预训练的深度神经网络
您可以采用预训练的图像分类神经网络,它已学会从自然图像中提取功能强大且包含丰富信息的特征,并以此作为学习新任务的起点。大多数预训练神经网络是基于 ImageNet 数据库 [1] 的子集进行训练的,该数据库用于 ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) [17] 中。这些神经网络已经对超过一百万个图像进行了训练,可以将图像分为 1000 个对象类别,例如键盘、咖啡杯、铅笔和多种动物。通常来说,使用预训练神经网络进行迁移学习比从头开始训练神经网络更快更容易。
您可以将之前训练过的神经网络用于以下任务:
| 目的 | 描述 |
|---|---|
| 分类 | 将预训练的神经网络直接应用于分类问题。要对新图像进行分类,请使用 |
| 特征提取 | 通过使用层激活值作为特征,使用预训练神经网络作为特征提取器。您可以使用这些激活值作为特征来训练另一个机器学习模型,例如支持向量机 (SVM)。有关详细信息,请参阅特征提取。有关示例,请参阅使用预训练网络提取图像特征。 |
| 迁移学习 | 从基于大型数据集训练的神经网络中提取层,并基于新数据集进行微调。有关详细信息,请参阅迁移学习。有关简单的示例,请参阅迁移学习快速入门。要尝试更多预训练的神经网络,请参阅重新训练神经网络以对新图像进行分类。 |
比较预训练的神经网络
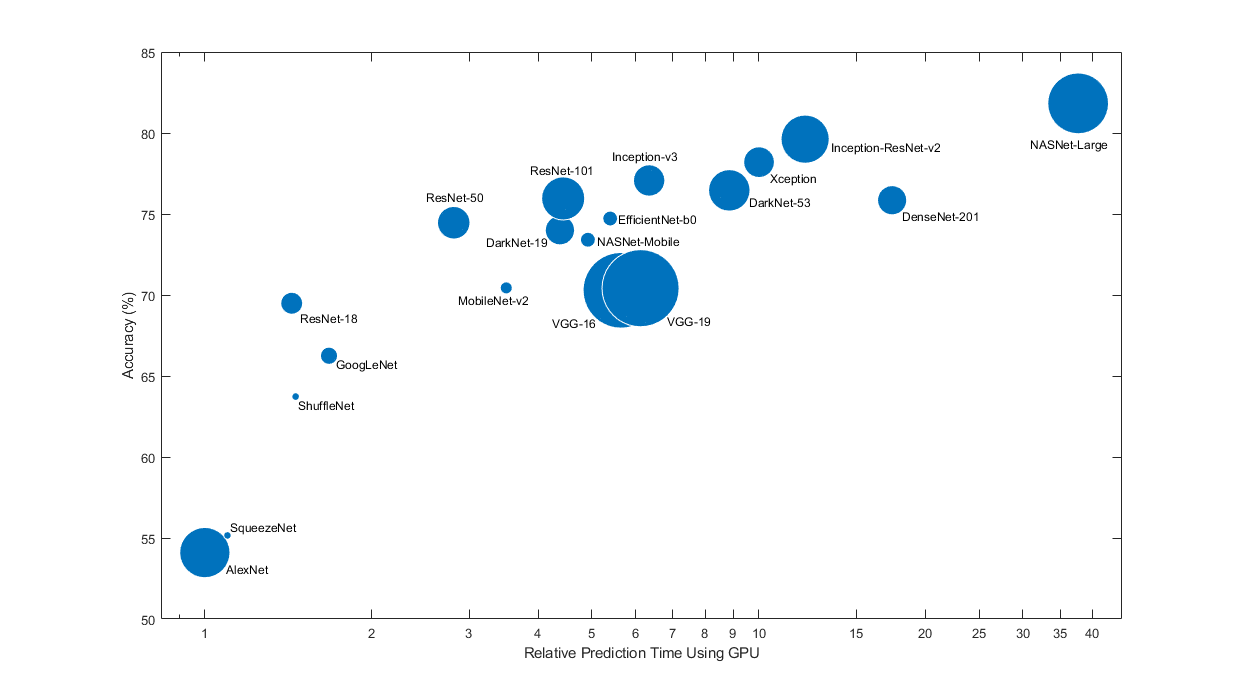
当选择适用于您的问题的神经网络时,预训练神经网络具有不同的重要特征。最重要的特征是神经网络的准确度、速度和规模。选择神经网络时通常需要在这些特征之间进行权衡。使用下图比较 ImageNet 验证准确度和使用神经网络进行预测所需的时间。
提示
要开始迁移学习,请尝试选择一个更快的神经网络,例如 SqueezeNet 或 GoogLeNet。然后,您可以快速迭代并尝试不同设置,如数据预处理步骤和训练选项。一旦您感觉到哪些设置运行良好,请尝试更准确的神经网络,例如 Inception-v3 或 ResNet,看看这是否能改进您的结果。
注意
上图仅显示不同神经网络的相对速度。准确的预测和训练迭代时间取决于您使用的硬件和小批量大小。
理想的神经网络具有高准确度并且速度很快。该图显示的是使用现代 GPU (NVIDIA® Tesla® P100) 和大小为 128 的小批量时分类准确度对预测时间的结果。预测时间是相对于最快的神经网络来测量的。每个标记的面积与神经网络在磁盘上的大小成正比。
ImageNet 验证集上的分类准确度是衡量在 ImageNet 上训练的神经网络准确度的最常见方法。如果您的神经网络在 ImageNet 上准确,则当您使用迁移学习或特征提取将网络应用于其他自然图像数据集时,您的网络通常也是准确的。这种泛化之所以可行,是因为神经网络已学会从自然图像中提取强大的信息特征,这些特征可以泛化到其他类似的数据集。但是,在 ImageNet 上的高准确度并不能始终直接迁移到其他任务,因此最好尝试多个神经网络。
如果您要使用受限制的硬件执行预测或通过 Internet 分发神经网络,则还要考虑神经网络在磁盘上和内存中的大小。
神经网络准确度
可以使用多种方法来计算基于 ImageNet 验证集的分类准确度,不同数据源使用不同的方法。有时使用包含多个模型的集合,有时使用多次裁剪对每个图像进行多次计算。有时会引用 top-5 准确度,而不是标准 (top-1) 准确度。由于这些差异,通常无法直接比较不同数据源的准确度。Deep Learning Toolbox™ 中预训练神经网络的准确度是使用单一模型和单一中心图像裁剪的标准 (top-1) 准确度。
加载预训练的神经网络
要加载 SqueezeNet 神经网络,请使用 imagePretrainedNetwork 函数。
[net,classNames] = imagePretrainedNetwork;
