Apply Speech Command Recognition Network in Smart Speaker Simulink Model
The previous example showed how to apply the speech command recognition workflow in Simulink®.
The ability to recognize speech commands is essential in smart systems. This example shows how to use the Simulink model developed in the previous example to recognize speech commands in a smart speaker system. These commands control playback and volume in the simulated smart speaker.
The next example shows how to deploy the smart speaker model on Raspberry Pi®.
Model Smart Speaker in Simulink
A smart speaker is a speaker that can be controlled by your voice. The smart speaker incorporates voice command recognition and operates in real time. This example shows a smart speaker model that responds to a number of voice commands. You make the smart speaker play music with the command "Go". You make it stop playing music by saying "Stop". You increase or decrease the music volume with the commands "Up" and "Down", respectively.
Model Summary
The model comprises three main parts:
An audio input path, representing microphone preprocessing.
An audio output path, representing loudspeaker output processing.
Audio devices and scopes, including components to monitor the audio and plot output signals in the time and frequency domains.
open_system("audioSmartSpeaker");
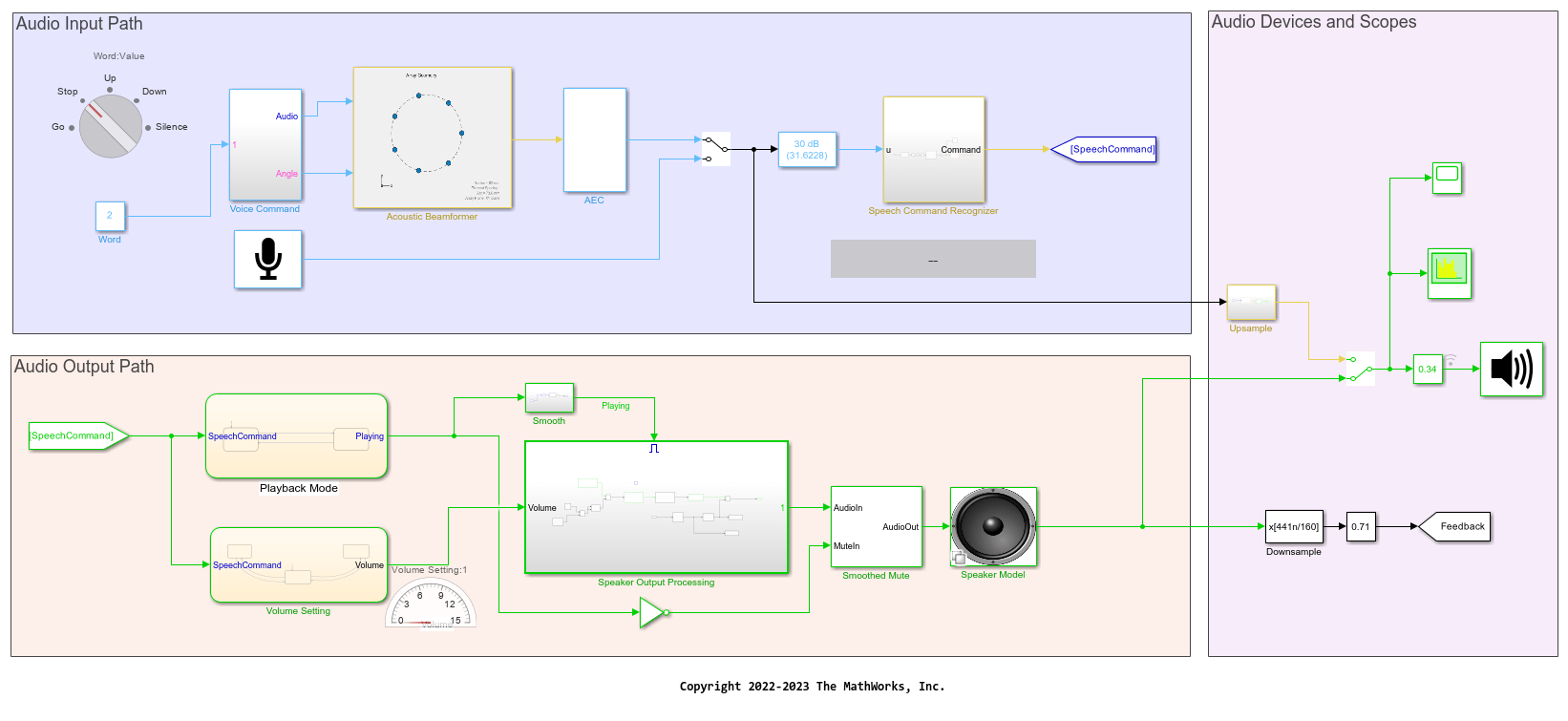
Voice Command Source
You can drive the smart speaker in two ways:
You can specify commands directly as the model is running through a microphone. Set up your microphone through the dialog of the Audio Device Reader block.
