Modeling and Simulation in Drug Development with SimBiology
This webinar introduces SimBiology® as a modeling environment for mechanistic pharmacokinetic (PK), pharmacodynamic (PD), and quantitative systems pharmacology (QSP) modeling and simulation. The webinar shows how to use the SimBiology Model Builder app to build a mechanistic model. Once the model is complete, you can learn how to use the SimBiology Model Analyzer app to calibrate the model to experimental data and perform model predictions. Watch the webinar whether you are new to SimBiology or if you already use SimBiology and would like to learn more about the new Model Builder and Model Analyzer apps.
This webinar explores a case study for sglt2 therapy for Type 2 diabetes, and shows how to:
- Build compartmental and mechanistic models
- Estimate parameters
- Simulate ‘what if’ scenarios and parameter scans
- Share model with colleagues using Web Apps
Published: 28 Dec 2020
Welcome to this webinar on modeling and simulation in drug development with SimBiology. My name is Sietse Braakman. I'm a senior application engineer at MathWorks for computational biology. I work across North America and help all of our customers in academia and the pharmaceutical industry who use SimBiology.
In today's webinar, I want to give you an overview of how SimBiology is used for modeling and drug development, then move on to a case study where we investigate whether SGLT2 inhibition could be a feasible therapy to treat type 2 diabetes. And this will include building a compartmental and mechanistic model, simulating "what if" scenarios to investigate whether SGLT2 inhibition will be a good therapy, and then also perform parameter scans. And, lastly, we'll also be estimating parameters to calibrate our model to data.
After that I will briefly show you how you can share models and simulations like the one with the SGLT2 inhibition model using Web Apps. And Web Apps are basically applications in MATLAB and SimBiology that you can share with colleagues through a web browser. Finally, we'll wrap up and there is time for Q&A.
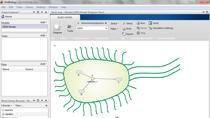
So I first want to give you a brief overview of SimBiology and to whet your appetite for how you could use SimBiology. So here we look at the SimBiology Model Builder app and we have a diagram that represents a mathematical model. And this diagram consists of different parts. So in the top left here you see the pharmacokinetics of the SGLT2 inhibitor. At the top, on the right, you see the glucose uptake mechanism. In the middle you see the plasma and glucose regulation. And at the bottom you see the insulin regulation. And then on the left we have some bookkeeping.
And the idea is that this particular model actually behind-- SimBiology creates a set of differential equations from that diagram. And so here you can see the equations that are derived from that diagram and all the information that we have given to SimBiology. And that allows SimBiology to create a set of differential equations as well as algebraic equations.
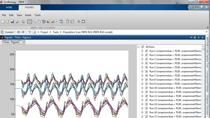
Now, once I have implemented this model, I can also exercise the model. And so I can run simulations and get outcomes like this. So I've just simulated this model both with and without the SGLT2 inhibitor in a reference virtual patient-- a type 2 diabetic virtual patient. And you can see that if there is no therapy, you can see the PK is flat. And if the SGLT2 inhibition is administered, you can see that inhibitor is administered every day.
And then you can see with the dash line, you compare the dashed lines so that the SGLT2 inhibitors with the solid lines where there is no inhibitor administered. You can see that is significant increase in the glucose that's excreted through the urine. However, that doesn't have a very, very significant effect. It lowers the plasma glucose concentrations somewhat, but not below generally acceptable normal levels. So this is how you quickly can investigate whether, in this case, the SGLT2 inhibitor would be a feasible therapy to treat type 2 diabetes diabetes. Now, there's a lot more to that and we will get into that in more detail in the case study.
So SimBiology is used in drug development and I think it's important to understand how the different modeling approaches are being used in drug development and how that coincides with the drug development milestones. So, generally, we can consider there are three major milestones. The discovery phase where identify the drug target. Once we have identified a target, we move to preclinical studies where we try to understand does the drug reach a target and can we find a dose that is a suitable dose for the first in-human studies. So that when we are in the clinical studies where we assess the safety and efficacy of the drug and also define the target population.
