fitcsvm
训练用于一类和二类分类的支持向量机 (SVM) 分类器
语法
说明
fitcsvm 基于低维或中维预测变量数据集训练或交叉验证一类和二类(二元)分类的支持向量机 (SVM) 模型。fitcsvm 支持使用核函数映射预测变量数据,并支持序列最小优化 (SMO)、迭代单点数据算法 (ISDA) 或 L1 软边距最小化(二次规划目标函数最小化)。
要基于高维数据集(即包含许多预测变量的数据集)训练二类分类线性 SVM 模型,请改用 fitclinear。
对于结合使用二类 SVM 模型的多类学习,请使用纠错输出编码 (ECOC)。有关详细信息,请参阅 fitcecoc。
要训练 SVM 回归模型,请参阅 fitrsvm(适用于低维和中维预测变量数据集)或 fitrlinear(适用于高维数据集)。
Mdl = fitcsvm(Tbl,ResponseVarName)Mdl。该分类器使用表 Tbl 中包含的样本数据进行训练。ResponseVarName 是 Tbl 中变量的名称,该变量包含一类或二类分类的类标签。
如果类标签变量只包含一个类(例如,由 1 组成的向量),fitcsvm 会训练一类分类模型。否则,该函数将训练二类分类模型。
Mdl = fitcsvm(___,Name,Value)
[ 还返回 Mdl,AggregateOptimizationResults] = fitcsvm(___)AggregateOptimizationResults,其中包含指定 OptimizeHyperparameters 和 HyperparameterOptimizationOptions 名称-值参量时的超参数优化结果。您还必须指定 HyperparameterOptimizationOptions 的 ConstraintType 和 ConstraintBounds 选项。您可以使用此语法优化紧凑模型大小而不是交叉验证损失,并执行一组具有相同选项但不同约束边界的多个优化问题。
示例
加载 Fisher 鸢尾花数据集。删除萼片的长度和宽度以及所有观测到的山鸢尾花。
load fisheriris inds = ~strcmp(species,'setosa'); X = meas(inds,3:4); y = species(inds);
使用经过处理的数据集训练 SVM 分类器。
SVMModel = fitcsvm(X,y)
SVMModel =
ClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 100
Alpha: [24×1 double]
Bias: -14.4149
KernelParameters: [1×1 struct]
BoxConstraints: [100×1 double]
ConvergenceInfo: [1×1 struct]
IsSupportVector: [100×1 logical]
Solver: 'SMO'
Properties, Methods
SVMModel 是经过训练的 ClassificationSVM 分类器。您可以查看 SVMModel 的属性。例如,使用圆点表示法查看类顺序。
classOrder = SVMModel.ClassNames
classOrder = 2×1 cell
{'versicolor'}
{'virginica' }
第一个类 ('versicolor') 是负类,第二个类 ('virginica') 是正类。您可以使用 'ClassNames' 名称-值对组参量在训练期间更改类顺序。
绘制数据的散点图并圈出支持向量。
sv = SVMModel.SupportVectors; figure gscatter(X(:,1),X(:,2),y) hold on plot(sv(:,1),sv(:,2),'ko','MarkerSize',10) legend('versicolor','virginica','Support Vector') hold off
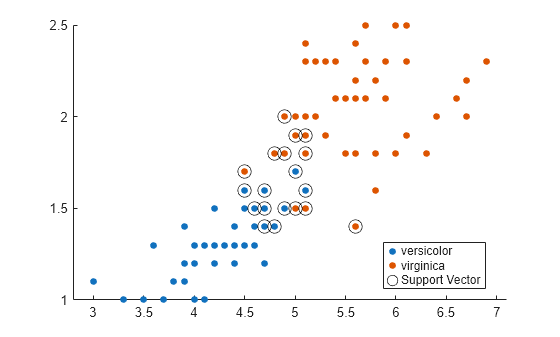
支持向量是发生在其估计的类边界之上或之外的观测值。
您可以使用 'BoxConstraint' 名称-值对组参量在训练过程中设置框约束来调整边界(从而调整支持向量的数量)。
此示例说明如何绘制具有两个预测变量的二类(二元)SVM 分类器的决策边界和边距线。
加载 Fisher 鸢尾花数据集。排除所有杂色鸢尾花品种(仅留下山鸢尾花和海滨鸢尾花品种),仅保留萼片长度和宽度测量值。
load fisheriris; inds = ~strcmp(species,'versicolor'); X = meas(inds,1:2); s = species(inds);
训练线性核 SVM 分类器。
SVMModel = fitcsvm(X,s);
