fitcecoc
Fit multiclass models for support vector machines or other classifiers
Syntax
Description
Mdl = fitcecoc(Tbl,ResponseVarName)Tbl and
the class labels in Tbl.ResponseVarName. fitcecoc uses K(K –
1)/2 binary support vector machine (SVM) models using the one-versus-one coding design, where K is
the number of unique class labels (levels). Mdl is
a ClassificationECOC model.
Mdl = fitcecoc(___,Name,Value)Name,Value pair
arguments, using any of the previous syntaxes.
For example, specify different binary learners, a different
coding design, or to cross-validate. It is good practice to cross-validate
using the Kfold Name,Value pair
argument. The cross-validation results determine how well the model
generalizes.
[ also returns
hyperparameter optimization results when you specify
Mdl,HyperparameterOptimizationResults]
= fitcecoc(___,Name,Value)OptimizeHyperparameters and either of the following
conditions apply:
You specify
Learners="linear"orLearners="kernel".HyperparameterOptimizationResultsis aSupervisedLearningBayesianOptimizationobject.You specify
HyperparameterOptimizationOptionsand set theConstraintTypeandConstraintBoundsoptions.HyperparameterOptimizationResultsis anAggregateBayesianOptimizationobject. You can choose to optimize on compact model size or cross-validation loss, and to perform a set of multiple optimization problems that have the same options but different constraint bounds.
When you specify OptimizeHyperparameters
and neither of these conditions apply, the output
HyperparameterOptimizationResults is
[] and, instead, the
HyperparameterOptimizationResults property of
Mdl contains the results.
Note
For a list of supported syntaxes when the input variables are tall arrays, see Tall Arrays.
Examples
Train a multiclass error-correcting output codes (ECOC) model using support vector machine (SVM) binary learners.
Load Fisher's iris data set. Specify the predictor data X and the response data Y.
load fisheriris
X = meas;
Y = species;Train a multiclass ECOC model using the default options.
Mdl = fitcecoc(X,Y)
Mdl =
ClassificationECOC
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3×1 cell}
CodingName: 'onevsone'
Properties, Methods
Mdl is a ClassificationECOC model. By default, fitcecoc uses SVM binary learners and a one-versus-one coding design. You can access Mdl properties using dot notation.
Display the class names and the coding design matrix.
Mdl.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
CodingMat = Mdl.CodingMatrix
CodingMat = 3×3
1 1 0
-1 0 1
0 -1 -1
A one-versus-one coding design for three classes yields three binary learners. The columns of CodingMat correspond to the learners, and the rows correspond to the classes. The class order is the same as the order in Mdl.ClassNames. For example, CodingMat(:,1) is [1; –1; 0] and indicates that the software trains the first SVM binary learner using all observations classified as 'setosa' and 'versicolor'. Because 'setosa' corresponds to 1, it is the positive class; 'versicolor' corresponds to –1, so it is the negative class.
You can access each binary learner using cell indexing and dot notation.
Mdl.BinaryLearners{1} % The first binary learnerans =
CompactClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [-1 1]
ScoreTransform: 'none'
Beta: [4×1 double]
Bias: 1.4492
KernelParameters: [1×1 struct]
Properties, Methods
Compute the resubstitution classification error.
error = resubLoss(Mdl)
error = 0.0067
The classification error on the training data is small, but the classifier might be an overfitted model. You can cross-validate the classifier using crossval and compute the cross-validation classification error instead.
Create a default linear learner template, and then use it to train an ECOC model containing multiple binary linear classification models.
Load the NLP data set.
load nlpdataX is a sparse matrix of predictor data, and Y is a categorical vector of class labels. The data contains 13 classes.
Create a default linear learner template.
t = templateLinear
t =
Fit template for Linear.
Learner: 'svm'
t is a template object for a linear learner. All of the properties of t are empty. When you pass t to a training function, such as fitcecoc for ECOC multiclass classification, the software sets the empty properties to their respective default values. For example, the software sets Type to "classification". To modify the default values see the name-value arguments for templateLinear.