And across these different milestones, different types of models are used. So early on you may use a mechanistic systems biology type model to identify drug targets. And then once you move into preclinical and clinical studies, you use pharmacokinetic, pharmacodynamic models and/or physiologically-based pharmacokinetic models. And then, lastly, there is quantitative systems pharmacology that bridge the gap all the way from discovery to earlier clinical studies. And the idea is with quantitative systems pharmacology that they are mechanistic models that include therapies as well as the pathophysiology.
And given that this is the playing field for modeling and simulation in drug development. The idea behind SimBiology is to basically allow users to use SimBiology for all of these milestones and all of these modeling approaches, both for the model building simulation as well as for other advanced workflows like parameter estimation, sensitivity analysis, and-- et cetera. So that's the idea behind SimBiology. Now, you may wonder-- I mean, I've briefly shown you what SimBiology looks like, but maybe we can explain better what SimBiology is.
So SimBiology provides apps. So those are the two apps the Model Builder and the Model Analyzer app that I showed you earlier, as well as programmatic tools. So you can use SimBiology programmatically, if you wish. And that allows you to build your model through the diagram, so you can then build it like you would draw it. Once you've implemented your model, you can simulate it. You can do calibration by estimating parameters. And you can do further analysis, like Monte Carlo simulations or sensitivity analysis.
Now, SimBiology is built on top of MATLAB and you'll probably know MATLAB as a programming language. And this language forms the basis of all of the products that MathWorks has, including SimBiology. And so what we make sure with MATLAB is that all of the products include MATLAB-- including SimBiology are rigorously tested, maintained, and updated every half year to make sure that everything works together.
Now, when you hear of MATLAB, you may also think, well, actually I don't have any programming experience, do I need to know anything about MATLAB in order to use SimBiology? And the answer to that is no. You don't need any programming experience in MATLAB because SimBiology has graphical user interfaces that mean you don't necessarily have to write any code. So you only have to do that if you want to.
Now, SimBiology sits on top of MATLAB and is a toolbox and it allows you to have these app-based as well as programmatic workflows. It has these built-in analysis tools. And then, also, the simulations are accelerated by compiling to C-code. And then in SimBiology, you have projects. So the SimBiology project contain the models that you have developed for a certain therapy that you're, for example, developing. And then any data sets that you may use for parameter estimation-- sorry, for parameter estimation for calibrating your model and then as well as the programs and the analysis that you do with those data sets and models.
And the advantages of these project is that they are a single file that you can open in SimBiology. You can pass it on to a colleague who can open it in SimBiology as well. and it promotes continuity and reproducibility of the results as well as it has a graphical model representation that I showed you earlier. And that graphical model representation is really good at helping you communicate your model to two collaborators.
Now. SimBiology is used across the industry and academia and here are some examples of how users have used SimBiology to-- for their own drug development. So, first off, here is an example from Genentech. The group here wanted to understand better drug-induced myelosuppression, which often leads to drug attrition and cancer therapies. So Wilson et al. at Genentech developed this QSP model of hematopoiesis in vitro. And this model was calibrated using cell kinetics, data, without treatment, and validated against published drug responses. It was then used to predict the magnitude of myelosuppression induced by these novel compounds.
Another example is the model by Klausnitzer et al. at AbbVie, who published a comprehensive model of the molecular mechanisms behind Alzheimer's disease with a particular focus on the dysregulation of cholesterol and sphingolipids. This model captures the modulation of several biomarkers in patients with Alzheimer's disease and pharmacological responses published in literature. It was used to evaluate targeting S1P receptor 5 as well as a novel treatment for Alzheimer's disease.
And, lastly, Sepp et al. at GSK used the ability of SimBiology to build models programmatically to automate the assembly of large two-- over large two-pore PPK model, which was parametrized using an extended tissue distribution time course data set. The automation of the model assembly helped them greatly reduce the time reduced from model building.
So I hope that is giving you some idea of what SimBiology is and where it is being used in the industry. Now, I want to move on to this case study where we investigate SGLT2 inhibition as a therapy for type 2 diabetes.
