重新训练神经网络以对新图像进行分类
此示例说明如何重新训练预训练的 SqueezeNet 神经网络以对新的图像集合执行分类。
通过调整神经网络以匹配新任务,并使用其学习到的权重作为起点,您可以针对新数据集重新训练预训练的网络。为了使网络适应新数据,请替换最后几层(称为网络头),使神经网络针对新任务输出每个类的预测分数。
可通过多种方法重新训练神经网络。
从头开始重新训练 - 使用相同的网络架构从头开始训练神经网络。
迁移学习 - 冻结预训练神经网络权重并仅重新训练网络头。
微调 - 重新训练部分或全部神经网络权重,并可选择减慢预训练权重的训练。
与从头开始训练神经网络相比,对预训练神经网络执行迁移学习和微调通常需要的数据更少,并且更快更容易。
下图说明重新训练神经网络的一般过程。
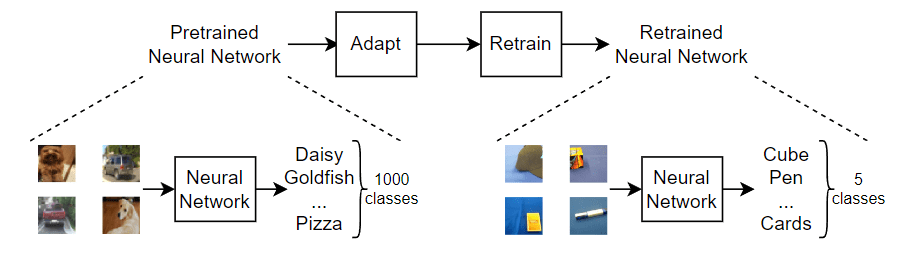
此示例使用迁移学习重新训练 SqueezeNet 神经网络。此网络已基于超过一百万个图像进行训练,可以将图像分为 1000 个对象类别(例如键盘、咖啡杯、铅笔和多种动物)。该网络已基于大量图像学习了丰富的特征表示。网络以图像作为输入,然后输出每个类的预测分数。
加载训练数据
提取 MathWorks™ Merch 数据集。这是一个包含 75 个 MathWorks 商品图像的小型数据集,这些商品分属五个不同的类。数据的排列使得图像位于对应于这五个类的子文件夹中。
folderName = "MerchData"; unzip("MerchData.zip",folderName);
创建一个图像数据存储。图像数据存储可用于存储大量的图像数据,包括无法放入内存的数据,并在训练神经网络时高效地分批读取图像。指定包含提取图像的文件夹,并指示子文件夹名称与图像标签对应。
imds = imageDatastore(folderName, ... IncludeSubfolders=true, ... LabelSource="foldernames");
显示一些示例图像。
numImages = numel(imds.Labels); idx = randperm(numImages,16); I = imtile(imds,Frames=idx); figure imshow(I)

