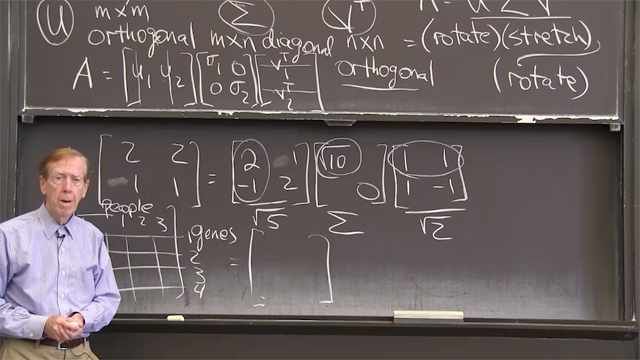I have given this talk to several student chapters of SIAM this fall. Here is a recording of the talk at Oregon State. I want to talk about the singular value decomposition. I'm a big fan of the SVD, and this is about saving the universe, will become clear in a moment or two. When I first encountered the singular value good decomposition, I was a graduate student at Stanford, working with George Forsythe.
Forsythe had started the Computer Science Department, and I was a math graduate student and an instructor in computer science. We wrote this book, and in this book, the SVD is just theoretical. We didn't know how to compute it, and it's just there as a way of characterizing the norm of a matrix. Forsythe, then one day at a seminar, says, why doesn't somebody figure out how to compute the darn thing? And Gene Golub did that. Shortly after I left Stanford, Golub, together with Velvel Kahan at Berkeley, developed an algorithm for computing the SVD.
A few years later, Christian Reinsch in Munich wrote ALGOL programs for their algorithm. Golub is famous for many, many things, but he was perhaps best known and proudest of his singular value decomposition. And he sported this California license plate. In 1970s, I was a professor at the University of New Mexico in Albuquerque, and I spent one day a week at Los Alamos, a consultant working on their math libraries.
I made a film at Los Alamos, actual 16 millimeter celluloid film. If I had a live audience, I'd ask how many of you have ever seen celluloid film, a real film. The two purposes for the film-- one was to promote the SVD, which was then only a few years old, at least the ways to compute it. And the other was to promote the Los Alamos graphics library. Now, you're going to see some pretty crude graphics of what I'm about to show you. In 1976, this was really state of the art. Putting Greek letters on the screen was even hard to do. And we're going to have 3D hidden lines.
The whole film is about six minutes long. I only have part of it here to show you.
[VIDEO PLAYBACK]
[MUSIC PLAYING]
- The computer is used to simplify the matrix, so that most of the entries will be zeros. One method is known as the singular value decomposition. The original matrix is represented as the product of three matrices. In the second of these matrices, the only non-zero elements lie on the diagonal. The other two matrices must preserve the properties of the original matrix. So they are orthogonal matrices. Each is the product of elementary matrices, which affect only two rows or columns.
Scientists at Los Alamos Scientific Laboratory have been studying methods for the accurate and efficient calculation of the singular value decomposition, and are describing to computer users how the computation is carried out. In this three dimensional representation of a small matrix, each pyramid depicts the magnitude of a single matrix element. The diagonal of the matrix runs from the upper left to the lower right.
Orthogonal transformations will be used to introduce zeros into the matrix. The initial transformations put zeros into the first row, and then the first column. Each transformation affects two other columns or rows shown here in blue. Later transformations introduce zeros into later rows and columns, while preserving the zeros already obtained.
The second stage of the calculation is a repetitive or iterative process, which reduces the size of the remaining off diagonal elements, but does not zero them in a single step. The calculations now being shown are primarily intended to reduce the size of the off diagonal element at the lower right-hand corner. Once an off diagonal element has reached a negligible magnitude, it is set to zero.
The computation of the corresponding diagonal element is then complete, and the resulting singular value is shown in blue. The final diagonal matrix, together with the two transforming matrices which produced it, then provide the bases for a complete analysis of the original matrix, and the system which it models.
[END PLAYBACK]
So there you see Golub's algorithm in action, in animation. The whole film is six minutes long, and if you want to see it, go to Google, Moler SVD, and you'll be redirected to this YouTube link, which you can see the whole film. That was not done with MATLAB. MATLAB couldn't do these kind of things at that time. But here's an animation, here's a recreation of that in MATLAB today.
About the time I've finished the film, producers from Paramount Pictures came to Los Alamos. They were seeking graphics to use on the scopes of the bridge of the Enterprise in the first Star Trek movie, called Star Trek, The Motion Picture. A force called V'Ger was threatening the universe, and in the opening scene, you're going to see a vast universe, a nebula. And there's just a small dot moving across the picture, that's the Enterprise.