So consider this hypothetical situation. We are a few years in the past when SGLT2 therapies hadn't been approved yet and my pharmaceutical company is investigating new targets for type 2 diabetes therapies. And SGLT2 is one of those therapies that come up, one of the pathways that may be promising.
The idea behind SGLT2 inhibition is that under normal circumstances your plasma is being filtrated through the renal glomeruli. And this filtrate is then being reabsorbed in the kidneys back into the plasma and so this includes glucose. And the glucose is being reabsorbed back into the plasma among other pathways through the SGLT2 pathway. And if we can inhibit at SGLT2, then perhaps less glucose is going to be reabsorbed and more is going to be excreted through the kidneys, so through the urine, and that would practically decrease the plasma glucose concentration and, thereby, may to some degree mitigate the effects and comorbidities observed with type 2 diabetes.
Now, the research question here is does SGLT2 inhibition result in a meaningful reduction of plasma glucose levels? And in this hypothetical situation, as a modeler, I'm given four weeks to investigate SGLT2 target feasibility. I have no preliminary data and I have to make assumptions on the PK profile of this therapy. However, I can build upon existing models of glucose-insulin regulation. And, again, I have to point out that this model is meant for internal decision-making and not to support regulatory submissions. So it's just to investigate should my company continue work on SGLT2 inhibition.
So the model that I'll be using here is a model by Dalla Man, Camilleri, and Cobelli, who developed a mechanistic model that describes glucose-insulin regulation. And the SGLT2 therapy here that is added to this glucose-insulin regulation was incorporated by our partners Rosa and Co. who are a QSP consulting company. And the goal was to have an illustrative example. So, as I said, this is a hypothetical situation and, of course, it's just to illustrate how you could use SimBiology to create a QSP model and answer certain questions.
So Rosa and Co. they included the SGLT2 effect on the urinary glucose excretion. They included the PK. They described the PK in the model and the other parameters like the IC50. And those values, of course, were assumed because there was no specific PK to go on, at least not in the hypothetical situation. And then they also provided us with two reference virtual patients, one healthy and one Type 2 diabetic patient. And the idea here is that Rosa and Co. qualified these two virtual patients against observed clinical data to make sure that these patients were indeed representative of a healthy subject and a Type 2 diabetic patient.
Now, there are some assumptions and limitations. First of all, the Dalla Man et al does adequately represent glucose-insulin regulation, but only for short-term regulation on the order of days, so not for any long term effects that you would see with HbA1c or something. That's not included in this model. So we can just really use this for short-term-- to investigate short term effects.
So let's move to SimBiology and start working with this model. So in order to start SimBiology you can start in MATLAB. So here you see MATLAB, we have the Home tab, and then there are the Apps tab, and SimBiology, the Model Builder, and a Model Analyzer apps can be found in the Apps tab.
So if I open the SimBiology Model Analyzer, you see the model that I showed you earlier. But today I'm going to be using the-- basically the Dalla Man paper that was-- where there is no SGLT2 therapy yet. So what I'm going to have to do is I'm going to have to include the SGLT2 therapy here and then link that to that renal excretion rate. So those are my next steps, basically.
Now, the easiest way that we can incorporate that PK part-- in this case, the PK part is going to be a one compartment model. And the easiest way to incorporate that is by using the PK library from SimBiology. So you can load a model from the PK library and you can see there are one-, two-, three-compartment models with different types of dosing and elimination. And, in this case, we're going to use a one-compartment model that we assume that the therapy is oral, so it is first-order dosing, and then we have linear elimination rate and volume. So I just select this, and then click OK, and that will give me my one-compartment model. And now I can investigate that model.
So, for example, if I click on central, that is the single compartment central, I can see that that compartment has a value with 1 liter. And for our therapy, that has to be 6 liters. We're going to have to set that to 6 liters. I can also look at the absorption rate. So dose is being absorbed into drug central at a rate ka and I can give that a value as well. So, in this case, it is 0.03 and the unit is 1 over minute. And then I can do the same for the elimination rate, so ke is going to be 0.003, and it is in 1 over minute.