SVMModel 是经过训练的 ClassificationSVM 分类器,其属性包括支持向量、线性预测变量系数和偏置项。
sv = SVMModel.SupportVectors; % Support vectors beta = SVMModel.Beta; % Linear predictor coefficients b = SVMModel.Bias; % Bias term
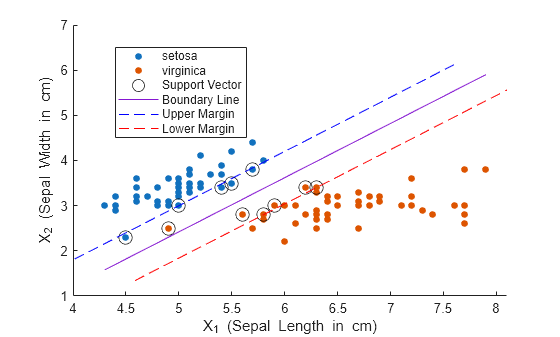
绘制数据的散点图并圈出支持向量。支持向量是发生在其估计的类边界之上或之外的观测值。
hold on gscatter(X(:,1),X(:,2),s) plot(sv(:,1),sv(:,2),'ko','MarkerSize',10)
SVMModel 分类器的最佳分离超平面是由 指定的直线。将两个品种之间的决策边界绘制为一条实线。
X1 = linspace(min(X(:,1)),max(X(:,1)),100);
X2 = -(beta(1)/beta(2)*X1)-b/beta(2);
plot(X1,X2,'-')线性预测变量系数 定义与决策边界正交的向量。最大边距宽度为 (有关详细信息,请参阅用于二类分类的支持向量机)。将最大边距边界绘制为虚线。标记坐标区并添加图例。
m = 1/sqrt(beta(1)^2 + beta(2)^2); % Margin half-width X1margin_low = X1+beta(1)*m^2; X2margin_low = X2+beta(2)*m^2; X1margin_high = X1-beta(1)*m^2; X2margin_high = X2-beta(2)*m^2; plot(X1margin_high,X2margin_high,'b--') plot(X1margin_low,X2margin_low,'r--') xlabel('X_1 (Sepal Length in cm)') ylabel('X_2 (Sepal Width in cm)') legend('setosa','virginica','Support Vector', ... 'Boundary Line','Upper Margin','Lower Margin') hold off
加载 ionosphere 数据集。
load ionosphere rng(1); % For reproducibility
使用径向基核训练 SVM 分类器。让软件计算核函数的缩放值。对预测变量进行标准化。
SVMModel = fitcsvm(X,Y,'Standardize',true,'KernelFunction','RBF',... 'KernelScale','auto');
SVMModel 是经过训练的 ClassificationSVM 分类器。
交叉验证 SVM 分类器。默认情况下,软件使用 10 折交叉验证。
CVSVMModel = crossval(SVMModel);
CVSVMModel 是 ClassificationPartitionedModel 交叉验证的分类器。
估计样本外的误分类率。
classLoss = kfoldLoss(CVSVMModel)
classLoss = 0.0484
泛化率约为 5%。
通过将所有鸢尾花分配给同一个类来修改 Fisher 的鸢尾花数据集。检测修改后的数据集中的离群值,并确认观测值中离群值的预期比例。
加载 Fisher 鸢尾花数据集。删除花瓣的长度和宽度。将所有鸢尾花都视为来自同一个类。
load fisheriris
X = meas(:,1:2);
y = ones(size(X,1),1);使用修改后的数据集训练 SVM 分类器。假设 5% 的观测值是离群值。对预测变量进行标准化。
rng(1); SVMModel = fitcsvm(X,y,'KernelScale','auto','Standardize',true,... 'OutlierFraction',0.05);
SVMModel 是经过训练的 ClassificationSVM 分类器。默认情况下,软件使用高斯核进行一类学习。
绘制观测值和决策边界。标记支持向量和潜在离群值。
svInd = SVMModel.IsSupportVector; h = 0.02; % Mesh grid step size [X1,X2] = meshgrid(min(X(:,1)):h:max(X(:,1)),... min(X(:,2)):h:max(X(:,2))); [~,score] = predict(SVMModel,[X1(:),X2(:)]); scoreGrid = reshape(score,size(X1,1),size(X2,2)); figure plot(X(:,1),X(:,2),'k.') hold on plot(X(svInd,1),X(svInd,2),'ro','MarkerSize',10) contour(X1,X2,scoreGrid) colorbar; title('{\bf Iris Outlier Detection via One-Class SVM}') xlabel('Sepal Length (cm)') ylabel('Sepal Width (cm)') legend('Observation','Support Vector') hold off