对于其他神经网络,请使用 imagePretrainedNetwork 函数的第一个参量指定模型。如果您没有网络所需的支持包,该函数会提供下载链接。您也可以从附加功能资源管理器下载预训练神经网络。
下表列出了基于 ImageNet 训练的可用预训练神经网络以及这些网络的一些属性。神经网络深度定义为从网络输入到网络输出的路径中顺序卷积层或全连接层的最大数量。所有神经网络的输入均为 RGB 图像。
imagePretrainedNetwork 模型名称参量 | 神经网络名称 | 深度 | 参数内存 | 参数(单位为百万) | 图像输入大小 | 输入值范围 | 输入层归一化 | 所需的支持包 |
|---|---|---|---|---|---|---|---|---|
"squeezenet" | SqueezeNet [2] | 18 | 4.7 MB | 1.24 | 227×227 | [0, 255] | "zerocenter" | 无 |
"googlenet" | GoogLeNet [3][4] | 22 | 27 MB | 7.0 | 224×224 | [0, 255] | "zerocenter" | Deep Learning Toolbox Model for GoogLeNet Network |
"googlenet-places365" | 24 MB | 6.3 | 224×224 | [0, 255] | "zerocenter" | |||
"inceptionv3" | Inception-v3 [5] | 48 | 91 MB | 23.9 | 299×299 | [0, 255] | "rescale-symmetric" | Deep Learning Toolbox Model for Inception-v3 Network |
"densenet201" | DenseNet-201 [6] | 201 | 77 MB | 20.0 | 224×224 | [0, 255] | "zscore" | Deep Learning Toolbox Model for DenseNet-201 Network |
"mobilenetv2" | MobileNet-v2 [7] | 53 | 14 MB | 3.5 | 224×224 | [0, 255] | "zscore" | Deep Learning Toolbox Model for MobileNet-v2 Network |
"resnet18" | ResNet-18 [8] | 18 | 45 MB | 11.7 | 224×224 | [0, 255] | "zscore" | Deep Learning Toolbox Model for ResNet-18 Network |
"resnet50" | ResNet-50 [8] | 50 | 98 MB | 25.6 | 224×224 | [0, 255] | "zscore" | Deep Learning Toolbox Model for ResNet-50 Network |
"resnet101" | ResNet-101 [8] | 101 | 171 MB | 44.6 | 224×224 | [0, 255] | "zerocenter" | Deep Learning Toolbox Model for ResNet-101 Network |
"xception" | Xception [9] | 71 | 88 MB | 22.9 | 299×299 | [0, 255] | "rescale-symmetric" | Deep Learning Toolbox Model for Xception Network |