So now we've defined this one-compartment model, I can quickly have a look at the equations. So for the dose central-- so the change in dose central equals negative the central absorption. And the change in drug central is positive, the absorption, and negative, the elimination. And so what you can see in blue here are the species. Those represents the blue oblong shapes here and those are the left hand side of the differential equation. And then in orange here you see the reactions or the fluxes. Here you see the fluxes. These are the reactions, and those represents the term in-- the terms in the right hand side of the differential equation.
So now what I can simply do is I can copy this. There is one thing you need to make sure, if you go to the copy options, that you set when copying-- you set all of these to true, basically, and that will make sure that it copies the entire thing over. So I'm going to select all of these parts here and I'm going to hit copy. And then I'm moving to the other model and I'm going to paste it in there. So here I can just say paste and now I have my model in the other-- I have my one-compartment model added to my Dalla Man model. And you can see that it also includes the parameters for ka and ke.
So it's all nice and fine that I have my pharmacokinetics now included, but this model is not yet linked to the plasma glucose regulation. And I have to do that by linking, basically, the drug concentration to the rate of renal excretion. And so if I click on this reaction again this reaction is determine the right hand side for this plasma glucose.
This plasma glucose is a species. If I click on renal excretion, you can see the reaction rate. And how this reaction rate is defined is, basically, if the plasma glucose is higher than a certain basal renal threshold, then there is going to be glucose excretion. And that glucose excretion equals the glomerular filtration rate times the gradient in the concentration between the plasma glucose and that basal renal threshold.
And I've added here a drug effect term. This drug effect term is currently just 1. And so what I'm going to do is I'm going to define that drug effect to be dependent on my drug central and that way I can link drug central to my renal excretion.
So in SimBiology the way that you do that is you use a repeat-- repeated assignment. And repeated assignments are basically algebraic equations. And so here you see the table for the repeated assignments. And I can simply just write a new repeated assignment for drug effect.
So I'm going to say drug effect equals 1 minus Imax times [? central.drugcentral. ?] And in this case, the Hill coefficient is 2. And then we divide that by IC50 squared minus central [? dot. ?] And then you can also see I hit the Tab button here and then I can autocomplete this. And, again, we need to square this. And then I'm done.
Now, I've done this and it's-- I've got Imax here as being red and I get a red indicator. And this is SimBiology telling me, hey, something is wrong. And I can go here to the model assessment tools, I can verify my model. And when I verify that, it says we found an error and this error is that Imax does not refer to any species parameters or compartments, so basically Imax is not defined.
So that's what I still have to do. And I can go to the parameter table here and ad Imax. So what I just do as I say Imax is a parameter, the value is 0.65, and the unit is dimensionless. And now if I verify my model, there are no errors or warnings in the model.
So I have linked the PK with the PD now, but it's a little bit-- it's not visible in the diagram yet. So that's one thing I still want to do. So I have my drug effect here and what I can now do is I can go to my renal excretion reaction, I can say show expression lines, and then you get a dash dotted line to that drug effect. And then I can do the same for this repeated assignment and show the reaction lines. And so now I can see this drug effect ties together the drug central concentration with the rate of real excretion.
So that concludes the model building part of this case study. We can now have a look at the equations. Again, we can choose to embed on the fluxes, but here you nicely see that each flux has a different name. So there's a grinding, emptying, insulin secretion, et cetera. And then you can have a look at the ODEs, where you see all of those fluxes, for example, for plasma glucose.
There are two other things that I haven't shown you yet in SimBiology and that are going to be very helpful later on. The first one is doses. So in SimBiology you can define doses. And, in this case, we have doses defined for meals, so a breakfast, a lunch, and an evening meal, as well as for the SGLT2 inhibitor.
And so for the SGLT2 inhibitor, we dose 300 milligrams, start time 60, so 1 hour. And then the interval is 1,440, which is one day, and we repeat that seven times. And so SimBiology doses you can mix and match. You can have multiple applied at the same time and they allow you to quickly explore different dosing regimes.