查看类名称和类数。
classNames = categories(imds.Labels)
classNames = 5×1 cell
{'MathWorks Cap' }
{'MathWorks Cube' }
{'MathWorks Playing Cards'}
{'MathWorks Screwdriver' }
{'MathWorks Torch' }
numClasses = numel(classNames)
numClasses = 5
将数据划分为训练、验证和测试数据集。将 70% 的图像用于训练,15% 的图像用于验证,15% 的图像用于测试。splitEachLabel 函数将图像数据存储拆分为三个新数据存储。
[imdsTrain,imdsValidation,imdsTest] = splitEachLabel(imds,0.7,0.15,"randomized");加载预训练网络
为了使预训练神经网络适应新任务,请替换最后几层(称为网络头),使其针对新任务输出每个类的预测分数。下图概述了对 类进行预测的神经网络的架构,并说明了如何编辑网络以使其输出对 类的预测。
![Diagram showing how to replace layers for transfer learning. It shows image input data flowing through a series of layers labeled "backbone". The output of the backbone is labeled "extracted features. The extracted features are passed subsequent layers labeled "Head", which has an output vector [y1,,...,yK]. Separate from the network, there are layers labeled "New Head" which consist of a fully connected layer of size K* and a softmax layer. This has an output vector of [y1,...,yK*]. There is a double sided arrow that indicates to swap the part labeled "Head" with the part labeled "New Head".](../../examples/nnet/win64/RetrainNeuralNetworkToClassifyNewImagesExample_03.png)
使用 imagePretrainedNetwork 函数将预训练的 SqueezeNet 神经网络加载到工作区中。要返回准备好针对新数据重新训练的神经网络,请指定类的数目。当您指定类的数目时,imagePretrainedNetwork 函数会调整神经网络,使其输出指定数量的类中每个类的预测分数。
您可以尝试其他预训练网络。Deep Learning Toolbox™ 提供各种具有不同大小、速度和准确度的预训练网络。这些其他网络通常需要支持包。如果未安装所选网络的支持包,则函数会提供下载链接。有关详细信息,请参阅预训练的深度神经网络。
net = imagePretrainedNetwork( "squeezenet",NumClasses=numClasses)
"squeezenet",NumClasses=numClasses)net =
dlnetwork with properties:
Layers: [68×1 nnet.cnn.layer.Layer]
Connections: [75×2 table]
Learnables: [52×3 table]
State: [0×3 table]
InputNames: {'data'}
OutputNames: {'prob_flatten'}
Initialized: 1
View summary with summary.
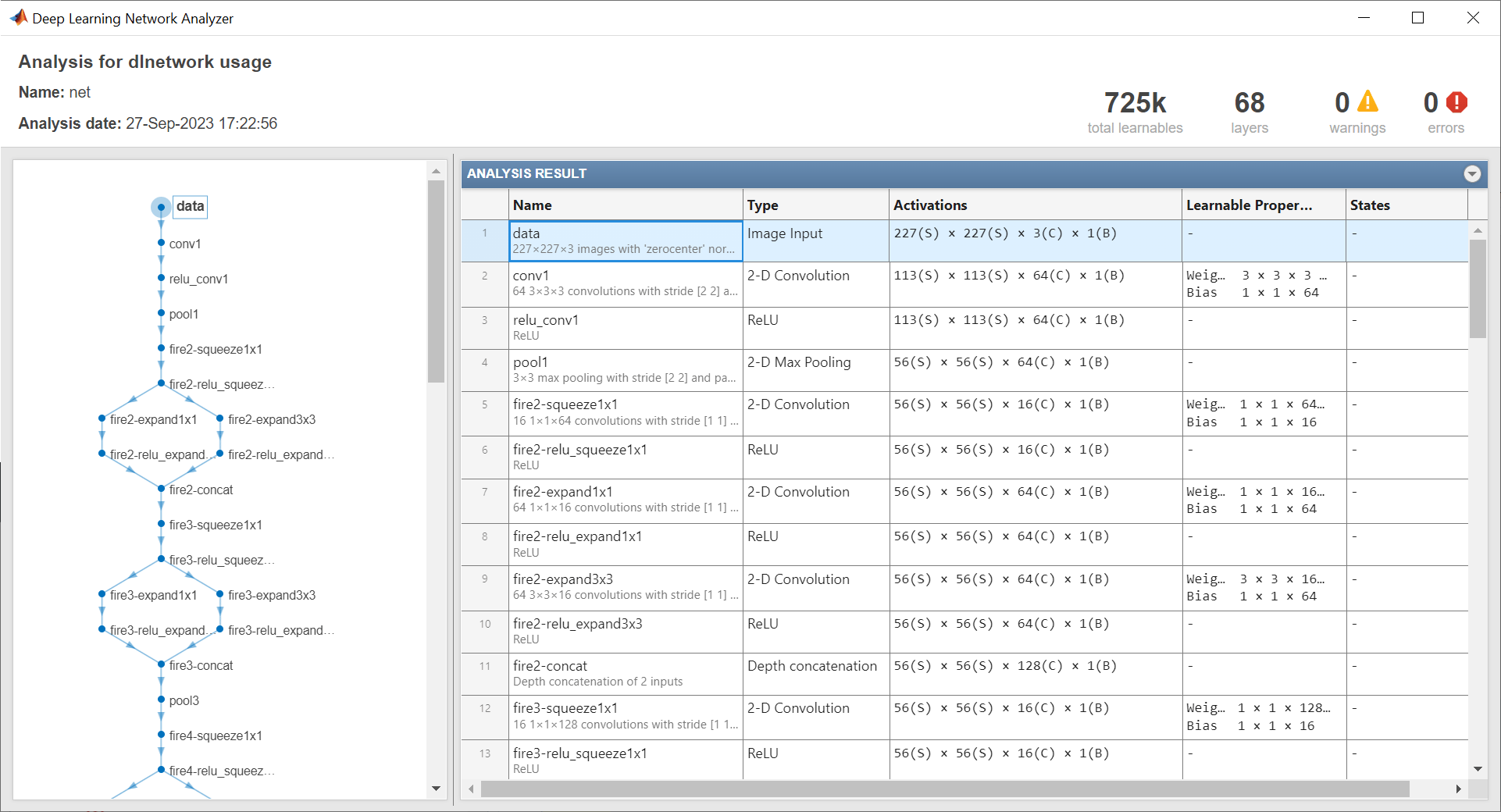
使用 analyzeNetwork 函数查看网络架构。注意输入层和具有可学习参数的最后一个层。
analyzeNetwork(net)
输入层显示神经网络的输入大小。
从输入层中获取神经网络输入大小。作为支持文件包含在此示例中的 networkInputSize 函数从输入层提取输入大小。要访问此函数,请以实时脚本形式打开此示例。