"inceptionresnetv2" | Inception-ResNet-v2 [10] | 164 | 213 MB | 55.9 | 299×299 | [0, 255] | "rescale-symmetric" | Deep Learning Toolbox Model for Inception-ResNet-v2 Network |
"shufflenet" | ShuffleNet [11] | 50 | 5.5 MB | 1.4 | 224×224 | [0, 255] | "zscore" | Deep Learning Toolbox Model for ShuffleNet Network |
"nasnetmobile" | NASNet-Mobile [12] | * | 20 MB | 5.3 | 224×224 | [0, 255] | "rescale-symmetric" | Deep Learning Toolbox Model for NASNet-Mobile Network |
"nasnetlarge" | NASNet-Large [12] | * | 340 MB | 88.9 | 331×331 | [0, 255] | "rescale-symmetric" | Deep Learning Toolbox Model for NASNet-Large Network |
"darknet19" | DarkNet-19 [13] | 19 | 80 MB | 20.8 | 256×256 | [0, 255] | "rescale-zero-one" | Deep Learning Toolbox Model for DarkNet-19 Network |
"darknet53" | DarkNet-53 [13] | 53 | 159 MB | 41.6 | 256×256 | [0, 255] | "rescale-zero-one" | Deep Learning Toolbox Model for DarkNet-53 Network |
"efficientnetb0" | EfficientNet-b0 [14] | 82 | 20 MB | 5.3 | 224×224 | [0, 255] | "zscore" | Deep Learning Toolbox Model for EfficientNet-b0 Network |
"alexnet" | AlexNet [15] | 8 | 233 MB | 61.0 | 227×227 | [0, 255] | "zerocenter" | Deep Learning Toolbox Model for AlexNet Network |
"vgg16" | VGG-16 [16] | 16 | 528 MB | 138 | 224×224 | [0, 255] | "zerocenter" | Deep Learning Toolbox Model for VGG-16 Network |
"vgg19" | VGG-19 [16] | 19 | 548 MB | 144 | 224×224 | [0, 255] | "zerocenter" | Deep Learning Toolbox Model for VGG-19 Network |
*NASNet-Mobile 和 NASNet-Large 神经网络不是由模块的线性序列构成的。
基于 Places365 训练的 GoogLeNet
标准 GoogLeNet 神经网络是基于 ImageNet 数据集进行训练的,但您也可以加载基于 Places365 数据集训练的神经网络 [18] [4]。基于 Places365 训练的神经网络将图像分为 365 个不同位置类别,例如田野、公园、跑道和大厅。要加载基于 Places365 数据集训练的预训练 GoogLeNet 神经网络,请使用 imagePretrainedNetwork("googlenet-places365")。当您为新任务执行迁移学习时,最常见的方法是使用基于 ImageNet 预训练的神经网络。如果新任务类似于场景分类,则使用基于 Places365 训练的神经网络可以提供更高的准确度。