The other thing that is interesting and we call-- so the doses we call a modifier, it modifies your simulation results. The other modifier are variants. And variants the idea is your model structure and your differential equations may be the same, but the model can describe different types of, for example-- different phenotypes, different species, different drug effects, and so you can catch those in a variant. Because what variants are are different parameterizations of your model.
So, in this case, a Type 2 diabetic patient may have a different GFR than a healthy patient because Type 2 diabetes have reduced kidney function. And so that's the idea that these two virtual reference patients are each saved in a variant that we can apply those model-- those values to the model to simulate and represent either a healthy patient or a Type 2 diabetic patient-- a healthy person or a Type 2 diabetic patient.
So those are the variants we are now going to use when we simulate the model. And, so far, we've worked in the SimBiology Model Builder and now I'm going to move to the other app, the Model Analyzer, to do the simulations.
So here we saw the simulation from earlier. I'm going to create my own simulation and I-- a simulation is called a program. So there are multiple types of program and simulation is one of those programs.
So this program I can rename. I can say this is a single simulation. And now I can go through this step by step and see what it is that I want to-- what I want to simulate. So the model that I want to simulate is the Physiopedia platform [? webinar ?] [? empty. ?] That's the one that we've just been working on in the Model Builder, yeah, Physiopedia [? webinar ?] [? empty. ?]
And then I can apply variants. In this case, I'm going to apply the Type 2 diabetic patient and doses. So, in this case, I'm going to apply just the meals, but not yet the inhibitor, just to see what a baseline Type 2 diabetic patient response looks like.
I can also define what states in the models, so what species I want to log. And, in this case, I just want to log these four species. And I want to stop the simulation after 10,080 minutes, which is 7 days. So let's run this simulation and here we have our plot.
So we see the four responses. They each have a different color and that's because they're sliced by color. The slicing here, has the responses. Now, because the values for the yellow response for the plasma glucose concentration, AUC, are so high that I can't see other. So what I can actually do is I can plot them instead on a grid.
And if I do that, I can see each response individually in its own graph. And then I can have a look at what the baseline is for the urinary glucose excretion. So you can see that at baseline-- so without SGLT2 inhibition there seems to be some reasonable amount of AUC-- of glucose excretion through the kidneys already. We can really see that the plasma glucose concentration is considered high. Anything above 180-- I think, generally, 180 milligrams per deciliter is considered high glucose levels. And this patient definitely shows high glucose levels.
And at the bottom right here you see the central drug concentration, which is just flat. There is no drug being administered yet. But now what I can do is I can add that drug and I can keep the results from the simulation without the drug and then I can compare the two. So let's do that. We add the drug and then run the simulation again.
Now we can see is that once we include the SGLT2 inhibitor that, in red, you see the diabetic virtual patient with the inhibitor and, in blue, you see it without the inhibitor. You see there is a significant increase, about a doubling of the urinary glucose excretion, and a, not very large, but a small decrease in plasma glucose levels. And you can also, of course, see that the SGLT2 inhibitor is now being administered.
Now, we see here is that there is a small effect, but, of course, there are certain factors that effect the size of the inhibitor-- of the effect of the inhibitory and one of those is the GFR.
So if we go back to the diagram, we can have a look at the drug of-- the renal excretion and if we look at the renal excretion, then you can see that the GFR basically limits the total effect that the drug can have. So what will be interesting to see what happens if we were to increase the GFR. Do we then see a larger effect? So we can go back to the Model Analyzer and we can actually investigate the value of that GFR.
So here's GFR. And I can create a slider for GFR and see what happens, for example, if I change that value to 0.01 instead of [? 0.0-- ?] [? or ?] [? 05. ?] So now I can simulate the model again with that new value for the GFR. And then you'll see that the drug effect will increase even further than it did without that value at GFR.
Now, of course, the GFR is not something you can engineer. That's the property of the patient. But it's important to understand that if the patient has a very poor GFR, then perhaps this therapy won't work so well.