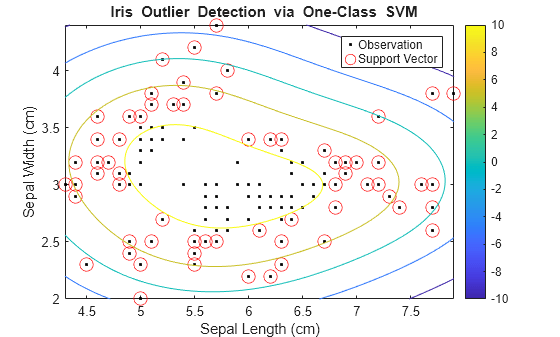
将离群值与其余数据分隔的边界出现在围道值为 0 的位置。
验证交叉验证数据中具有负分数的观测值的比例接近 5%。
CVSVMModel = crossval(SVMModel); [~,scorePred] = kfoldPredict(CVSVMModel); outlierRate = mean(scorePred<0)
outlierRate = 0.0467
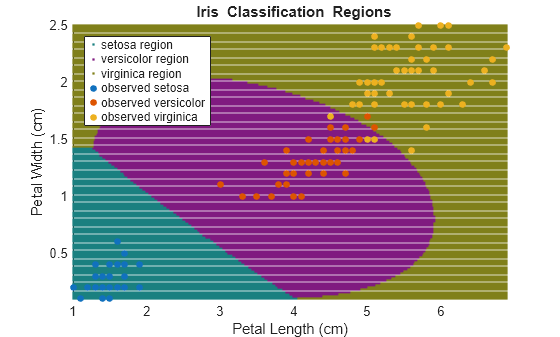
创建 fisheriris 数据集的散点图。将图中网格的坐标点视为来自数据集分布的新观测值,并通过将坐标点分配给数据集中的三个类之一来找出类边界。
加载 Fisher 鸢尾花数据集。使用花瓣长度和宽度作为预测变量。
load fisheriris
X = meas(:,3:4);
Y = species;检查数据的散点图。
figure gscatter(X(:,1),X(:,2),Y); h = gca; lims = [h.XLim h.YLim]; % Extract the x and y axis limits title('{\bf Scatter Diagram of Iris Measurements}'); xlabel('Petal Length (cm)'); ylabel('Petal Width (cm)'); legend('Location','Northwest');
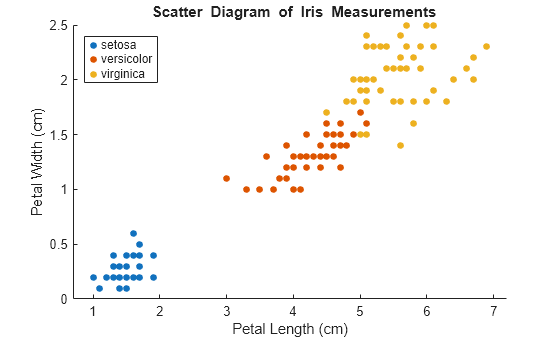
该数据包含三个类,其中一个类与其他类可线性分离。
对于每个类:
创建一个逻辑向量 (
indx),指示观测值是否为该类的成员。使用预测变量数据和
indx训练 SVM 分类器。将该分类器存储在元胞数组的一个元胞中。
定义类顺序。
SVMModels = cell(3,1); classes = unique(Y); rng(1); % For reproducibility for j = 1:numel(classes) indx = strcmp(Y,classes(j)); % Create binary classes for each classifier SVMModels{j} = fitcsvm(X,indx,'ClassNames',[false true],'Standardize',true,... 'KernelFunction','rbf','BoxConstraint',1); end
SVMModels 是 3×1 元胞数组,其中每个元胞包含一个 ClassificationSVM 分类器。对于每个元胞,正类分别是 setosa、versicolor 和 virginica。
在图中定义精细网格,并将坐标点视为来自训练数据分布的新观测值。使用每个分类器估计新观测值的分数。
d = 0.02; [x1Grid,x2Grid] = meshgrid(min(X(:,1)):d:max(X(:,1)),... min(X(:,2)):d:max(X(:,2))); xGrid = [x1Grid(:),x2Grid(:)]; N = size(xGrid,1); Scores = zeros(N,numel(classes)); for j = 1:numel(classes) [~,score] = predict(SVMModels{j},xGrid); Scores(:,j) = score(:,2); % Second column contains positive-class scores end
Scores 的每行包含三个分数。分数最高的元素的索引是新类观测值最可能属于的类的索引。
将每个新观测值与给它最高分数的分类器相关联。
[~,maxScore] = max(Scores,[],2);
基于对应新观测值所属的类,在绘图区域中着色。