有关适用于音频任务的预训练神经网络的信息,请参阅针对音频应用的预训练的神经网络。
可视化预训练的神经网络
您可以使用深度网络设计器加载和可视化预训练神经网络。
[net,classNames] = imagePretrainedNetwork; deepNetworkDesigner(net)
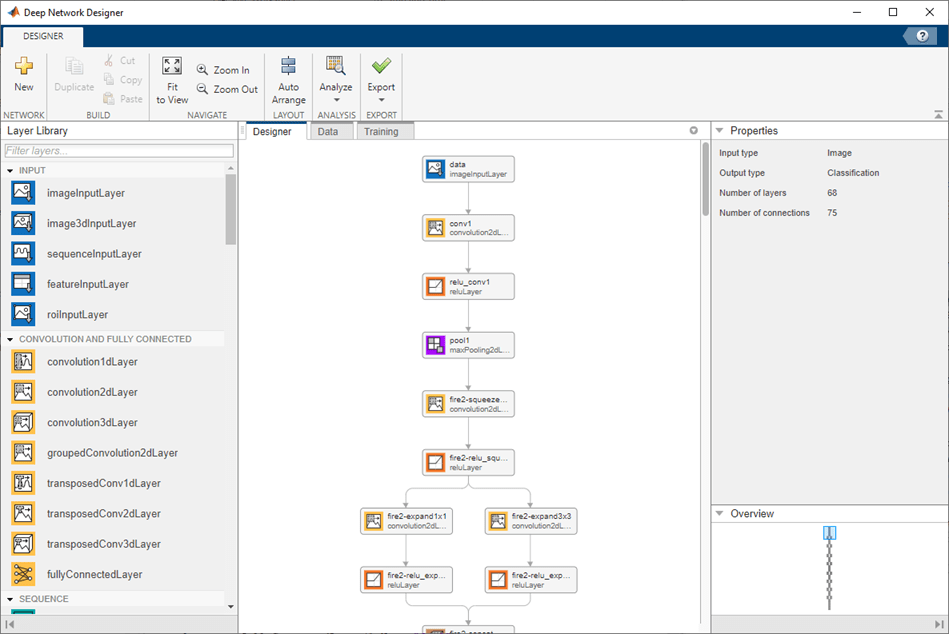
要查看和编辑层属性,请选择一个层。有关层属性的信息,请点击层名称旁边的帮助图标。

通过点击新建,在深度网络设计器中浏览其他预训练神经网络。
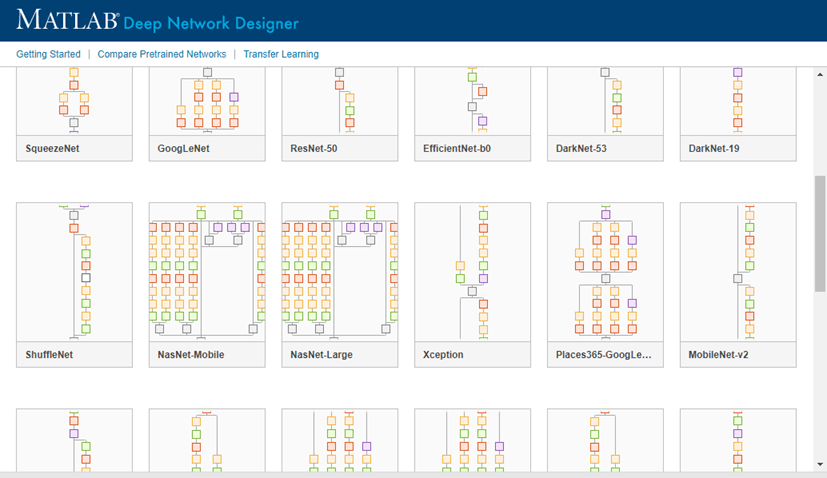
如果需要下载一个神经网络,请在所需的神经网络上暂停,然后点击安装以打开附加功能资源管理器。
特征提取
特征提取可以简单快捷地利用深度学习的强大功能,而无需投入时间和精力来训练完整神经网络。由于它只需遍历一次训练图像,因此如果您没有 GPU,特征提取会特别有用。您使用预训练神经网络提取学习到的图像特征,然后使用这些特征来训练分类器,例如使用 fitcsvm (Statistics and Machine Learning Toolbox) 的支持向量机。
当您的新数据集很小时,请尝试使用特征提取。由于您仅基于提取的特征来训练简单的分类器,因此训练速度很快。由于几乎没有数据可供学习,因此微调神经网络的更深层也不太可能提高准确度。
如果您的数据与原始数据非常相似,则在神经网络的更深层提取的更具体的特征可能对新任务有用。
如果您的数据与原始数据相差很大,则在神经网络的更深层提取的特征可能对您的任务用处不大。请尝试基于从较浅神经网络层提取的更一般特征来训练最终的分类器。如果新数据集很大,则您也可以尝试从头开始训练神经网络。
ResNet 神经网络通常是合适的特征提取器。有关如何使用预训练神经网络进行特征提取的示例,请参阅使用预训练网络提取图像特征。
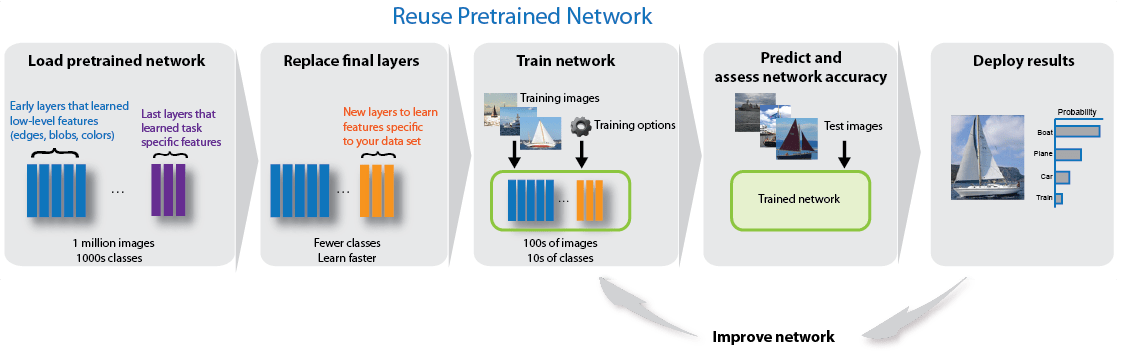
迁移学习
您可以通过基于新数据集对神经网络进行训练来微调神经网络中的更深层,并以该预训练神经网络为起点。通过迁移学习来微调神经网络通常比构建和训练新神经网络更快更容易。神经网络已学习到一系列丰富的图像特征,但当您微调神经网络时,它可以学习特定于您的新数据集的特征。如果您有超大型数据集,则迁移学习可能不会比从头开始训练更快。
提示
微调神经网络通常能达到最高的准确度。对于非常小的数据集(每个类不到 20 个图像),请尝试使用特征提取。
与简单的特征提取相比,微调神经网络会更慢,需要完成的工作更多,但由于神经网络可以学习提取不同的特征集,最终的神经网络通常更准确。只要新数据集不是特别小,微调通常比特征提取效果更好,因为微调时神经网络有数据可供学习新特征。有关如何执行迁移学习的示例,请参阅使用深度网络设计器为迁移学习准备网络和重新训练神经网络以对新图像进行分类。
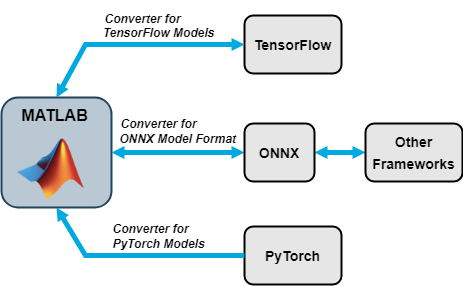
导入和导出神经网络
您可以从 TensorFlow™ 2、TensorFlow-Keras、Keras 3、PyTorch® 和 ONNX™(开放式神经网络交换)模型格式导入神经网络。您还可以将 Deep Learning Toolbox 神经网络导出为 TensorFlow 2 和 ONNX 模型格式。
提示
您可以使用深度网络设计器从外部平台导入模型。导入时,该 App 会显示一个导入报告,详细说明需要注意的任何问题。
导入函数