Train an ECOC model consisting of multiple binary linear classification models that identify the software product given the frequency distribution of words on a documentation web page. For faster training time, transpose the predictor data, and specify that observations correspond to columns.
X = X'; rng(1); % For reproducibility Mdl = fitcecoc(X,Y,'Learners',t,'ObservationsIn','columns')
Mdl =
CompactClassificationECOC
ResponseName: 'Y'
ClassNames: [comm dsp ecoder fixedpoint hdlcoder phased physmod simulink stats supportpkg symbolic vision xpc]
ScoreTransform: 'none'
BinaryLearners: {78×1 cell}
CodingMatrix: [13×78 double]
Properties, Methods
Alternatively, you can train an ECOC model containing default linear classification models by specifying "Learners","Linear".
To conserve memory, fitcecoc returns trained ECOC models containing linear classification learners in CompactClassificationECOC model objects.
Cross-validate an ECOC classifier with SVM binary learners, and estimate the generalized classification error.
Load Fisher's iris data set. Specify the predictor data X and the response data Y.
load fisheriris X = meas; Y = species; rng(1); % For reproducibility
Create an SVM template, and standardize the predictors.
t = templateSVM('Standardize',true)t =
Fit template for SVM.
Standardize: 1
t is an SVM template. Most of the template object properties are empty. When training the ECOC classifier, the software sets the applicable properties to their default values.
Train the ECOC classifier, and specify the class order.
Mdl = fitcecoc(X,Y,'Learners',t,... 'ClassNames',{'setosa','versicolor','virginica'});
Mdl is a ClassificationECOC classifier. You can access its properties using dot notation.
Cross-validate Mdl using 10-fold cross-validation.
CVMdl = crossval(Mdl);
CVMdl is a ClassificationPartitionedECOC cross-validated ECOC classifier.
Estimate the generalized classification error.
genError = kfoldLoss(CVMdl)
genError = 0.0400
The generalized classification error is 4%, which indicates that the ECOC classifier generalizes fairly well.
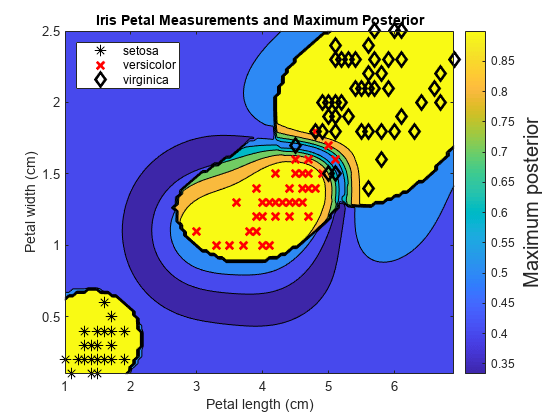
Train an ECOC classifier using SVM binary learners. First predict the training-sample labels and class posterior probabilities. Then predict the maximum class posterior probability at each point in a grid. Visualize the results.
Load Fisher's iris data set. Specify the petal dimensions as the predictors and the species names as the response.
load fisheriris X = meas(:,3:4); Y = species; rng(1); % For reproducibility
Create an SVM template. Standardize the predictors, and specify the Gaussian kernel.
t = templateSVM('Standardize',true,'KernelFunction','gaussian');
t is an SVM template. Most of its properties are empty. When the software trains the ECOC classifier, it sets the applicable properties to their default values.
Train the ECOC classifier using the SVM template. Transform classification scores to class posterior probabilities (which are returned by predict or resubPredict) using the 'FitPosterior' name-value pair argument. Specify the class order using the 'ClassNames' name-value pair argument. Display diagnostic messages during training by using the 'Verbose' name-value pair argument.
Mdl = fitcecoc(X,Y,'Learners',t,'FitPosterior',true,... 'ClassNames',{'setosa','versicolor','virginica'},... 'Verbose',2);
Training binary learner 1 (SVM) out of 3 with 50 negative and 50 positive observations. Negative class indices: 2 Positive class indices: 1 Fitting posterior probabilities for learner 1 (SVM). Training binary learner 2 (SVM) out of 3 with 50 negative and 50 positive observations. Negative class indices: 3 Positive class indices: 1 Fitting posterior probabilities for learner 2 (SVM). Training binary learner 3 (SVM) out of 3 with 50 negative and 50 positive observations. Negative class indices: 3 Positive class indices: 2 Fitting posterior probabilities for learner 3 (SVM).