figure h(1:3) = gscatter(xGrid(:,1),xGrid(:,2),maxScore,... [0.1 0.5 0.5; 0.5 0.1 0.5; 0.5 0.5 0.1]); hold on h(4:6) = gscatter(X(:,1),X(:,2),Y); title('{\bf Iris Classification Regions}'); xlabel('Petal Length (cm)'); ylabel('Petal Width (cm)'); legend(h,{'setosa region','versicolor region','virginica region',... 'observed setosa','observed versicolor','observed virginica'},... 'Location','Northwest'); axis tight hold off
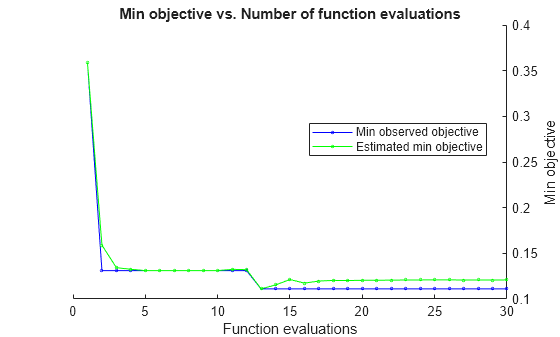
使用 fitcsvm 自动优化超参数。
加载 ionosphere 数据集。
load ionosphere通过使用自动超参数优化,找到最小化五折交叉验证损失的超参数。为了实现可再现性,请设置随机种子并使用 'expected-improvement-plus' 采集函数。
rng default Mdl = fitcsvm(X,Y,'OptimizeHyperparameters','auto', ... 'HyperparameterOptimizationOptions',struct('AcquisitionFunctionName', ... 'expected-improvement-plus'))
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | BoxConstraint| KernelScale | Standardize |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 1 | Best | 0.35897 | 0.21586 | 0.35897 | 0.35897 | 3.8653 | 961.53 | true |
| 2 | Best | 0.12821 | 8.5911 | 0.12821 | 0.15646 | 429.99 | 0.2378 | false |
| 3 | Accept | 0.35897 | 0.071978 | 0.12821 | 0.1315 | 0.11801 | 8.9479 | false |
| 4 | Accept | 0.1339 | 4.2217 | 0.12821 | 0.12965 | 0.0010694 | 0.0032063 | true |
| 5 | Accept | 0.15954 | 10.111 | 0.12821 | 0.12824 | 973.65 | 0.15179 | false |
| 6 | Accept | 0.13675 | 0.16644 | 0.12821 | 0.1283 | 234.28 | 2.8822 | false |
| 7 | Accept | 0.35897 | 0.04513 | 0.12821 | 0.12826 | 0.005253 | 835.53 | true |
| 8 | Accept | 0.14245 | 10.194 | 0.12821 | 0.12829 | 91.176 | 0.042696 | false |
| 9 | Accept | 0.151 | 9.4829 | 0.12821 | 0.12831 | 0.0064316 | 0.0010249 | true |
| 10 | Accept | 0.1339 | 5.0189 | 0.12821 | 0.12835 | 153.27 | 0.38874 | false |
| 11 | Accept | 0.26781 | 10.317 | 0.12821 | 0.12948 | 260.21 | 0.001097 | false |
| 12 | Accept | 0.12821 | 0.21803 | 0.12821 | 0.12935 | 0.0034086 | 0.029311 | true |
| 13 | Best | 0.11966 | 0.072008 | 0.11966 | 0.12144 | 0.0010229 | 0.032368 | true |
| 14 | Accept | 0.35897 | 0.052694 | 0.11966 | 0.12177 | 987.92 | 683.08 | false |
| 15 | Accept | 0.12821 | 0.053089 | 0.11966 | 0.11979 | 0.0010124 | 0.28112 | true |
| 16 | Accept | 0.22792 | 10.006 | 0.11966 | 0.11995 | 6.9606 | 0.001715 | true |