| 外部深度学习平台和模型格式 | 将模型作为 dlnetwork 导入 |
|---|---|
SavedModel 格式的 TensorFlow 神经网络、TensorFlow-Keras 神经网络或 Keras 3 神经网络 | 深度网络设计器或 importNetworkFromTensorFlow 或 importNetworkFromKeras |
.pt 文件格式的跟踪的 PyTorch 模型 | 深度网络设计器或 importNetworkFromPyTorch |
| ONNX 模型格式的神经网络 | importNetworkFromONNX |
导入网络时,当您导入包含软件无法转换为内置 MATLAB® 层的 TensorFlow 层、PyTorch 层或 ONNX 运算符的模型时,软件会自动生成自定义层。软件会将自动生成的自定义层保存到当前文件夹中的包中。有关详细信息,请参阅Autogenerated Custom Layers。
导出函数
| 外部深度学习平台和模型格式 | 导出神经网络或层图 |
|---|---|
| Python® 包中的 TensorFlow 2 模型 | exportNetworkToTensorFlow |
| ONNX 模型格式 | exportONNXNetwork |
exportNetworkToTensorFlow 函数将 Deep Learning Toolbox 神经网络作为 TensorFlow 模型保存在 Python 包中。有关如何加载导出的模型并将其保存为 SavedModel 格式的详细信息,请参阅Load Exported TensorFlow Model和Save TensorFlow Model。
通过使用 ONNX 作为中间格式,您可以与支持 ONNX 模型导出或导入的其他深度学习框架进行互操作。
针对音频应用的预训练的神经网络
Audio Toolbox™ 为预训练音频深度学习网络提供 MATLAB 和 Simulink® 支持。使用预训练网络通过 YAMNet 对声音执行分类,通过 CREPE 估计音高,通过 VGGish 或 OpenL3 提取特征嵌入,并通过 VADNet 执行语音活动检测 (VAD)。您还可以使用深度网络设计器导入和可视化音频预训练神经网络。
使用 audioPretrainedNetwork (Audio Toolbox) 函数加载预训练音频网络。您还可以使用端到端函数之一来处理音频的预处理、网络推断和网络输出的后处理。下表列出了可用的预训练音频神经网络。
audioPretrainedNetwork 模型名称参量 | 神经网络名称 | 预处理和后处理函数 | 端到端函数 | Simulink 模块 |
|---|---|---|---|---|
"yamnet" | YAMNet | yamnetPreprocess (Audio Toolbox) | classifySound (Audio Toolbox) | YAMNet (Audio Toolbox), Sound Classifier (Audio Toolbox) |
"vggish" | VGGish | vggishPreprocess (Audio Toolbox) | vggishEmbeddings (Audio Toolbox) | VGGish (Audio Toolbox), VGGish Embeddings (Audio Toolbox) |
"openl3" | OpenL3 | openl3Preprocess (Audio Toolbox) | openl3Embeddings (Audio Toolbox) | OpenL3 (Audio Toolbox), OpenL3 Embeddings (Audio Toolbox) |