Mdl is a ClassificationECOC model. The same SVM template applies to each binary learner, but you can adjust options for each binary learner by passing in a cell vector of templates.
Predict the training-sample labels and class posterior probabilities. Display diagnostic messages during the computation of labels and class posterior probabilities by using the 'Verbose' name-value pair argument.
[label,~,~,Posterior] = resubPredict(Mdl,'Verbose',1);Predictions from all learners have been computed. Loss for all observations has been computed. Computing posterior probabilities...
Mdl.BinaryLoss
ans = 'quadratic'
The software assigns an observation to the class that yields the smallest average binary loss. Because all binary learners are computing posterior probabilities, the binary loss function is quadratic.
Display a random set of results.
idx = randsample(size(X,1),10,1); Mdl.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
table(Y(idx),label(idx),Posterior(idx,:),... 'VariableNames',{'TrueLabel','PredLabel','Posterior'})
ans=10×3 table
TrueLabel PredLabel Posterior
______________ ______________ ______________________________________
{'virginica' } {'virginica' } 0.0039319 0.0039866 0.99208
{'virginica' } {'virginica' } 0.017066 0.018262 0.96467
{'virginica' } {'virginica' } 0.014947 0.015855 0.9692
{'versicolor'} {'versicolor'} 2.2197e-14 0.87318 0.12682
{'setosa' } {'setosa' } 0.999 0.00025091 0.00074639
{'versicolor'} {'virginica' } 2.2195e-14 0.059427 0.94057
{'versicolor'} {'versicolor'} 2.2194e-14 0.97002 0.029984
{'setosa' } {'setosa' } 0.999 0.0002499 0.00074741
{'versicolor'} {'versicolor'} 0.0085638 0.98259 0.0088482
{'setosa' } {'setosa' } 0.999 0.00025013 0.00074718
The columns of Posterior correspond to the class order of Mdl.ClassNames.
Define a grid of values in the observed predictor space. Predict the posterior probabilities for each instance in the grid.
xMax = max(X); xMin = min(X); x1Pts = linspace(xMin(1),xMax(1)); x2Pts = linspace(xMin(2),xMax(2)); [x1Grid,x2Grid] = meshgrid(x1Pts,x2Pts); [~,~,~,PosteriorRegion] = predict(Mdl,[x1Grid(:),x2Grid(:)]);
For each coordinate on the grid, plot the maximum class posterior probability among all classes.
contourf(x1Grid,x2Grid,... reshape(max(PosteriorRegion,[],2),size(x1Grid,1),size(x1Grid,2))); h = colorbar; h.YLabel.String = 'Maximum posterior'; h.YLabel.FontSize = 15; hold on gh = gscatter(X(:,1),X(:,2),Y,'krk','*xd',8); gh(2).LineWidth = 2; gh(3).LineWidth = 2; title('Iris Petal Measurements and Maximum Posterior') xlabel('Petal length (cm)') ylabel('Petal width (cm)') axis tight legend(gh,'Location','NorthWest') hold off
Train a one-versus-all ECOC classifier using a GentleBoost ensemble of decision trees with surrogate splits. To speed up training, bin numeric predictors and use parallel computing. Binning is valid only when fitcecoc uses a tree learner. After training, estimate the classification error using 10-fold cross-validation. Note that parallel computing requires Parallel Computing Toolbox™.
Load Sample Data
Load and inspect the arrhythmia data set.
load arrhythmia
[n,p] = size(X)n = 452
p = 279
isLabels = unique(Y); nLabels = numel(isLabels)
nLabels = 13
tabulate(categorical(Y))
Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
The data set contains 279 predictors, and the sample size of 452 is relatively small. Of the 16 distinct labels, only 13 are represented in the response (Y). Each label describes various degrees of arrhythmia, and 54.20% of the observations are in class 1.