| 17 | Accept | 0.11966 | 0.064647 | 0.11966 | 0.11979 | 0.0010509 | 0.078769 | true |
| 18 | Accept | 0.12251 | 0.054625 | 0.11966 | 0.12049 | 0.0010131 | 0.054019 | true |
| 19 | Accept | 0.1339 | 4.8934 | 0.11966 | 0.12071 | 0.08684 | 0.018067 | true |
| 20 | Accept | 0.11966 | 0.18885 | 0.11966 | 0.12123 | 0.048335 | 0.21846 | true |
|====================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | BoxConstraint| KernelScale | Standardize |
| | result | | runtime | (observed) | (estim.) | | | |
|====================================================================================================================|
| 21 | Accept | 0.11966 | 0.08286 | 0.11966 | 0.12119 | 0.013573 | 0.11789 | true |
| 22 | Accept | 0.1339 | 0.55852 | 0.11966 | 0.12123 | 1.2995 | 0.26436 | true |
| 23 | Accept | 0.1396 | 7.9392 | 0.11966 | 0.12127 | 0.0019603 | 0.0010023 | false |
| 24 | Accept | 0.13675 | 6.5142 | 0.11966 | 0.12136 | 0.17347 | 0.010479 | false |
| 25 | Accept | 0.14245 | 0.1391 | 0.11966 | 0.11914 | 0.0010001 | 0.0076351 | false |
| 26 | Accept | 0.12536 | 0.13991 | 0.11966 | 0.12144 | 0.035903 | 0.11247 | true |
| 27 | Accept | 0.1339 | 3.3223 | 0.11966 | 0.12144 | 897.97 | 1.361 | false |
| 28 | Accept | 0.1339 | 5.0618 | 0.11966 | 0.12146 | 6.6245 | 0.085879 | false |
| 29 | Accept | 0.12251 | 0.090061 | 0.11966 | 0.1214 | 0.0069215 | 0.12029 | true |
| 30 | Accept | 0.12251 | 0.11955 | 0.11966 | 0.12136 | 0.049433 | 0.43143 | true |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 107.0032 seconds
Total objective function evaluation time: 98.0074
Best observed feasible point:
BoxConstraint KernelScale Standardize
_____________ ___________ ___________
0.0010229 0.032368 true
Observed objective function value = 0.11966
Estimated objective function value = 0.12229
Function evaluation time = 0.072008
Best estimated feasible point (according to models):
BoxConstraint KernelScale Standardize
_____________ ___________ ___________
0.013573 0.11789 true
Estimated objective function value = 0.12136
Estimated function evaluation time = 0.098473
Mdl =
ClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 351
