本页面提供的是上一版软件的文档。当前版本中已删除对应的英文页面。
径向基神经网络
神经元模型
这是具有 R 个输入的径向基网络。
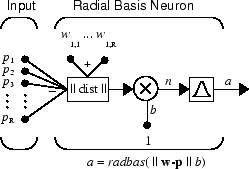
请注意,radbas 神经元的净输入的表达式与其他神经元的表达式不同。此处,radbas 传递函数的净输入是其权重向量 w 和输入向量 p 之间的向量距离乘以偏置 b。(此图窗中的 || dist || 框接受输入向量 p 和单行输入权重矩阵,并生成两者的点积。)
径向基神经元的传递函数为
以下是 radbas 传递函数的图。
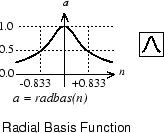
当输入为 0 时,径向基函数具有最大值 1。随着 w 和 p 之间距离的减小,输出也会增大。因此,径向基神经元充当一个检测器,只要输入 p 与其权重向量 w 相同,该检测器就生成 1。
偏置 b 允许调整 radbas 神经元的敏感度。例如,如果神经元的偏置为 0.1,则对于任何输入向量 p,如果它与其权重向量 w 的向量距离为 8.326 (0.8326/b) 处,系统会输出 0.5。
网络架构
径向基网络由两个层组成:S1 神经元构成的隐藏径向基层和由 S2 神经元组成的输出线性层。
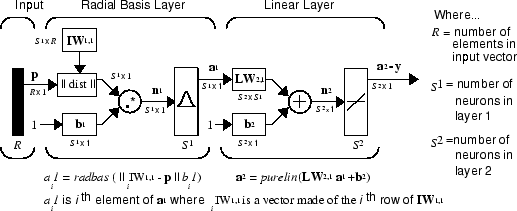
此图中的 || dist || 框接受输入向量 p 和输入权重矩阵 IW1,1,并生成一个具有 S1 个元素的向量。这些元素是输入向量和由输入权重矩阵的行形成的向量 iIW1,1 之间的距离。
偏置向量 b1 和 || dist || 的输出使用 MATLAB® 运算 .* 进行合并运算,该运算执行逐元素乘法。
前馈网络 net 的第一层的输出可通过以下代码获得:
a{1} = radbas(netprod(dist(net.IW{1,1},p),net.b{1}))
幸运的是,您不必编写这样的代码行。设计该网络的所有细节都内置于设计函数 newrbe 和 newrb 中,您可以通过 sim 获得其输出。
通过跟踪输入向量 p 经过网络到输出 a2 的过程,您可以了解该网络的行为。如果向这样的网络提交一个输入向量,径向基层中的每个神经元将根据输入向量与每个神经元的权重向量的接近程度输出一个值。
因此,权重向量与输入向量 p 差异很大的径向基神经元具有接近于零的输出。这些值很小的输出对线性输出神经元的影响可以忽略不计。
相反,权重向量接近输入向量 p 的径向基神经元生成接近 1 的值。如果神经元的输出为 1,它在第二层的输出权重会将其值传递给第二层中的线性神经元。
事实上,如果只有一个径向基神经元的输出为 1,而所有其他神经元的输出为 0(或非常接近 0),则线性层的输出将是活动神经元的输出权重。不过,这是极端情况。通常几个神经元的输出值总是存在不同程度的差异。
现在详细看看第一层是如何运作的。每个神经元的加权输入是输入向量与其权重向量之间的距离,用 dist 计算。每个神经元的净输入是其加权输入与其偏置的逐元素乘积,用 netprod 计算。每个神经元的输出是其通过 radbas 的净输入。如果一个神经元的权重向量等于输入向量(经过转置),则其加权输入为 0,其净输入为 0,其输出为 1。如果一个神经元的权重向量是 spread 到输入向量的距离,其加权输入是 spread,其净输入是 sqrt(−log(.5))(即 0.8326),因此其输出是 0.5。
精确设计 (newrbe)
您可以使用函数 newrbe 设计径向基网络。该函数可以生成一个在训练向量上具有零误差的网络。其调用方式如下:
net = newrbe(P,T,SPREAD)
函数 newrbe 接受输入向量 P 和目标向量 T 的矩阵,以及径向基层的分布常数 SPREAD,并返回一个具有权重和偏置的网络,使得当输入为 P 时,输出正好为 T。
此函数 newrbe 创建与 P 中输入向量的数目一样多的 radbas 神经元,并将第一层的权重设置为 P'。因此,存在一个由 radbas 神经元组成的层,其中每个神经元充当一个针对不同输入向量的检测器。如果有 Q 个输入向量,则会有 Q 个神经元。
第一层中的每个偏置设置为 0.8326/SPREAD。这给出了在加权输入为 +/− SPREAD 时跨度为 0.5 的径向基函数。这决定了每个神经元响应的输入空间中区域的宽度。如果 SPREAD 是 4,则对于与其权重向量的向量距离在 4 以内的任何输入向量,每个 radbas 神经元的响应为 0.5 或更大的值。SPREAD 应足够大,以使神经元对输入空间的重叠区域作出强响应。