Train One-Versus-All ECOC Classifier
Create an ensemble template. You must specify at least three arguments: a method, a number of learners, and the type of learner. For this example, specify 'GentleBoost' for the method, 100 for the number of learners, and a decision tree template that uses surrogate splits because there are missing observations.
tTree = templateTree('surrogate','on'); tEnsemble = templateEnsemble('GentleBoost',100,tTree);
tEnsemble is a template object. Most of its properties are empty, but the software fills them with their default values during training.
Train a one-versus-all ECOC classifier using the ensembles of decision trees as binary learners. To speed up training, use binning and parallel computing.
Binning (
'NumBins',50) — When you have a large training data set, you can speed up training (a potential decrease in accuracy) by using the'NumBins'name-value pair argument. This argument is valid only whenfitcecocuses a tree learner. If you specify the'NumBins'value, then the software bins every numeric predictor into a specified number of equiprobable bins, and then grows trees on the bin indices instead of the original data. You can try'NumBins',50first, and then change the'NumBins'value depending on the accuracy and training speed.Parallel computing (
'Options',statset('UseParallel',true)) — With a Parallel Computing Toolbox license, you can speed up the computation by using parallel computing, which sends each binary learner to a worker in the pool. The number of workers depends on your system configuration. When you use decision trees for binary learners,fitcecocparallelizes training using Intel® Threading Building Blocks (TBB) for dual-core systems and above. Therefore, specifying the'UseParallel'option is not helpful on a single computer. Use this option on a cluster.
Additionally, specify that the prior probabilities are 1/K, where K = 13 is the number of distinct classes.
options = statset('UseParallel',true); Mdl = fitcecoc(X,Y,'Coding','onevsall','Learners',tEnsemble,... 'Prior','uniform','NumBins',50,'Options',options);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
Mdl is a ClassificationECOC model.
Cross-Validation
Cross-validate the ECOC classifier using 10-fold cross-validation.
CVMdl = crossval(Mdl,'Options',options);Warning: One or more folds do not contain points from all the groups.
CVMdl is a ClassificationPartitionedECOC model. The warning indicates that some classes are not represented while the software trains at least one fold. Therefore, those folds cannot predict labels for the missing classes. You can inspect the results of a fold using cell indexing and dot notation. For example, access the results of the first fold by entering CVMdl.Trained{1}.
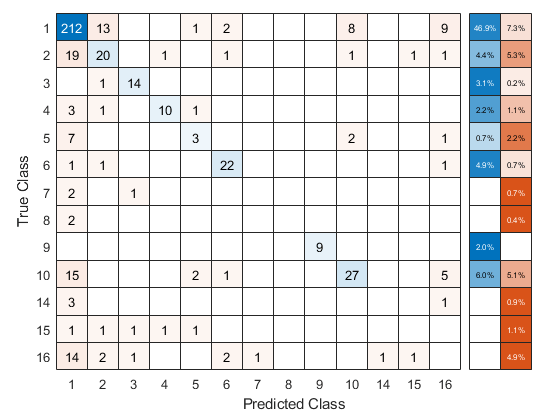
Use the cross-validated ECOC classifier to predict validation-fold labels. You can compute the confusion matrix by using confusionchart. Move and resize the chart by changing the inner position property to ensure that the percentages appear in the row summary.
oofLabel = kfoldPredict(CVMdl,'Options',options); ConfMat = confusionchart(Y,oofLabel,'RowSummary','total-normalized'); ConfMat.InnerPosition = [0.10 0.12 0.85 0.85];
Reproduce Binned Data
Reproduce binned predictor data by using the BinEdges property of the trained model and the discretize function.
X = Mdl.X; % Predictor data Xbinned = zeros(size(X)); edges = Mdl.BinEdges; % Find indices of binned predictors. idxNumeric = find(~cellfun(@isempty,edges)); if iscolumn(idxNumeric) idxNumeric = idxNumeric'; end for j = idxNumeric x = X(:,j); % Convert x to array if x is a table. if istable(x) x = table2array(x); end % Group x into bins by using the discretize function. xbinned = discretize(x,[-inf; edges{j}; inf]); Xbinned(:,j) = xbinned; end
Xbinned contains the bin indices, ranging from 1 to the number of bins, for numeric predictors. Xbinned values are 0 for categorical predictors. If X contains NaNs, then the corresponding Xbinned values are NaNs.