The other thing that we can-- that we have an influence on is things like the IC50 and the elimination rate of the drug and the absorption of the drug. So perhaps what we can do is we can now explore those factors. And the way that we do that, we can scan across those parameters and see what the effect is on the maximum amount of glucose that's being excreted.
So I can add a copy of this program to my project and let's call it Explore IC50 and ke. So this is the same program, but now you see there is a plus here and that plus allows you to add steps to your simulation program. That one of those steps is to generate sample step and what that does is it generates samples from parameter values or initial conditions and it stimulates your model with those alternate values-- those sampled values.
So what I was interested in is IC50 and ke so I can drag IC50 over as a component and the same I can do for ke. So, in this case, I'm scanning-- I'm generating samples for quantity but it can also be a dose or variant that I want to explore. So say I want to simulate my model with each of the different variants that I have, I could do that this way.
Now, here I'm going to use user-defined values, but you can also sample values from a distribution like a random sampling from the normal distribution, for example. I'm going to use a range of values that is linearly space between 10 and 190 and I'm taking five samples. And then ke, I'm going to do something similar, a linear sampling between 0.001 and 0.01, also in five samples.
And now what I'm going to do is I'm going to do a Cartesian parameter combination. So I'm going to I'm going to simulate the model for each value of this combined with each value of that, so I'm going to have 25 different samples.
And the idea behind these steps is that you can run them separately, you can display any plots or [? not-- ?] I'm not going to display plots, but I am going to generate the samples-- and that the output from one step forms the input for the next step. So I can run this simulation now that I've generated the samples. And now it's going to simulate the model for each of those 25 samples and I'm omitting the plots at this point.
But what I have selected is these observable-- and observable is constructing SimBiology that allows you to calculate something after your simulation is done. So as a global measure of your goal outcome measure. And so, in this case, I'm taking the maximum value of the urinary AUC and that is going to be the output that I want to compare for each of those samples.
So here is my program and I can actually look at the results from that last run. So these are the samples that, again, we generated. Those-- when generate samples, these are my samples. But then I can also look at the scalars. And the scalars are this-- is this max urinary AUC you see here, because this results in a single value for each simulation and I can visualize those with plot matrix.
So I select scalars, select plot matrix, and then I get my result here. So here you see basically those dots that represents the different samples that we took and you see the max urinary AUC see for all of those 25 samples. So, in this case, it's rather obvious that if we have a low IC50 and a low ke that we're going to see the highest effect of our therapy just because, in that case, the effect that the drug has is highest as well as the drug AUC is highest, if we have a low ke.
But, in your case, you might be looking at a combination therapy or a therapy where there is not-- where there may be a sweet spot and performing these kind of scans can really help. So say that my company was somewhat interested in exploring this therapy further, and started developing a compound, and we now have some data. So what I can now do is I can say, well, it's a year later, I still have this model, we have the data, let's see if we can calibrate the model to that data.
And, in this case, I can load that data from file, so it's an Excel sheet, and it's really only the PK data, so you see the concentration and the dose. I don't have any data on the PD at this point. But of course, I could have PD data as well. And now the idea is that we end up defining what are dependent and independent variables. I can add units if I wanted to.
And SimBiology, again, can make sure that the units between your model and your data are consistent such that you don't make any order of magnitude mistakes. So we have our data, but, of course, we still don't know whether that data is at all representative of one-compartment model-- whether a one-compartment model will fit this data well.
So let's visualize the data first. If I just click here on calibration data and select a time plot, we get a plot for that data. And if we plotted on a semilogy scale you can see that there is a clear linear elimination and some absorption phase as well. So it would be appropriate to fit a one-compartment model to this data.
So that's exactly what we're going to do now. We are going to create a program called fit data to fit our model to that data. So I select my data set and then I also select my model. I'm just going to use that one-compartment model.
And then the next step we need to do is we need to map the columns in our data set. Remember, these are the four column names in our data set to parts in our model. So the ID column represents the group. So there are nine subjects in our data set. You can see that here.