You can also simulate the reception of signals into a microphone array. In this case, the source of the voice commands is a set of audio files containing prerecorded commands. Use the rotary switch to select a specific audio command.
Select the voice command source by toggling the manual switch in the Audio Input Path section of the model.
Acoustic Beamforming
You apply acoustic beamforming when you simulate a microphone array. In this case, you model three sound sources in the Voice Command subsystem (the voice command, plus two background noise sources). The Acoustic Beamformer subsystem processes the different sound signals to isolate and enhance the voice command.
Acoustic Echo Cancellation
When you utter commands as music is playing, the music is picked up by the microphone after it reverberates around the room, creating an undesired feedback effect.
The Acoustic Echo Cancellation (AEC) subsystem removes the playback audio from the input signal by using a Normalized LMS adaptive filter. This component applies only when you simulate a microphone array using acoustic beamforming.
You can include or exclude the AEC component by changing the value of the check box on its mask dialog.
To hear the effect of AEC on the input audio signal, flip the manual switch in the Audio Devices and Scopes section of the model.
Speech Command Recognition
You pass the preprocessed speech command to the Speech Command Recognizer subsystem.
The Speech Command Recognizer subsystem uses the structure of the model in Apply Speech Command Recognition Network in Simulink. You extract auditory (Bark) spectrograms from the input audio, which you feed to the pretrained network. The network outputs the predicted command. You use this command to drive the Audio Output Path section of the model.
The subsystem uses a pretrained pruned deep learning network. Refer to the example Train Deep Learning Network for Speech Command Recognition for details on the architecture of this network and how to train it. Refer to the example Prune and Quantize Speech Command Recognition Network for details on compressing this network.
Control Audio Output Path with State Charts
The decoded speech command goes into two different state charts:
The first chart controls playback. Music starts paying when the "Go" command is received, and stops playing when "Stop" is received.
The second chart controls the playback volume by reacting to the commands "Up" and "Down".
Speaker Output Processing
When playback is triggered, the Speaker Output Processing subsystem is enabled. This subsystem contains blocks commonly used to tune audio, such as a Graphic EQ, a multiband parametric equalizer, and a dynamic range controller (limiter). You can tune your system sound as the model is playing by opening the mask dialog of these blocks and changing the values of parameters (for example, the frequencies of the Graphic EQ).
Smoothed Mute
When the music stops playing, it fades smoothly rather than stopping suddenly. This is achieved by the Smoothed Mute block which applies a time-varying gain on the audio signal. This block is based on the System object™ SmoothedMute.
Speaker Modeling
After Speaker Output Processing and Smoothed Mute, the signal goes into a Speaker Model subsystem. This subsystem allows you to control how the loudspeaker is modeled:
You can choose a behavioral model which implements the speaker model using basic mathematics Simulink blocks (such as sum, delay, integrator, and gain).
You can choose a circuit model which implements the speaker model using Simscape™ components.
You may also bypass these models if you are using a real, physical loudspeaker to listen to the audio.
Change the value of the variable speakerMode in the base workspace to select one of bypass (speakerMode=0), behavioral (speakerMode=1), or circuit (speakerMode=2).
Audio Devices and Scopes
The model uses a Spectrum Analyzer block to plot the audio signal in the frequency domain, and a time scope to visualize the streaming time-domain audio.