"crepe" | CREPE | crepePreprocess (Audio Toolbox), crepePostprocess (Audio Toolbox) | pitchnn (Audio Toolbox) | CREPE (Audio Toolbox), Deep Pitch Estimator (Audio Toolbox) |
"vadnet" | VADNet | vadnetPreprocess (Audio Toolbox), vadnetPostprocess (Audio Toolbox) | detectspeechnn (Audio Toolbox) | 无 |
有关如何针对新任务调整预训练音频神经网络的示例,请参阅Transfer Learning with Pretrained Audio Networks (Audio Toolbox)和Adapt Pretrained Audio Network for New Data Using Deep Network Designer。
有关在音频应用中使用深度学习的详细信息,请参阅Deep Learning for Audio Applications (Audio Toolbox)。
针对计算机视觉应用的预训练的神经网络
Computer Vision Toolbox™ 为用于目标检测的预训练深度学习网络提供 MATLAB 支持。可使用预训练网络基于测试图像执行开箱即用的推断,或基于自定义数据集执行迁移学习。您还可以使用深度网络设计器导入和可视化用于目标检测的预训练神经网络。
要使用预训练的目标检测网络,请下载并安装所需的支持包。您可以使用附加功能资源管理器下载并安装预训练模型支持包。有关安装附加功能的详细信息,请参阅获取和管理附加功能。
使用目标检测模型(例如 yoloxObjectDetector (Computer Vision Toolbox))指定要用于目标检测的对应预训练网络。要选择目标检测模型,请参阅Choose an Object Detector (Computer Vision Toolbox)。要了解有关对象检测的详细信息,请参阅Get Started with Object Detection Using Deep Learning (Computer Vision Toolbox)。
| 预训练目标检测网络名称参量 | 目标检测模型 | 所需的支持包 |
|---|---|---|
| YOLO v2 - | Computer Vision Toolbox Model for YOLO v2 Object Detection |
| YOLO v3 - | Computer Vision Toolbox Model for YOLO v3 Object Detection |
| YOLO v4 - | Computer Vision Toolbox Model for YOLO v4 Object Detection |
| YOLOX - | Automated Visual Inspection Library for Computer Vision Toolbox |
| RTMDet - | Computer Vision Toolbox Model for RTMDet Object Detection |
GitHub 上的预训练模型
要查找最新预训练模型,请参阅 MATLAB Deep Learning Model Hub。
例如:
对于基于文本的变换器模型,如 GPT-2、BERT 和 FinBERT,请参阅 Transformer Models for MATLAB GitHub® 存储库。
有关预训练 EfficientDet-D0 目标检测模型,请参阅用于目标检测的预训练 EfficientDet 网络 GitHub 存储库。
参考
[1] ImageNet. http://www.image-net.org.