inputSize = networkInputSize(net)
inputSize = 1×3
227 227 3
网络头中的可学习层(具有可学习参数的最后一个层)需要重新训练。该层通常是一个全连接层或卷积层,其输出大小与类数相匹配。
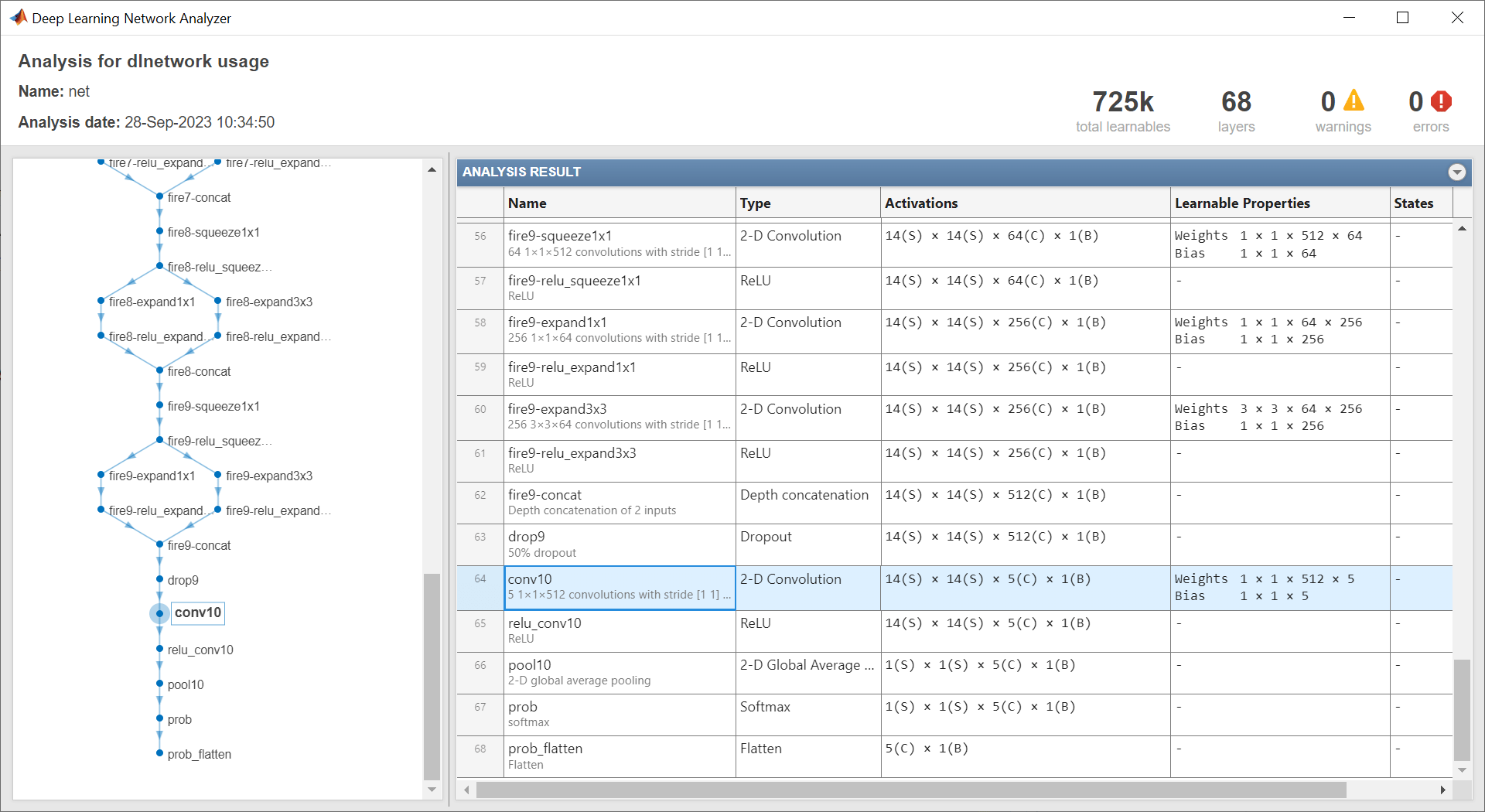
作为支持文件包含在此示例中的 networkHead 函数返回网络头中可学习层的层名称和可学习参数名称。要访问此函数,请以实时脚本形式打开此示例。
[layerName,learnableNames] = networkHead(net)
layerName = "conv10"
learnableNames = 2×1 string
"conv10/Weights"
"conv10/Bias"
对于迁移学习,您可以将较浅网络层的学习率设置为 0,来冻结这些层的权重。在训练过程中,trainnet 函数不会更新这些已冻结层的参数。由于函数不需要计算已冻结层的梯度,因此冻结权重可以显著加快网络训练速度。对于小型数据集,冻结网络层可防止这些层对新数据集过拟合。
使用作为支持文件包含在此示例中的 freezeNetwork 函数冻结网络权重,保持最后一个可学习层不冻结。要访问此函数,请以实时脚本形式打开此示例。
net = freezeNetwork(net,LayerNamesToIgnore=layerName);
提示:作为冻结较浅层权重的替代方法,您可以降低对这些层的更新级别并提高对新分类头的更新级别。这称为微调。为此,请使用 setLearnRateFactor 函数增大新分类头中可学习参数的学习率因子。然后,使用 trainingOptions 的 InitialLearnRate 参量降低全局学习率。
准备要训练的数据
数据存储中图像的大小可以不同。要自动调整训练图像的大小,请使用增强的图像数据存储。数据增强还有助于防止网络过拟合和记忆训练图像的具体细节。指定要对训练图像额外执行的这些增强操作:沿垂直轴随机翻转训练图像,以及在水平和垂直方向上随机平移训练图像最多 30 个像素。