But then, look over Spock's shoulder.
[VIDEO PLAYBACK]
[MUSIC PLAYING]
- You can adjust enough for us to break free.
- Break free to where, Commander?
- And he showed resistance would be futile, Captain.
[END PLAYBACK]
The singular value decomposition is playing on Spock scope throughout the movie, and I'm not sure what exactly role it played in actually saving the universe, but I like to think it did. I was working on MATLAB the first MATLAB. When the first MATLAB came out a few years later, the singular value decomposition was one of the functions in MATLAB. This is all the functions in the first MATLAB. It was just a calculator. It wasn't yet a programming language.
So what is the SVD? You get it in today's MATLAB. This is called the economy-sized decomposition. So you can take matrix, and express it as the product of three matrices. Two of the matrices are orthogonal-- they have orthogonal columns. And the middle matrix is diagonal. So any matrix can be written in this form. That's the SVD. In the two by two case, you have an arbitrary matrix. Here on the left, there are four values in the matrix.
And then the two orthogonal matrices are, as we saw in the film, rotations. There is a single angle for each. And then there is two singular values. So there's four unknowns on the right, just enough to match the left. And that counting argument continues for larger matrices.
If A is a transformation taking a domain into a range, it can express it as the product of these three transformations. One is a change of basis in the domain. The other is a change of basis in the range. And then those new basis, the transformation becomes diagonal and easier to understand, easy to understand.
Let's look at this example. Here's a eight by eight matrix. It looks like just random integers at first, until you realize that they are the numbers from one to eight squared-- from one to 64-- arranged in such a pattern that when you compute the sums of all the rows, compute the sums of all the columns, compute the sum of the two diagonals, you get the same number each time. That's why it's called a magic square.
So why is the sum 260? Well, that's what it has to be, if you add the numbers from one to 64, and then to distribute that sum over eight columns. If I compute the singular values of that matrix, here are the singular values. Well, look at the first one. It's 260. Why is the first singular value 260?
That's your homework for today, if I were assigning homework. Show the largest singular value of any magic square is the magic sum. There are two other singular values, and then there are five that are just on the order of round-off error, 10 to the minus 14 to 15. So only the first three are significant. If I draw a plot of the singular values, here are the first three, and the last five are zero. We're going to see more plots like this as we go along, where the singular values fall off rapidly. Here, there's only eight of them, but later, we're going to have bigger ones.
So the rank of this matrix is three. I'll talk more about the rank in a minute. If you take the first three columns of U-- here's just three columns of U-- take the singular values and put them in a three by three diagonal matrix, and take the first three columns of V. Then U times S times V transpose is-- it prints it like this. They're integers. They're within round-off error of integers. And so when I actually round that product, I get back my original matrix. So my eight by eight magic square can be written just in terms of three singular values.
There's another related decomposition, which we'll hear a lot about called the principal component analysis, PCA. This comes out of statistics. If you have-- say you have gathered data about how people's height varies with weight, you can change the coordinate system, center it in the data, and then have orthogonal components that explain the data. The first one, the black one, is the first principal component and explains the largest part of the data, and so on.
Now, the SVD and PCA are related, but in 2006, as recently as that, I wrote this in our newsletter. The Wikipedia pages on SVD and PCA are both very good, although they don't relate to each other. And within two days, Wikipedia was updated so that the two pointed to each other. If you didn't have the PCA-- if you didn't have the SVD, here's how you'd compute the PCA.
This is a MATLAB function, which computes these quantities called the latent roots, the coefficients in the score, which have statistical meanings. We take your data x, and you subtract the mean. You compute the mean of each column and subtract the mean of each column from the column. So each of the columns then have average zero. And then you compute x prime times x. If x is 10,000 by 10, if you have 10,000 observations of 10 variables, then prime times x is just 10 by 10. You squish all the data down into the covariance matrix.
And then you compute its eigenvalues. And from the eigenvalues and eigenvectors of the covariance matrix, you get the principal components. Now, if you're just interested in the largest principal values, then this is fine. It's a good way to do it. But there's a way to do it. But we're going to see-- there's a reason to be interested in the small ones-- in this forming x prime times x actually destroys the small singular values.
So if you were going to compute the principal component analysis from the singular value decomposition, here's how you'd do it. You'd still center the data. You still subtract the mean of each column from each column from a column, and then you compute the economy-sized SVD that we saw earlier. And then you can read off the statistical quantities easily from the SVD. And this is accurate even for the small singular values, as well as the large ones.