And the time is independent variable and then the concentration is our dependent variable. And that represents [? central.drugcentral. ?] Central. And the dose represents the target, so that goes to dose central because this is an oral dose. So this will allow SimBiology to create the objective function for you and then the only thing we need to do is we need to define what parameter we want to estimate and what kind of estimation algorithm we want to use.
Now, in this case, I'm going to be using nonlinear regression, so fixed effects, but you can use mixed effects and mixed effects with stochastic solver as well. For these two, you will need the statistics and machine learning toolbox. And then I'm going to do a pooled fit with a proportional error model.
And I'm going to use lsqnonlin, which is part of the optimization toolbox. And lsqnonlin is at least squares local optimization algorithm. I could also use global solvers, global optimization algorithms, such as scatter search or particle swarm, but this problem is so straightforward that there's no point in doing that. So we'll just use lsqnonlin.
And, lastly, again, here you see that plus-- I can also add other steps to this and one of those steps is confidence intervals. And so I'm going to calculate confidence intervals for this particular-- for the parameter estimates that I'm doing, but also for the prediction for the predictions.
So I'm going to run this. You see there is a button here for parallel as well. If you, for example, were to do confidence intervals with Bootstrap, that's something that parallelizes very well. Or if you do global optimization, you can also parallelize that. And so it's very easy to speed up these processes with just the click of that button on your machine.
Now, here what you see is the progress plot as we progress through the iterations of the optimization. So we did seven iterations and you see the value of the log likelihood here, which we want to maximize, the first order optimality, which we want to minimize, and you see how the values of each of the parameters var-- change from their initial estimates that we gave to their final estimates. So now we have a set of parameter of diagnostic plots.
We can look at the fit plot and we see that, obviously, this is a pulled fit so there's only one simulation that needs to fit through all of the points and that seems like a reasonable fit. I can look at the observed versus predicted where we would ideally like-- if our model was perfect, all of these points would lie along the line-- the unity line here, but this looks pretty good already. The residuals versus time where we just want to make sure that the residuals are equally distributed across this 0 here because, otherwise, you might have-- here we maybe-- early on in time we may be underestimating-- or, yeah, underestimating the true value.
We can look at the residuals-- the distribution of the residuals where this red line basically represents a normal distribution. So if the points lie along that line, then you can assume that your points-- your residuals are approximately normally distributed. And then we can also look at the confidence interval, so this is a confidence intervals on each of the different parameters. And these are Gaussian confidence intervals, so post hoc. This is not a Bootstrap or profile likelihood confidence interval. But still it looks like we have a reasonable amount of confidence in each of these parameters.
And the same we can do for the predictions. You can see that the predictions here are-- this is basically with 95% confidence. Given this data and this model, the model response will be within the blue region.
As I said, currently we're only we're only estimating PK parameters. But, of course, if you had a PD response in your data set, you could also estimate PD parts parameters in your model. So that concludes this case study. So let's go back to the slides and just wrap it up.
So the model here supported the feasibility of SGLT2 inhibition. It was not a knockout therapy. It clearly seemed to work only for higher values of GFR. So that's something you may need to take into account for your patient population. And we could design the compound in such a way that we have the most effect of the compound.
Now, the limitation here was that the model does not capture full population response or the longer term homeostasis. And, as a result, it was really only to inform those early development decisions. So I hope this example is giving you an idea of how to implement models in SimBiology as well as how to then use that model to answer questions that you have and calibrate your model to data.
Now moving on to the next part, say, you want to share your model and the simulation capabilities as-- with your colleagues. And those colleagues may be non-modelers, they might be biologists, but they want to play around with your model. How do you do that? Well, you can use web apps for those.
And the easiest way to show you what a web app is to actually show a web app to you. So this is a web app. So you can see I'm in my browser and this address here is a server that is within MathWorks's VPN. So it's only on the internet, it's not accessible by anyone outside of MathWorks.
