CompactClassificationECOC
Compact multiclass model for support vector machines (SVMs) and other classifiers
Description
CompactClassificationECOC is a compact version of the multiclass
error-correcting output codes (ECOC) model. The compact classifier does not include the data
used for training the multiclass ECOC model. Therefore, you cannot perform certain tasks, such
as cross-validation, using the compact classifier. Use a compact multiclass ECOC model for
tasks such as classifying new data (predict).
Creation
You can create a CompactClassificationECOC model in two ways:
Create a compact ECOC model from a trained
ClassificationECOCmodel by using thecompactobject function.Create a compact ECOC model by using the
fitcecocfunction and specifying the'Learners'name-value pair argument as'linear','kernel', atemplateLinearortemplateKernelobject, or a cell array of such objects.
Properties
Object Functions
compareHoldout | Compare accuracies of two classification models using new data |
discardSupportVectors | Discard support vectors of linear SVM binary learners in ECOC model |
edge | Classification edge for multiclass error-correcting output codes (ECOC) model |
gather | Gather properties of Statistics and Machine Learning Toolbox object from GPU |
incrementalLearner | Convert multiclass error-correcting output codes (ECOC) model to incremental learner |
lime | Local interpretable model-agnostic explanations (LIME) |
loss | Classification loss for multiclass error-correcting output codes (ECOC) model |
margin | Classification margins for multiclass error-correcting output codes (ECOC) model |
partialDependence | Compute partial dependence |
plotPartialDependence | Create partial dependence plot (PDP) and individual conditional expectation (ICE) plots |
predict | Classify observations using multiclass error-correcting output codes (ECOC) model |
shapley | Shapley values |
selectModels | Choose subset of multiclass ECOC models composed of binary
ClassificationLinear learners |
update | Update model parameters for code generation |
Examples
More About
The coding design is a matrix whose elements direct which classes are trained by each binary learner, that is, how the multiclass problem is reduced to a series of binary problems.
Each row of the coding design corresponds to a distinct class, and each column corresponds to a binary learner. In a ternary coding design, for a particular column (or binary learner):
A row containing 1 directs the binary learner to group all observations in the corresponding class into a positive class.
A row containing –1 directs the binary learner to group all observations in the corresponding class into a negative class.
A row containing 0 directs the binary learner to ignore all observations in the corresponding class.
Coding design matrices with large, minimal, pairwise row distances based on the Hamming measure are optimal. For details on the pairwise row distance, see Random Coding Design Matrices and [2].
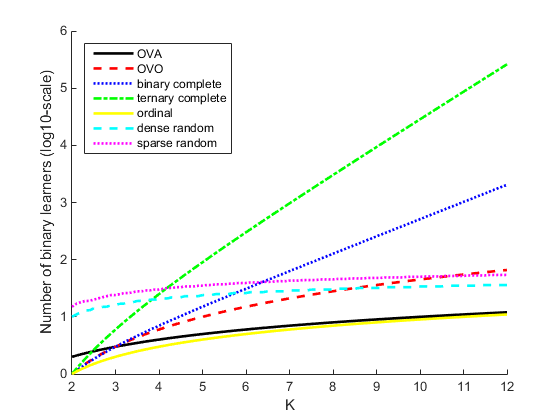
This table describes popular coding designs.
| Coding Design | Description | Number of Learners | Minimal Pairwise Row Distance |
|---|---|---|---|
| one-versus-all (OVA) | For each binary learner, one class is positive and the rest are negative. This design exhausts all combinations of positive class assignments. | K | 2 |
| one-versus-one (OVO) | For each binary learner, one class is positive, one class is negative, and the rest are ignored. This design exhausts all combinations of class pair assignments. | K(K – 1)/2 | 1 |
| binary complete | This design partitions the classes into all binary
combinations, and does not ignore any classes. That is, all class
assignments are | 2K – 1 – 1 | 2K – 2 |
| ternary complete | This design partitions the classes into all ternary
combinations. That is, all class assignments are
| (3K – 2K + 1 + 1)/2 | 3K – 2 |
| ordinal | For the first binary learner, the first class is negative and the rest are positive. For the second binary learner, the first two classes are negative and the rest are positive, and so on. | K – 1 | 1 |
| dense random | For each binary learner, the software randomly assigns classes into positive or negative classes, with at least one of each type. For more details, see Random Coding Design Matrices. | Random, but approximately 10 log2K | Variable |
| sparse random | For each binary learner, the software randomly assigns classes as positive or negative with probability 0.25 for each, and ignores classes with probability 0.5. For more details, see Random Coding Design Matrices. | Random, but approximately 15 log2K | Variable |
This plot compares the number of binary learners for the coding designs with an increasing number of classes (K).