So to summarize, the SVD had its origins in my world and the world of numerical analysis and matrix computation. It works with the original data, and it's more reliable numerically. The PCA came out of statistics. You always center the data before you do anything else. And then you compute the eigenvalues of covariance matrix. And as I said, you lose the small ones that way.
Here's a short course in linear algebra. This is a picture that Gil Strang of MIT likes to do. It's on the cover of his books. We have a transformation that takes n-dimensional space into m-dimensional space. In the domain, there are two orthogonal subspaces called the row space and the null space. In the domain, there are two other subspaces called the column space and the left null space. And the whole transformation can be explained by their action on these four subspaces.
Now, Strang's drawing here is not quite accurate, not quite right. The width of this rectangle ought to be the width of that rectangle because a fundamental theorem in linear algebra is that the dimension of the row space equals the dimension of the column space. The number of independent rows is equal to the number of independent columns. That's actually a subtle fact and requires some proof, but this common dimension is called the rank of the matrix.
Here's how MATLAB computes the rank of a matrix. This is a working MATLAB function. You compute the singular values of A, and then you count the number of them that are bigger than some tolerance. Official, exact definition, I believe the number is greater than zero, but with round-off errors, we have to have a tolerance that's a little bit bigger than zero.
And in terms of the SVD, here are strings for some fundamental spaces. The first, if r is the rank, then the first r, columns of u and v, are the row space. And the column space and the rest of the columns of U and V are the two null spaces. For this, you need the full singular value, not the economy size-- full SVD, not the economy size. There's your course in linear algebra.
Another way to write this is to say that the matrix A, if U sigma, V transpose is the SVD, and we order the singular values in decreasing order, they're all positive. And we form these quantity-- these matrices-- Ek by taking the outer product of the case column of U and the case column of V to another side. If you would take the inner product, the dot product-- that's the usual way of multiplying vectors-- but these are multiplied in the wrong order.
So you get a matrix is the product of two vectors. Each of these matrices have rank one. And if you form this sum, weighted sum, the E's, and stop at any number, r-- it doesn't have to be the rank-- then these inequalities are true. The norm, the two norm of the difference you get by approximating A by A sub r is bounded by the first term you left off-- is less than the first singular value ignored.
And Frobenius norm, if you're familiar with that, is the square root of the sum of the squares of all the singular values you ignored. This is called the Eckart Young theorem, and it shows why we get away with approximating a large matrix A by a matrix with fewer columns-- no, the same number of columns, but with a smaller rank-- if the singular values drop off rapidly. Here's a cartoon, a picture of what's going on. You have your general matrix, A. Doesn't have to be square. And you write it as the product of these-- as the sum of these rank one matrices.
Now, a traditional way of showing that is using a image, image decomposition. Here's a color JPEG of Gene Golub. This has a little over 1,000 rows and 688 columns for this JPEG. Now if I take the red, green, and blue components and put them side by side, I get a matrix that has 1,000 rows and 2,000 columns. And if I form those rank approximations, here they are. I'm going to go up to 50. And you see the rank up at the top.
By the time we get to 50, we can read the mathematics on the blackboard and see the checkered-- see that Gene's wearing a checkered shirt. Here I'm going to do it again. Watch, we'll get to 50, and then we'll show the complete matrix, which has rank of 1,000. There's the rank of 1,000. And you can't see the difference.
Here's why. Here's a log plot. This is a logarithmic scale on the left here of the singular values of that grayscale matrix we were just looking at. The largest singular value is 2.3 times 10 to the fifth. By the time we get to 50, rank 50, we're down over two orders of magnitude. So we get an approximation that's accurate to 2-norm, to better than 1%, if we truncate to SVD-- if we truncate at rank 50. And that happens lots of times. We'll see more examples of that.
A lot of talk about politics today, control of the United States Senate. Here's the control of the Senate over the last 30 years between the Democrats and the Republicans. Each of these bars is two years because there's a two-year term in the Senate. So you go to this website at the Senate.gov, and you get the roll call votes. You can download data that every vote taken with roll call in the Senate is recorded there.
Now, I'm going to make up a bunch of matrices, one for each session. They're mostly plus and minus ones, plus for yes, and minus one for no. Or plus for guilty, and minus one for not guilty in certain votes. There are also zeros in this matrix, if a Senator is missing, or chooses to abstain. So the number of rows in this matrix is 100 because there are 100 senators. And the number of columns varies from session to session, from anywhere from a few hundred to several hundred, depending how many votes were taken during that session.