通过仿真第一层输出 a1 (A{1}),然后求解以下线性表达式,求得第二层权重 IW·2,1(在代码中为 IW{2,1})和偏置 b2(在代码中为 b{2}):
[W{2,1} b{2}] * [A{1}; ones(1,Q)] = T
您知道第二层 (A{1}) 和目标 (T) 的输入,并且该层是线性的。您可以使用以下代码计算第二层的权重和偏置,以最小化误差平方和。
Wb = T/[A{1}; ones(1,Q)]
此处 Wb 包含权重和偏置,偏置在最后一列中。如下所述,误差平方和始终为 0。
假设一个问题有 C 个约束(输入/目标对组),每个神经元都有 C +1 个变量(C 个权重来自 C 个 radbas 神经元,还有一个偏置)。如果一个线性问题具有 C 个约束和 C 个以上变量,则该线性问题具有无限数量的零误差解。
因此,newrbe 会创建一个在训练向量上具有零误差的网络。唯一需要的条件是确保 SPREAD 足够大,以使 radbas 神经元的活动输入区域存在足够的重叠,使得几个 radbas 神经元在任何给定时刻始终具有相当大的输出。这使得网络函数更平滑,从而对于介于设计中所用输入向量之间的新输入向量具有更强的泛化能力。(然而,SPREAD 不应太大,否则会导致每个神经元实际上都在同一个大的输入空间区域内进行响应。)
newrbe 的缺点是它生成的网络中的隐藏神经元和输入向量一样多。因此,在需要许多输入向量来正确定义网络时(通常情况下会这样),newrbe 不会返回可接受的解。
更高效的设计 (newrb)
函数 newrb 以每次创建一个神经元的迭代方式创建一个径向基网络。神经元添加到网络中,直到误差平方和低于误差目标或达到最大神经元数。对此函数的调用是
net = newrb(P,T,GOAL,SPREAD)
函数 newrb 接受输入向量 P 和目标向量 T 的矩阵,以及设计参数 GOAL 和 SPREAD,并返回所需的网络。
newrb 的设计方法与 newrbe 相似。不同的是,newrb 一次创建多个神经元。在每次迭代中,使网络误差降幅最大的输入向量用于创建一个 radbas 神经元。检查新网络的误差,如果误差足够低,则结束运行 newrb。否则添加下一个神经元。重复此过程,直到满足误差目标或达到最大神经元数量。
与 newrbe 一样,分布参数必须足够大,以便 radbas 神经元对输入空间的重叠区域作出响应,但不能大到所有神经元都以基本相同的方式作出响应。
为什么不始终使用径向基网络代替标准前馈网络?径向基网络,即使是使用 newrbe 高效设计的,其神经元数量也往往比在隐藏层中具有 tansig 或 logsig 神经元的前馈网络多许多倍。
这是因为,sigmoid 神经元可以针对输入空间中的一个大区域提供输出,而 radbas 神经元只对输入空间中相对较小的区域作出响应。结果是,输入空间越大(根据输入数目以及这些输入的变化范围),所需的 radbas 神经元就越多。
另一方面,设计径向基网络花费的时间通常远远少于训练 sigmoid/linear 网络,有时还只需使用更少的神经元,如以下示例中所示。
示例
示例径向基逼近说明如何使用径向基网络来拟合函数。在此处,只用五个神经元就完成了问题的求解。
示例径向基神经元欠叠和径向基神经元过叠研究分布常数如何影响径向基网络的设计过程。
在径向基神经元欠叠中,径向基网络设计用于求解与径向基逼近中相同的问题。然而,这次使用的分布常数是 0.01。因此,对于距离其权重向量为 0.01 或更大值的任何输入向量,每个径向基神经元返回 0.5 或更低的值。
由于训练输入以 0.1 的间隔出现,因此对于任一给定输入,没有两个径向基神经元具有强输出。
径向基神经元欠叠表明,分布常数过小可能会得到不是从设计中所用输入/目标向量泛化产生的解。示例径向基神经元过叠展示了相反的问题。如果分布常数足够大,则对于用于设计网络的所有输入,径向基神经元将输出较大的值(接近 1.0)。
如果所有径向基神经元始终输出 1,则提交给网络的任何信息都将丢失。不管输入是什么,第二层始终输出 1。函数 newrb 将尝试找到一个网络,但由于在这种情况下出现的数值问题而找不到。
以上示例说明,选择的分布常数应大于相邻输入向量之间的距离(以获得良好的泛化能力),但小于跨整个输入空间的距离。
对于上述问题,这意味着选取的分布常数应大于 0.1(各输入之间的间隔)且小于 2(最左边和最右边输入之间的距离)。