Automatically optimize hyperparameters of an ECOC classifier by using fitcecoc.
Load the fisheriris data set.
load fisheriris
X = meas;
Y = species;Find hyperparameters that minimize the 5-fold cross-validation loss by using automatic hyperparameter optimization. For reproducibility, set the random seed and use the "expected-improvement-plus" acquisition function.
rng(0,"twister") hpoOptions = hyperparameterOptimizationOptions(AcquisitionFunctionName="expected-improvement-plus"); Mdl = fitcecoc(X,Y,OptimizeHyperparameters="auto", ... HyperparameterOptimizationOptions=hpoOptions)
|===================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Coding | BoxConstraint| KernelScale | Standardize |
| | result | | runtime | (observed) | (estim.) | | | | |
|===================================================================================================================================|
| 1 | Best | 0.3 | 9.2477 | 0.3 | 0.3 | onevsall | 76.389 | 0.0012205 | true |
| 2 | Best | 0.10667 | 0.15002 | 0.10667 | 0.1204 | onevsone | 0.0013787 | 41.108 | false |
| 3 | Best | 0.04 | 0.50859 | 0.04 | 0.135 | onevsall | 16.632 | 0.18987 | false |
| 4 | Accept | 0.046667 | 0.12768 | 0.04 | 0.079094 | onevsone | 0.04843 | 0.0042504 | true |
| 5 | Accept | 0.046667 | 0.66572 | 0.04 | 0.040197 | onevsall | 15.204 | 0.15933 | false |
| 6 | Accept | 0.08 | 0.069965 | 0.04 | 0.043201 | onevsall | 77.055 | 4.7599 | false |
| 7 | Accept | 0.16 | 5.0332 | 0.04 | 0.04347 | onevsall | 0.037396 | 0.0010042 | false |
| 8 | Accept | 0.046667 | 0.078502 | 0.04 | 0.043477 | onevsone | 0.0041486 | 0.32592 | true |
| 9 | Accept | 0.046667 | 0.10601 | 0.04 | 0.043118 | onevsone | 4.6545 | 0.041226 | true |
| 10 | Accept | 0.16667 | 0.069994 | 0.04 | 0.043001 | onevsone | 0.0030987 | 300.86 | true |
| 11 | Accept | 0.046667 | 2.0526 | 0.04 | 0.042997 | onevsone | 128.38 | 0.005555 | false |
| 12 | Accept | 0.046667 | 0.074196 | 0.04 | 0.043207 | onevsone | 0.081215 | 0.11353 | false |
| 13 | Accept | 0.33333 | 0.074429 | 0.04 | 0.043431 | onevsall | 243.89 | 987.69 | true |
| 14 | Accept | 0.14 | 2.0366 | 0.04 | 0.043265 | onevsone | 27.177 | 0.0010036 | true |
| 15 | Accept | 0.04 | 0.076787 | 0.04 | 0.040139 | onevsone | 0.0011464 | 0.001003 | false |
| 16 | Accept | 0.046667 | 0.089453 | 0.04 | 0.040165 | onevsone | 0.0010135 | 0.021485 | true |
| 17 | Accept | 0.046667 | 1.2196 | 0.04 | 0.040381 | onevsone | 0.42331 | 0.0010054 | false |
| 18 | Accept | 0.14 | 6.1481 | 0.04 | 0.04025 | onevsall | 956.72 | 0.053616 | false |
| 19 | Accept | 0.26667 | 0.070879 | 0.04 | 0.04023 | onevsall | 0.058487 | 1.2227 | false |
| 20 | Best | 0.04 | 0.072515 | 0.04 | 0.039873 | onevsone | 0.79359 | 1.4535 | true |
|===================================================================================================================================|
| Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Coding | BoxConstraint| KernelScale | Standardize |
| | result | | runtime | (observed) | (estim.) | | | | |
|===================================================================================================================================|
| 21 | Accept | 0.04 | 0.076734 | 0.04 | 0.039837 | onevsone | 8.8581 | 1.123 | false |
| 22 | Accept | 0.04 | 0.069571 | 0.04 | 0.039802 | onevsone | 755.56 | 21.24 | false |
| 23 | Accept | 0.10667 | 0.076388 | 0.04 | 0.039824 | onevsone | 41.541 | 966.05 | false |