Now, I'm going to show you pictures of those matrices. Starting in 1989, here is every year. As the year increases, you begin to see that the matrices show-- they're complicated, but they're showing less and less detail. They're becoming more and more just yellow and blue. Here we go back again, lots of variation. And now, as the years increase, there's more votes that are just along party lines.
So I'm going to measure partisanship in the Senate by-- let's look at two years. So this is the most varied year, 1991. And you see all the votes that are not along strict party lines. And then in 2014, there were very few such votes. And those are the two extremes over this time period. I want to consider a third matrix, and that's a coin flip, where they don't vote on party lines at all. They just flip a coin to vote.
And here's the singular values of those three matrices. The coin flip matrix, the singular values don't decrease very rapidly at all. The actual vote, roll call vote matrices, they drop off very rapidly. And by the third singular-- so here's the first. I've normalized them by dividing by the first singular value. Here's the second singular value. And here's the third one. So if I just truncate here, just use the first two, then I get an accuracy of better than 60% in 1991, and over 80% in 2014.
So I'll just take the first two singular values, and I'll define partisanship by the fraction that I missed by the first two. And so that's one minus the third singular value over the first singular value. That's partisanship. Here is a plot of partisanship over the last 30 years, and a straight line fit to the data. Now, usually data that's varying this much, you don't attach much meaning to the actual coefficients in the straight line fit. But it's certainly true that there's more-- the Senate is more partisan now than it was in 1989.
OK, here's an example that I like to show. This is the work on the human gait by Nikolaus Trode, who was a professor in Germany, and is now a professor in Canada. If you're interested in what you're about to see, you can go to the biomotion lab website. Trode is interested in the human gait, how people walk. And in particular, how we as humans can tell things about other humans if we watch how they walk.
We can tell maybe how old they are, what sex they are, whether they're happy or sad. He took 60 some-odd of his graduate students, put markers on them, and followed the motion-- followed the motion with those cameras in the background, recorded the movement of those markers as they walked on the treadmill.
It would take a couple of thousand frames for 10 or 20 seconds of the students walking. There are 15 markers moving in three dimensions, so that means there are 45 functions of time-- 3 times 15-- that he records for the motion. So the raw data is a matrix with 45 rows and a couple of thousand columns. Gets one matrix for each subject.
The data looks like this. Here's some of the data recorded over-- in this case, 1600 frames. You zoom in on it, and it looks like this. It's roughly periodic because that's what walking is. But it's far from exactly periodic. So Trode makes a reduced order model. He's going to approximate his data with just five terms. There is a nonlinear parameter omega, which determines the Fourier analysis. And then everything else is linear.
This is five terms in a Fourier series, a constant, cosine and sine of omega t, and cosine of sine and two omega t. And the five vectors-- the five coefficients, v 1, 2, 3, 5, are vectors. They're obtained as the first five components out of the SVD. So his data is reduced from 45 by a couple of thousand, down to 45 by five, a big reduction in the amount of data. That describes about 90, 95% of the motion.
But he goes a step further. We're going to combine all the data and do an eigenwalker. Eigen is the-- we borrow from the German, means characteristic or typical. So he's going to get every man. He takes all his females and does an SVD for the females, another SVD for the males. And then the average of those two is the eigenwalker. And the gender, now, isn't one of the first five components-- little bit more subtle than that. But he gets the gender by taking the difference of these two matrices.
So let's start up MATLAB now. Going to run MATLAB live. And we will start up the walkers demo. Here's the first six walkers. This is not the raw data. This is what comes out of the reduced order model with the five components. They're arranged alphabetically. We can skip through them. Look at Jamie, down on the right hand corner here. Now, Jamie's sad. How do we know Jamie's sad? He's walking slowly, his head's bent down. This is what Trode is interested in. How do we, as human beings, recognize traits in other human beings by the way they walk?
Let me skip forward here to my two favorites. Down in the lower left-hand corner are Pablo and Patricia. Next to each other alphabetically, but with very different walks. We'll get back to those two in a moment. Let's go to the eigenwalker. So here he is. This is the synthesis of all that data all those singular value decompositions. This is the five component model of the typical walker. I can click on these sliders down at the bottom and isolate the single components.
If I just click on v1, this is v1-- it's static, there's no cosine omega term here-- the one determines the position of the 15 points in three-dimensional space. If I activate v2, I get this striding motion. This is the primary component-- well, the second principal component-- of the eigenwalker. And v3 is a swaying back and forth at the same frequency. If I go to v4, this is twice the frequency. This is two omega d. And here, the hands are in phase with the feet, and here is that jumping motion with the hands out of phase with the feet.