HyperparameterOptimizationResults: [1×1 BayesianOptimization]
Alpha: [90×1 double]
Bias: -0.1318
KernelParameters: [1×1 struct]
Mu: [0.8917 0 0.6413 0.0444 0.6011 0.1159 0.5501 0.1194 0.5118 0.1813 0.4762 0.1550 0.4008 0.0934 0.3442 0.0711 0.3819 -0.0036 0.3594 -0.0240 0.3367 0.0083 0.3625 -0.0574 0.3961 -0.0712 0.5416 -0.0695 … ] (1×34 double)
Sigma: [0.3112 0 0.4977 0.4414 0.5199 0.4608 0.4927 0.5207 0.5071 0.4839 0.5635 0.4948 0.6222 0.4949 0.6528 0.4584 0.6180 0.4968 0.6263 0.5191 0.6098 0.5182 0.6038 0.5275 0.5785 0.5085 0.5162 0.5500 0.5759 … ] (1×34 double)
BoxConstraints: [351×1 double]
ConvergenceInfo: [1×1 struct]
IsSupportVector: [351×1 logical]
Solver: 'SMO'
Properties, Methods
输入参数
名称-值参数
输出参量
限制
fitcsvm为一类或二类学习应用训练 SVM 分类器。要使用就有两个以上类的数据训练 SVM 分类器,请使用fitcecoc。fitcsvm支持低维和中维数据集。对于高维数据集,请改用fitclinear。
详细信息
提示
除非您的数据集很大,否则请始终尝试标准化预测变量(请参阅
Standardize)。标准化可使预测变量不受其测量尺度的影响。使用
KFold名称-值对组参量进行交叉验证是很好的做法。交叉验证结果决定 SVM 分类器的泛化能力。对于一类学习:
支持向量中的稀疏性是 SVM 分类器的一个理想属性。要减少支持向量的数量,可将
BoxConstraint设置为较大的值。此操作会增加训练时间。为了获得最佳训练时间,请将
CacheSize设置为计算机允许的最大内存限制。如果您期望支持向量比训练集中的观测值少得多,则您可以使用名称-值对组参量
'ShrinkagePeriod'缩小活动集,从而显著加快收敛速度。指定'ShrinkagePeriod',1000是很好的做法。远离决策边界的重复观测值不影响收敛。然而,决策边界附近出现的少数几个重复的观测值可能会大幅减慢收敛速度。在以下情况下,要加快收敛速度,请指定
'RemoveDuplicates',true:您的数据集包含许多重复的观测值。
您怀疑有几个重复的观测值接近决策边界。
要在训练期间保留原始数据集,
fitcsvm必须临时分别存储两个数据集:原始数据集和没有重复观测值的数据集。因此,如果您为包含少量重复观测值的数据集指定true,则fitcsvm消耗的内存将接近原始数据的两倍。在训练模型后,您可以生成预测新数据标签的 C/C++ 代码。生成 C/C++ 代码需要 MATLAB Coder™。有关详细信息,请参阅Introduction to Code Generation for Statistics and Machine Learning Functions。
算法
有关 SVM 二类分类算法的数学公式,请参阅用于二类分类的支持向量机和了解支持向量机。
NaN、<undefined>、空字符向量 ('')、空字符串 ("") 和<missing>值表示缺失值。fitcsvm会删除对应于缺失响应的整行数据。在计算总权重时(请参阅下几项内容),如果某权重所对应的观测值至少具有一个缺失变量,则fitcsvm忽略该权重。此操作会导致平衡类问题中出现不平衡的先验概率。因此,观测值框约束可能不等于BoxConstraint。如果您指定
Cost、Prior和Weights名称-值参量,则输出模型对象会将指定的值分别存储在Cost、Prior和W属性中。Cost属性存储用户指定的代价矩阵 (C),无需进行任何修改。Prior和W属性分别存储归一化后的先验概率和观测值权重。对于模型训练,软件会更新先验概率和观测值权重,以纳入代价矩阵中所述的罚分。有关详细信息,请参阅Misclassification Cost Matrix, Prior Probabilities, and Observation Weights。请注意,
Cost和Prior名称-值参量用于二类学习。对于一类学习,Cost和Prior属性分别存储0和1。对于二类学习,