| 24 | Accept | 0.04 | 0.09998 | 0.04 | 0.039764 | onevsone | 966.21 | 0.33603 | false |
| 25 | Accept | 0.39333 | 7.5636 | 0.04 | 0.040001 | onevsall | 11.928 | 0.001094 | false |
| 26 | Accept | 0.04 | 0.075486 | 0.04 | 0.039986 | onevsone | 0.12946 | 0.092435 | true |
| 27 | Accept | 0.04 | 0.075959 | 0.04 | 0.039984 | onevsone | 6.8428 | 0.039038 | false |
| 28 | Accept | 0.04 | 0.07371 | 0.04 | 0.039983 | onevsone | 0.0010014 | 0.019004 | false |
| 29 | Accept | 0.04 | 0.068429 | 0.04 | 0.039985 | onevsone | 194.14 | 1.8004 | true |
| 30 | Accept | 0.046667 | 0.067375 | 0.04 | 0.039985 | onevsone | 769.43 | 141.77 | true |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 43.9106 seconds
Total objective function evaluation time: 36.2198
Best observed feasible point:
Coding BoxConstraint KernelScale Standardize
________ _____________ ___________ ___________
onevsone 0.79359 1.4535 true
Observed objective function value = 0.04
Estimated objective function value = 0.040004
Function evaluation time = 0.072515
Best estimated feasible point (according to models):
Coding BoxConstraint KernelScale Standardize
________ _____________ ___________ ___________
onevsone 0.12946 0.092435 true
Estimated objective function value = 0.039985
Estimated function evaluation time = 0.07549

Mdl =
ClassificationECOC
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3×1 cell}
CodingName: 'onevsone'
HyperparameterOptimizationResults: [1×1 classreg.learning.paramoptim.SupervisedLearningBayesianOptimization]
Properties, Methods
The trained classifier Mdl corresponds to the best estimated feasible point and uses the same hyperparameter values for Coding, BoxConstraint, KernelScale, and Standardize.
Find the hyperparameter values used to train Mdl by using the bestPoint function. By default, bestPoint uses the same best point criterion used by fitcecoc during the hyperparameter optimization ("min-visited-upper-confidence-interval"). In general, fit functions determine the best hyperparameter values based on the "min-visited-upper-confidence-interval" criterion (instead of the "min-observed" criterion) to avoid overfitting to noise in the data set.
bestEstimatedPoint = bestPoint(Mdl.HyperparameterOptimizationResults)
bestEstimatedPoint=1×4 table
Coding BoxConstraint KernelScale Standardize
________ _____________ ___________ ___________
onevsone 0.12946 0.092435 true
Verify that the results match the properties of Mdl and its binary learners. Note that the template for the SVM binary learners contains a StandardizeData value instead of a Standardize value, but the two options are equivalent.
coding = Mdl.ModelParameters.Coding
coding = 'onevsone'
binaryLearnerProperties = Mdl.ModelParameters.BinaryLearners
binaryLearnerProperties =
Fit template for classification SVM.
Alpha: [0×1 double]
BoxConstraint: 0.1295
CacheSize: []
CachingMethod: ''
ClipAlphas: []
DeltaGradientTolerance: []
Epsilon: []
GapTolerance: []
KKTTolerance: []
IterationLimit: []
KernelFunction: ''
KernelScale: 0.0924
KernelOffset: []
KernelPolynomialOrder: []
NumPrint: []
Nu: []
OutlierFraction: []
RemoveDuplicates: []
ShrinkagePeriod: []
Solver: ''
StandardizeData: 1
SaveSupportVectors: 0
VerbosityLevel: []
Version: 2
Method: 'SVM'
Type: 'classification'
Create two multiclass ECOC models trained on tall data. Use linear binary learners for one of the models and kernel binary learners for the other. Compare the resubstitution classification error of the two models.