So those five components, then, make up the typical walker. Now, as I said, gender was not one of the five principal components. It's more subtle than that. But I have a slider here that goes gendered-- goes back and forth between the F's and the M's. Let's move it over-- set it to one gender. Set that to one. Now, can you tell what their gender is? It's kind of hard. Let me go over to minus one.
So those are the two genders. Now, outfits like Pixar and Disney have recognized that if you're going to do animation, it pays to overemphasize the attribute you want to display. And so I have a slider here, which overemphasizes the gender difference by a factor of three. And I go up to plus three there. Now, you can see what gender it is. On that side, go down to minus three there. The difference between the genders is all in the elbows and the hips. OK, that's Trode's eigenwalker.
Here's another example eigenworms. These are called nematodes. They're little worms that live in the human body and the digestive system. They're in the soil. They make soil decompose. Some of them are harmful. Some of them aren't. There's thousands of different kinds of nematodes. And here's a paper in the Journal of Computational Biology about the motion of nematodes. So they took some nematodes-- they're tiny, tiny, microscopic creatures-- and put them on a plate, and then heated the plate somewhat. So they made a move, and they recorded their motion.
And there is a set of ordinary differential equations that describe the motion. And the motion can be broken down into four principal components. Most of the motion-- I forget the percentage-- a large percentage of motion can be described as linear combination of these four motions and those principal components. The authors of this paper-- there's a link down at the bottom called those eigenworms.
Another story from the news. This is a graphic out of the British newspaper The Guardian some years ago, talking about-- Cambridge Analytica doesn't exist anymore. It went out of business. But this is where it came from. Cambridge Analytica was started by Steve Bannon and bankrolled by Robert Mercer. And as we now know, they tried to influence the Brexit vote in England and the 2016 presidential vote here in the United States.
And here's how they did it. Here's a paper by two professors from Cambridge University, and a researcher at Microsoft and Cambridge about predicting human behavior from digital records. Those digital records were Facebook data, data from almost 60,000 Facebook users and over 50,000 likes and dislikes they collected. So there was over 10 million-- this matrix had over 10 million elements in it.
And they did the singular value decomposition of this matrix. It's still at 60,000 rows, but it now had only 10 columns instead of 50,000. And that's the SVD. And then out of the SVD, they can take linear combinations of the principal components and predict various human behavior-- human attributes and human behavior. And here's what they can get out of that data. They can get your gender, your politics, your drug usage, your race.
And then more subtle things like-- they claim relating for your age-- but they can also measure things they call agreeableless and consciousness and openness. Of course, the data doesn't say that that's what those things are. But they're just called v6 and v7 and V8. But linear combinations of them can be interpreted in this way. So I'm not going to comment on what actually how effective this was. But that was what was behind the Cambridge Analytica story.
Let's go to the US Patent Office, and see how things are going there. A few days ago when I checked, there were almost 30,000 patents that have been issued. Over the length of the time that it's recorded on the website, 30,000 patents that involve the principal component analysis in some way or another, and almost 8,000 patents that mentioned the SVD.
Here's two of them. Here's one of the patents. Let's zoom in on it. It's a method for predicting successful relationships, and it's from a company called Eharmony. So Eharmony has patented the use of principal component analysis in the dating service. Here's a recent one, just in August. Zoom in on that. And it's by two investigators in Korea. It's about machine learning, but it involves the principal component analysis.
And you read it more carefully, you'll find that they are taking images of your shopping cart at a grocery store or mall and figuring out what's in your shopping cart, from the image analysis in machine learning using principal components. If you look at-- we're getting lots of press about machine learning and artificial intelligence today. But if you looked at what computations are going on in many of those uses of AI, there's something involving the principal component analysis, PCA.
Well, the list goes on and on. I mentioned Eharmony and matchmaking. There's crime forecasting-- looking at crime data and figuring out where the next crime is more likely to happen. We've seen image compression, protein molecular dynamics. Eigenfaces is a well-established technique in image processing. We mentioned eigenworms. There's only one paper about eigenworms.
Latent semantic indexing is text analysis. Your matrix is documents and words in the documents. And from the SVD, you can find out documents that are related to certain documents. So even though the document doesn't mention a particular term, it can be connected through PCA to documents that mention the terms. I have a friend at the University of Utah named Orly Alter. Orly is making important contributions now in brain cancer using the SVD, generalized SVD.
Even The MathWorks logo, the vibrating L-shaped membrane-- if you hear me talk about, wow, it's vibrating, that is because of the singular value decomposition. So that's how the SVD is saving the universe. Here's my title slide. I'm now going to make decreasing ranked approximations to this title slide, and here I go. And I'm down to rank one. And so that's the end of the talk.
Featured Product