使用 GoogLeNet 对图像进行分类
此示例说明如何使用预训练的深度卷积神经网络 GoogLeNet 对图像进行分类。
GoogLeNet 已经对超过一百万个图像进行了训练,可以将图像分为 1000 个对象类别(例如键盘、咖啡杯、铅笔和多种动物)。该网络已基于大量图像学习了丰富的特征表示。网络以图像作为输入,然后输出图像中对象的标签以及每个对象类别的概率。
加载预训练网络
使用 imagePretrainedNetwork 函数加载预训练的 GoogLeNet 网络和对应的类名称。此步骤需要 Deep Learning Toolbox™ Model for GoogLeNet Network 支持包。如果没有安装所需的支持包,软件会提供下载链接。
您还可以选择加载不同的预训练网络进行图像分类。要尝试不同的预训练网络,请在 MATLAB® 中打开此示例并选择其他网络。例如,您可以尝试 SqueezeNet,这是一个比 GoogLeNet 还要快的网络。您可以使用其他预训练网络运行此示例。有关所有可用网络的列表,请参阅预训练的深度神经网络。
[net,classNames] = imagePretrainedNetwork( "googlenet");
"googlenet");要分类的图像的大小必须与网络的输入大小相同。对于 GoogLeNet,网络的 Layers 属性的第一个元素是图像输入层。网络输入大小是图像输入层的 InputSize 属性。
inputSize = net.Layers(1).InputSize
inputSize = 1×3
224 224 3
随机查看 10 个类名称。
numClasses = numel(classNames); disp(classNames(randperm(numClasses,10)))
"speedboat"
"window screen"
"isopod"
"wooden spoon"
"lipstick"
"drake"
"hyena"
"dumbbell"
"strawberry"
"custard apple"
读取图像
读取并显示要分类的图像。
I = imread("peppers.png");
figure
imshow(I)
对图像进行调整大小和分类
显示图像的大小。图像为 384×512 像素,并且具有三个颜色通道 (RGB)。
size(I)
ans = 1×3
384 512 3
使用 imresize 将图像大小调整为网络的输入大小。调整大小会略微更改图像的纵横比。
X = imresize(I,inputSize(1:2)); figure imshow(X)

根据您的应用,您可能希望以不同方式调整图像大小。例如,您可以使用 I(1:inputSize(1),1:inputSize(2),:) 剪去图像的左上角。如果您有 Image Processing Toolbox™,则可以使用 imcrop 函数。
使用神经网络进行预测。要使用单个图像进行预测,请使用 predict 函数。该图像的数据类型为 uint8。要使用神经网络进行预测,请将图像转换为数据类型 single。要使用 GPU,请将数据转换为 gpuArray。使用 GPU 需要 Parallel Computing Toolbox™ 许可证和受支持的 GPU 设备。有关受支持设备的信息,请参阅GPU 计算要求 (Parallel Computing Toolbox)。否则,该函数使用 CPU。
X = single(X); if canUseGPU X = gpuArray(X); end scores = predict(net,X);
predict 函数返回每个类的概率。要将分类分数转换为分类标签,请使用 scores2label 函数。
[label,score] = scores2label(scores,classNames);
显示原始图像及预测的标签,以及具有该标签的图像的预测概率。
figure
imshow(I)
title(string(label) + ", " + string(score))
显示排名靠前的预测值
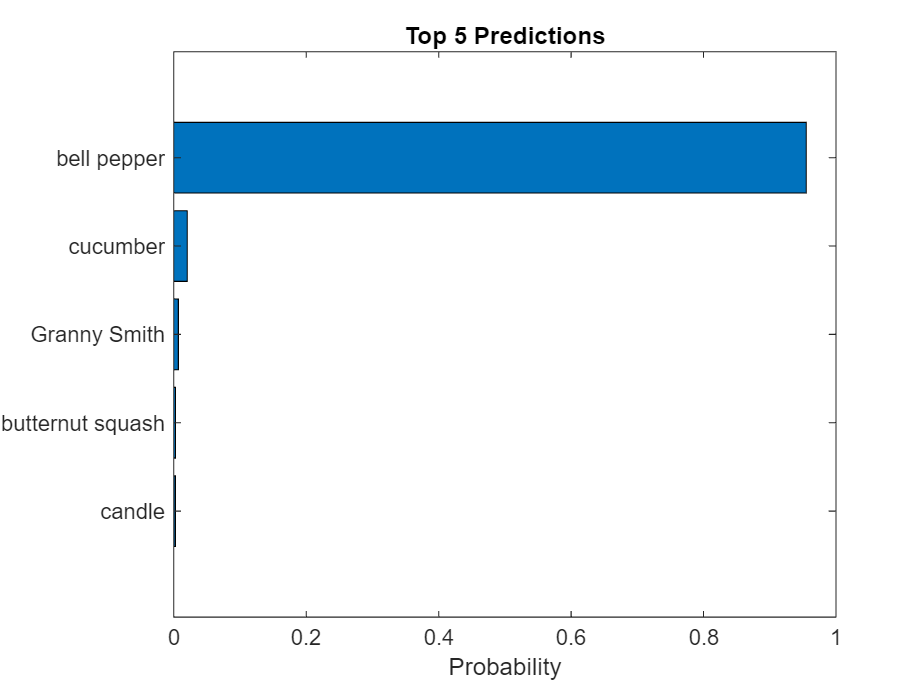
显示排名前五的预测标签,并以直方图形式显示它们的相关概率。由于网络将图像分类为如此多的对象类别,并且许多类别是相似的,因此在评估网络时通常会考虑准确度排名前五的几个类别。网络以高概率将图像分类为甜椒。
[~,idx] = sort(scores,"descend"); idx = idx(5:-1:1); classNamesTop = classNames(idx); scoresTop = scores(idx); figure barh(scoresTop) xlim([0 1]) title("Top 5 Predictions") xlabel("Probability") yticklabels(classNamesTop)
参考
[1] Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. "Going deeper with convolutions." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1-9. 2015.
[2] BVLC GoogLeNet Model. https://github.com/BVLC/caffe/tree/master/models/bvlc_googlenet
另请参阅
imagePretrainedNetwork | dlnetwork | trainingOptions | trainnet | testnet | minibatchpredict | scores2label | predict