fitcsvm为训练数据中的每个观测值指定一个框约束。观测值 j 的框约束的公式是,其中 C0 是初始框约束(请参阅
BoxConstraint名称-值参量),而 wj* 是观测值 j 的由Cost和Prior调整的观测值权重。有关观测值权重的详细信息,请参阅Adjust Prior Probabilities and Observation Weights for Misclassification Cost Matrix。如果您将
Standardize指定为true并设置Cost、Prior或Weights名称-值参量,则fitcsvm会使用对应于预测变量的加权均值和加权标准差对预测变量进行标准化。也就是说,fitcsvm使用标准化预测变量 j(xj,其中 xjk 是预测变量 j(列)的观测值 k(行),且
假设
p是您预期在训练数据中的离群值比例,并且您设置了'OutlierFraction',p。对于一类学习,软件会训练偏差项,使得训练数据中 100
p% 的观测值具有负分数。对于二类学习,软件会实施稳健学习。换句话说,当优化算法收敛时,软件会尝试删除 100
p% 的观测值。删除的观测值对应于幅值较大的梯度。
如果预测变量数据包含分类变量,则软件通常会对这些变量进行完全虚拟变量编码。软件为每个分类变量的每个水平创建一个虚拟变量。
PredictorNames属性为每个原始预测变量名称存储一个元素。例如,假设有三个预测变量,其中一个是具有三个水平的分类变量。那么PredictorNames是 1×3 个字符向量元胞数组,其中包含预测变量的原始名称。ExpandedPredictorNames属性为每个预测变量(包括虚拟变量)存储一个元素。例如,假设有三个预测变量,其中一个是具有三个水平的分类变量。那么ExpandedPredictorNames就是 1×5 字符向量数组,其中包含预测变量和新虚拟变量的名称。同样,
Beta属性为每个预测变量(包括虚拟变量)存储一个 beta 系数。SupportVectors属性存储支持向量的预测变量值,包括虚拟变量。例如,假设有 m 个支持向量和三个预测变量,其中一个预测变量是具有三个水平的分类变量。那么SupportVectors就是 n×5 矩阵。X属性将训练数据存储为原始输入,不包括虚拟变量。当输入为表时,X仅包含用作预测变量的列。
对于表中指定的预测变量,如果任何变量包含经过排序的(有序)类别,软件会对这些变量使用有序编码。
对于具有 k 个有序水平的变量,软件会创建 k – 1 个虚拟变量。在第 j 个虚拟变量中,前 j 个水平的对应值为 –1;从 j + 1 至 k 的水平的对应值为 +1。
存储在
ExpandedPredictorNames属性中的虚拟变量的名称使用值 +1 指示第一个水平。软件会为虚拟变量另外存储 k – 1 个预测变量名称,包括水平 2、3、...、k 的名称。
所有求解器都实现 L1 软边距最小化算法。
对于一类学习,软件估计拉格朗日乘数 α1、...、αn,满足
替代功能
您还可以使用 ocsvm 函数来训练用于异常检测的一类 SVM 模型。
与
fitcsvm函数相比,ocsvm函数针对异常检测提供的首选工作流更简单。ocsvm函数返回OneClassSVM对象、异常指标和异常分数。您可以使用输出来识别训练数据中的异常。要找出新数据中的异常,可以使用OneClassSVM的isanomaly对象函数。isanomaly函数返回新数据的异常指标和分数。fitcsvm函数支持一类和二类分类。如果类标签变量只包含一个类(例如,由 1 组成的向量),fitcsvm会训练一类分类模型并返回ClassificationSVM对象。要识别异常,您必须首先使用ClassificationSVM的resubPredict或predict对象函数计算异常分数,然后通过找出具有负分数的观测值来识别异常。请注意,大的正异常分数表示
ocsvm中存在异常,而负分数表示ClassificationSVM的predict中存在异常。
ocsvm函数基于 SVM 的原问题形式找到决策边界,而fitcsvm函数基于 SVM 的对偶问题形式找到决策边界。对于大型数据集(大型 n),
ocsvm中求解器的计算开销低于fitcsvm中的求解器。与fitcsvm中需要计算 n×n格拉姆矩阵的求解器不同,ocsvm中的求解器只需形成大小为 n×m 的矩阵。此处,m 是扩展空间的维数,对于大数据来说,此维数通常远远小于 n。
参考
扩展功能
版本历史记录
在 R2014a 中推出另请参阅
ClassificationSVM | CompactClassificationSVM | ClassificationPartitionedModel | predict | fitSVMPosterior | rng | quadprog (Optimization Toolbox) | fitcecoc | fitclinear | ocsvm