In general, you can perform multiclass classification of tall data by using fitcecoc with linear or kernel binary learners. When you use fitcecoc to train a model on tall arrays, you cannot use SVM binary learners directly. However, you can use either linear or kernel binary classification models that use SVMs.
When you perform calculations on tall arrays, MATLAB® uses either a parallel pool (default if you have Parallel Computing Toolbox™) or the local MATLAB session. If you want to run the example using the local MATLAB session when you have Parallel Computing Toolbox, you can change the global execution environment by using the mapreducer function.
Create a datastore that references the folder containing Fisher's iris data set. Specify 'NA' values as missing data so that datastore replaces them with NaN values. Create tall versions of the predictor and response data.
ds = datastore('fisheriris.csv','TreatAsMissing','NA'); t = tall(ds);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
X = [t.SepalLength t.SepalWidth t.PetalLength t.PetalWidth]; Y = t.Species;
Standardize the predictor data.
Z = zscore(X);
Train a multiclass ECOC model that uses tall data and linear binary learners. By default, when you pass tall arrays to fitcecoc, the software trains linear binary learners that use SVMs. Because the response data contains only three unique classes, change the coding scheme from one-versus-all (which is the default when you use tall data) to one-versus-one (which is the default when you use in-memory data).
For reproducibility, set the seeds of the random number generators using rng and tallrng. The results can vary depending on the number of workers and the execution environment for the tall arrays. For details, see Control Where Your Code Runs.
rng('default') tallrng('default') mdlLinear = fitcecoc(Z,Y,'Coding','onevsone')
Training binary learner 1 (Linear) out of 3. Training binary learner 2 (Linear) out of 3. Training binary learner 3 (Linear) out of 3.
mdlLinear =
CompactClassificationECOC
ResponseName: 'Y'
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3×1 cell}
CodingMatrix: [3×3 double]
Properties, Methods
mdlLinear is a CompactClassificationECOC model composed of three binary learners.
Train a multiclass ECOC model that uses tall data and kernel binary learners. First, create a templateKernel object to specify the properties of the kernel binary learners; in particular, increase the number of expansion dimensions to .
tKernel = templateKernel('NumExpansionDimensions',2^16)tKernel =
Fit template for classification Kernel.
BetaTolerance: []
BlockSize: []
BoxConstraint: []
Epsilon: []
NumExpansionDimensions: 65536
GradientTolerance: []
HessianHistorySize: []
IterationLimit: []
KernelScale: []
Lambda: []
Learner: 'svm'
LossFunction: []
Stream: []
VerbosityLevel: []
Version: 1
Method: 'Kernel'
Type: 'classification'
By default, the kernel binary learners use SVMs.
Pass the templateKernel object to fitcecoc and change the coding scheme to one-versus-one.
mdlKernel = fitcecoc(Z,Y,'Learners',tKernel,'Coding','onevsone')
Training binary learner 1 (Kernel) out of 3. Training binary learner 2 (Kernel) out of 3. Training binary learner 3 (Kernel) out of 3.
mdlKernel =
CompactClassificationECOC
ResponseName: 'Y'
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3×1 cell}
CodingMatrix: [3×3 double]
Properties, Methods
mdlKernel is also a CompactClassificationECOC model composed of three binary learners.
Compare the resubstitution classification error of the two models.
errorLinear = gather(loss(mdlLinear,Z,Y))
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 1.4 sec Evaluation completed in 1.6 sec
errorLinear = 0.0333
errorKernel = gather(loss(mdlKernel,Z,Y))
Evaluating tall expression using the Parallel Pool 'local': - Pass 1 of 1: Completed in 15 sec Evaluation completed in 16 sec
errorKernel = 0.0067
mdlKernel misclassifies a smaller percentage of the training data than mdlLinear.