And the server is-- I'm connected to it through VPN, server's located in Munich. And the only thing I need is a link to this, and that I can log in, and then I can play around with this model. So I can see what the effect is of increasing Imax or what the effect is of decreasing IC50 and increasing the glomerular filtration rate.
And so that way, I can systematically explore this model, I can get a feel for what are the important parameters, and you as a model are you can decide you, of course, what slider's you want to include, what plot you want to include, and all of that. So this is a really good way to share your model and the findings with your team.
So, briefly-- so you would be the person who creates these apps and you then convey that-- you share those apps with those model users. And the idea is you use-- in MATLAB, you use App Designer, so you need to be somewhat comfortable with writing code. Then you can create those apps, package them up, put them on a server, and then you get a link basically out of that you can share with your colleagues.
Now, there is a lot more to this. And we can talk about that in more detail, but, needless to say, this allows you to stay within the larger environment and really easily share your results with your colleagues. You will need the MATLAB compiler, as you see here, to create those packages and those-- and share those apps through as web apps.
Let's wrap up. Now, there are a few things that I haven't been I haven't had a chance to talk about. One of them is local and global sensitivity analysis. We can use sensitivity analysis to find potential drug targets, to find important parameters for certain model outcome, and also identify which parameters you should be estimating and which parameters you may be able to use to fix because the model is not sensitive to them.
So SimBiology supports both local sensitivity analysis as well as global sensitivity analysis. And for the global sensitivity analysis we support two methods currently, the Sobol global sensitivity analysis as well as multiparametric global sensitivity analysis. There is a webinar on this topic that you can find on our website and that goes into much detail on this topic.
The other thing I alluded to was that you can use SimBiology both in an app as well as programmatically, so we can have a brief look at that. So, say, a typical simulation program, we can have equivalent code for that program.
So we could load our project and select our model from our project, then find from this model-- find one of the doses that's called "50 nanomole daily," then set the stop time to be three days, and then simulate our model with those settings and the dose. And, lastly, we plot the simulation data and we get a plot like that. So that's to say that you can use anything-- you can do anything programmatically that you can do in the user interface.
Lastly, we have an active community of SimBiology users. One example here is the group at Genentech that developed gQSPSim, which is a SimBiology-based graphical user interface of an app for standardized QSP model development application. And it is designed to provide the means for transparent, reproducible, and portable QSP modeling by extending the capabilities of SimBiology and, in particular, for interactive visualization and the statistical calibration of virtual subjects.
So if you want to know more about this, you can have a look at the gQSPSim manuscript that is available online. And this app is available for free to download. Of course, it does depend on you having SimBiology.
Other examples of SimBiology used modeling frameworks are Bristol Myers Squibb's QSP toolbox, which has-- which is meant to standardize critical aspects of the QSP workflow and that includes data integration, more calibration, and variability exploration, as well as to calibrate virtual populations.
Vantage developed VQMtools. And Vantage is another consulting company and they-- the VQMtools focuses on the creation and evaluation of the virtual population based-- that is based on reference subjects and the definition of model constraints.
And then lastly, the group from Aleksander Popel at Johns Hopkins University have developed a SimBiology-based platform for QSP modeling in immuno-oncology that allows for the construction of QSP models within IO with varying degrees of complexity based upon the research question at hand.
And that brings us to our community. We have a community page. If you just search for SimBiology Community, you will find it. It contains links to those contributions that I just talked about. It contains an answers-- question and answer section as well as tutorial-- a link to tutorial videos for SimBiology on how to build models, how to simulate, how to do parameter estimation, et cetera, and non-compartmental analysis. And so this is a useful resource and you can also-- you can ask questions that we will answer as soon as we can.
So to wrap up, what is SimBiology? SimBiology provides apps as well as programmatic tools to build a model by drawing it, to simulate that model, and investigate "what if" scenarios, to estimate parameters, to calibrate your model to that data that you may have or multiple data sets that you may have, and also perform analysis like that global sensitivity analysis or Monte Carlo simulations. So with that, I will wrap up and I would like to thank you for your attention.
Related Products
Learn More
Featured Product