Linux标签
Community Treasure Hunt
Find the treasures in MATLAB Central and discover how the community can help you!
Start Hunting!codes
无法下载基于 GitHub 默认分支的版本
| 版本 | 已发布 | 发行说明 | |
|---|---|---|---|
| 1.0.0 |
|
您也可以从以下列表中选择网站:
美洲
- América Latina (Español)
- Canada (English)
- United States (English)
欧洲
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom(English)
亚太
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)