[2] Iandola, Forrest N., Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, and Kurt Keutzer. “SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and <0.5MB Model Size.” Preprint, submitted November 4, 2016. https://arxiv.org/abs/1602.07360.
[3] Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. “Going Deeper with Convolutions.” In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1–9. Boston, MA, USA: IEEE, 2015. https://doi.org/10.1109/CVPR.2015.7298594.
[4] Places. http://places2.csail.mit.edu/
[5] Szegedy, Christian, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. “Rethinking the Inception Architecture for Computer Vision.” In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2818–26. Las Vegas, NV, USA: IEEE, 2016. https://doi.org/10.1109/CVPR.2016.308.
[6] Huang, Gao, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q. Weinberger. “Densely Connected Convolutional Networks.” In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2261–69. Honolulu, HI: IEEE, 2017. https://doi.org/10.1109/CVPR.2017.243.
[7] Sandler, Mark, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. “MobileNetV2: Inverted Residuals and Linear Bottlenecks.” In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4510–20. Salt Lake City, UT: IEEE, 2018. https://doi.org/10.1109/CVPR.2018.00474.
[8] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. “Deep Residual Learning for Image Recognition.” In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–78. Las Vegas, NV, USA: IEEE, 2016. https://doi.org/10.1109/CVPR.2016.90.
[9] Chollet, François. “Xception: Deep Learning with Depthwise Separable Convolutions.” Preprint, submitted in 2016. https://doi.org/10.48550/ARXIV.1610.02357.
[10] Szegedy, Christian, Sergey Ioffe, Vincent Vanhoucke, and Alexander Alemi. “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning.” Proceedings of the AAAI Conference on Artificial Intelligence 31, no. 1 (February 12, 2017). https://doi.org/10.1609/aaai.v31i1.11231.
[11] Zhang, Xiangyu, Xinyu Zhou, Mengxiao Lin, and Jian Sun. “ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices.” Preprint, submitted July 4, 2017. http://arxiv.org/abs/1707.01083.
[12] Zoph, Barret, Vijay Vasudevan, Jonathon Shlens, and Quoc V. Le. “Learning Transferable Architectures for Scalable Image Recognition.” Preprint, submitted in 2017. https://doi.org/10.48550/ARXIV.1707.07012.
[13] Redmon, Joseph. “Darknet: Open Source Neural Networks in C.” https://pjreddie.com/darknet.
[14] Tan, Mingxing, and Quoc V. Le. “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.” Preprint, submitted in 2019. https://doi.org/10.48550/ARXIV.1905.11946.
[15] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "ImageNet Classification with Deep Convolutional Neural Networks." Communications of the ACM 60, no. 6 (May 24, 2017): 84–90. https://doi.org/10.1145/3065386.
[16] Simonyan, Karen, and Andrew Zisserman. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” Preprint, submitted in 2014. https://doi.org/10.48550/ARXIV.1409.1556.
[17] Russakovsky, O., Deng, J., Su, H., et al. “ImageNet Large Scale Visual Recognition Challenge.” International Journal of Computer Vision (IJCV). Vol 115, Issue 3, 2015, pp. 211–252
[18] Zhou, Bolei, Aditya Khosla, Agata Lapedriza, Antonio Torralba, and Aude Oliva. "Places: An image database for deep scene understanding." arXiv preprint arXiv:1610.02055 (2016).
另请参阅
深度网络设计器 | imagePretrainedNetwork | dlnetwork | trainingOptions | trainnet | importNetworkFromTensorFlow | importNetworkFromPyTorch | importNetworkFromONNX | exportNetworkToTensorFlow | exportONNXNetwork
主题
- 在 MATLAB 中进行深度学习
- 使用深度网络设计器为迁移学习准备网络
- 使用预训练网络提取图像特征
- 使用 GoogLeNet 对图像进行分类
- 重新训练神经网络以对新图像进行分类
- 可视化卷积神经网络的特征
- 可视化卷积神经网络的激活
- 使用 GoogLeNet 的 Deep Dream 图像