Input Arguments
Name-Value Arguments
Output Arguments
Limitations
fitcecocsupports sparse matrices for training linear classification models only. For all other models, supply a full matrix of predictor data instead.
More About
The coding design is a matrix whose elements direct which classes are trained by each binary learner, that is, how the multiclass problem is reduced to a series of binary problems.
Each row of the coding design corresponds to a distinct class, and each column corresponds to a binary learner. In a ternary coding design, for a particular column (or binary learner):
A row containing 1 directs the binary learner to group all observations in the corresponding class into a positive class.
A row containing –1 directs the binary learner to group all observations in the corresponding class into a negative class.
A row containing 0 directs the binary learner to ignore all observations in the corresponding class.
Coding design matrices with large, minimal, pairwise row distances based on the Hamming measure are optimal. For details on the pairwise row distance, see Random Coding Design Matrices and [3].
This table describes popular coding designs.
| Coding Design | Description | Number of Learners | Minimal Pairwise Row Distance |
|---|---|---|---|
| one-versus-all (OVA) | For each binary learner, one class is positive and the rest are negative. This design exhausts all combinations of positive class assignments. | K | 2 |
| one-versus-one (OVO) | For each binary learner, one class is positive, one class is negative, and the rest are ignored. This design exhausts all combinations of class pair assignments. | K(K – 1)/2 | 1 |
| binary complete | This design partitions the classes into all binary
combinations, and does not ignore any classes. That is, all class
assignments are | 2K – 1 – 1 | 2K – 2 |
| ternary complete | This design partitions the classes into all ternary
combinations. That is, all class assignments are
| (3K – 2K + 1 + 1)/2 | 3K – 2 |
| ordinal | For the first binary learner, the first class is negative and the rest are positive. For the second binary learner, the first two classes are negative and the rest are positive, and so on. | K – 1 | 1 |
| dense random | For each binary learner, the software randomly assigns classes into positive or negative classes, with at least one of each type. For more details, see Random Coding Design Matrices. | Random, but approximately 10 log2K | Variable |
| sparse random | For each binary learner, the software randomly assigns classes as positive or negative with probability 0.25 for each, and ignores classes with probability 0.5. For more details, see Random Coding Design Matrices. | Random, but approximately 15 log2K | Variable |
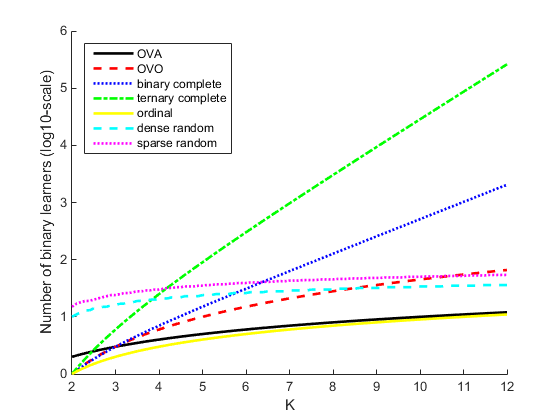
This plot compares the number of binary learners for the coding designs with an increasing number of classes (K).
Tips
The number of binary learners grows with the number of classes. For a problem with many classes, the
binarycompleteandternarycompletecoding designs are not efficient. However:If K ≤ 4, then use
ternarycompletecoding design rather thansparserandom.If K ≤ 5, then use
binarycompletecoding design rather thandenserandom.
You can display the coding design matrix of a trained ECOC classifier by entering
Mdl.CodingMatrixinto the Command Window.You should form a coding matrix using intimate knowledge of the application, and taking into account computational constraints. If you have sufficient computational power and time, then try several coding matrices and choose the one with the best performance (e.g., check the confusion matrices for each model using
confusionchart).Leave-one-out cross-validation (
Leaveout) is inefficient for data sets with many observations. Instead, use k-fold cross-validation (KFold).
After training a model, you can generate C/C++ code that predicts labels for new data. Generating C/C++ code requires MATLAB Coder™. For details, see Introduction to Code Generation for Statistics and Machine Learning Functions.