pixelRange = [-30 30]; imageAugmenter = imageDataAugmenter( ... RandXReflection=true, ... RandXTranslation=pixelRange, ... RandYTranslation=pixelRange); augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain, ... DataAugmentation=imageAugmenter);
要在不执行进一步数据增强的情况下自动调整验证和测试图像的大小,请使用增强的图像数据存储,而不指定任何其他预处理操作。
augimdsValidation = augmentedImageDatastore(inputSize(1:2),imdsValidation); augimdsTest = augmentedImageDatastore(inputSize(1:2),imdsTest);
指定训练选项
指定训练选项。在选项中进行选择需要经验分析。要通过运行试验探索不同训练选项配置,您可以使用Experiment Manager。
对于此示例,请使用以下选项:
使用 Adam 优化器进行训练。
每迭代五次使用验证数据对网络进行一次验证。对于较大的数据集,为了防止验证拖慢训练速度,请增大此值。
在图中显示训练进度,并监控准确度度量。
禁用详尽输出。
options = trainingOptions("adam", ... ValidationData=augimdsValidation, ... ValidationFrequency=5, ... Plots="training-progress", ... Metrics="accuracy", ... Verbose=false);
训练神经网络
使用 trainnet 函数训练神经网络。对于分类,使用交叉熵损失。默认情况下,trainnet 函数使用 GPU(如果有)。使用 GPU 需要 Parallel Computing Toolbox™ 许可证和受支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。否则,trainnet 函数使用 CPU。要指定执行环境,请使用 ExecutionEnvironment 训练选项。
net = trainnet(augimdsTrain,net,"crossentropy",options);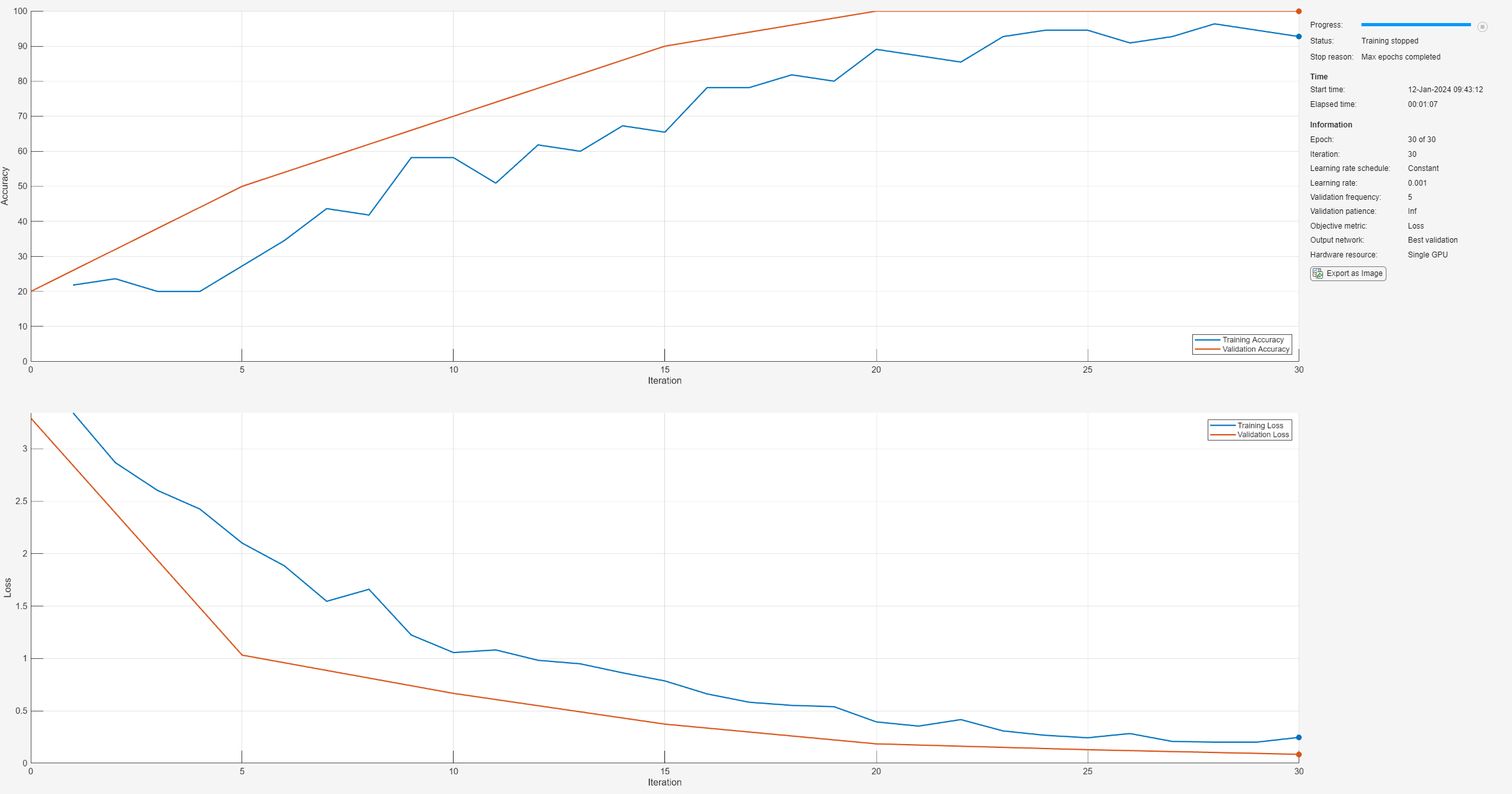
测试神经网络
对测试图像进行分类。要使用多个观测值进行预测,请使用 minibatchpredict 函数。要将预测分数转换为标签,请使用 scores2label 函数。minibatchpredict 函数自动使用 GPU(如果有)。
YTest = minibatchpredict(net,augimdsTest); YTest = scores2label(YTest,classNames);
在混淆图中可视化分类准确度。
TTest = imdsTest.Labels; figure confusionchart(TTest,YTest)
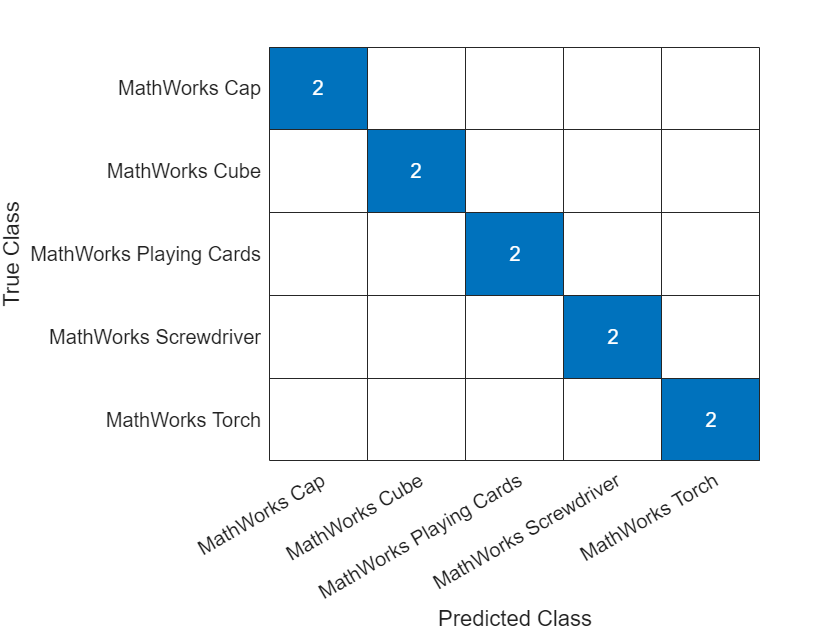
计算测试数据的分类准确度。准确度是指正确预测的百分比。
acc = mean(TTest==YTest)
acc = 1
使用新数据进行预测
从 JPEG 文件中读取一个图像,调整其大小,并将其转换为 single 数据类型。
im = imread("MerchDataTest.jpg");
im = imresize(im,inputSize(1:2));
X = single(im);对图像进行分类。要使用单个观测值进行预测,请使用 predict 函数。如果有受支持的 GPU 可用于计算,则首先将数据转换为 gpuArray 对象。
if canUseGPU X = gpuArray(X); end scores = predict(net,X); [label,score] = scores2label(scores,classNames);
显示具有预测标签和对应分数的图像。
figure imshow(im) title(string(label) + " (Score: " + gather(score) + ")")

另请参阅
imagePretrainedNetwork | dlnetwork | trainingOptions | trainnet