detectspeechnn
Syntax
Description
roi = detectspeechnn(audioIn,fs,Name=Value)detectspeechnn(audioIn,fs,MergeThreshold=0.5) merges speech regions
that are separated by 0.5 seconds or less.
detectspeechnn(___) with no output arguments plots the
input signal and the detected speech regions.
This function requires both Audio Toolbox™ and Deep Learning Toolbox™.
Examples
Read in an audio signal containing speech and music and listen to the sound.
[audioIn,fs] = audioread("MusicAndSpeech-16-mono-14secs.ogg");
sound(audioIn,fs)Call detectspeechnn on the signal to obtain the regions of interest (ROIs), in samples, containing speech.
roi = detectspeechnn(audioIn,fs)
roi = 2×2
1 63120
83600 150000
Convert the ROIs from samples to seconds.
roiSeconds = (roi-1)/fs
roiSeconds = 2×2
0 3.9449
5.2249 9.3749
Plot the audio waveform with the speech regions.
detectspeechnn(audioIn,fs)

Read in an audio signal containing a speaker repeating the phrase "volume up".
[audioIn,fs] = audioread("MaleVolumeUp-16-mono-6secs.ogg");Compare detected speech regions by calling detectspeechnn with and without the application of an energy-based voice activity detector (VAD) in postprocessing.
tiledlayout(2,1) nexttile() detectspeechnn(audioIn,fs) nexttile() detectspeechnn(audioIn,fs,ApplyEnergyVAD=true)

Read in an audio signal.
[audioIn,fs] = audioread("MusicAndSpeech-16-mono-14secs.ogg");Call detectspeechnn with no output arguments to display a plot of the detected speech regions.
detectspeechnn(audioIn,fs);

Modify the parameters used in the postprocessing algorithm and see how they affect the detected speech regions. For more information about the VAD postprocessing algorithm, see Postprocessing.
mergeThreshold =1.3 ; % seconds lengthThreshold =
0.25; % seconds activationThreshold =
0.5; % probability deactivationThreshold =
0.25 ; % probability applyEnergyVAD =
false ; detectspeechnn(audioIn,fs,MergeThreshold=mergeThreshold, ... LengthThreshold=lengthThreshold, ... ActivationThreshold=activationThreshold, ... DeactivationThreshold=deactivationThreshold)

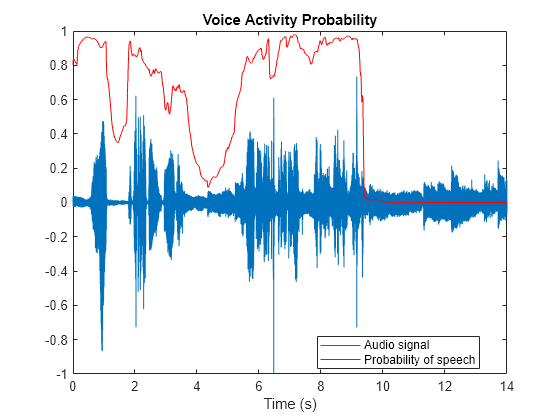
Read in an audio signal containing speech and music.
[audioIn,fs] = audioread("MusicAndSpeech-16-mono-14secs.ogg");Call detectspeechnn with an additional output variable to get the probabilities of speech in each sample of the signal.
[roi,probs] = detectspeechnn(audioIn,fs);
Plot the audio signal along with the voice activity probability.
t = (0:length(audioIn)-1)/fs; plot(t,audioIn,t,probs,"r") legend("Audio signal","Probability of speech",Location="best") xlabel("Time (s)") title("Voice Activity Probability")
Use detectspeechnn to detect the presence of speech in a streaming audio signal.
Create a dsp.AudioFileReader object to stream an audio file for processing. Set the SamplesPerFrame property to read 100 ms nonoverlapping chunks from the signal.
afr = dsp.AudioFileReader("MaleVolumeUp-16-mono-6secs.ogg"); analysisDuration = 0.1; % seconds afr.SamplesPerFrame = floor(analysisDuration*afr.SampleRate);
The neural network architecture of detectspechnn does not retain state between calls, and it performs best when analyzing larger chunks of audio signals. When you use detectspeechnn in a streaming scenario, specific application requirements of accuracy, computational efficiency, and latency dictate the analysis duration and whether to overlap analysis chunks.
Create a timescope object to plot the audio signal and the detected speech regions. Create an audioDeviceWriter to play the audio as you stream it.
scope = timescope(NumInputPorts=2, ... SampleRate=afr.SampleRate, ... TimeSpanSource="property",TimeSpan=5, ... YLimits=[-1.2,1.2], ... ShowLegend=true,ChannelNames=["Audio","Detected Speech"]); adw = audioDeviceWriter(afr.SampleRate);
In a streaming loop:
Read in a 100 ms chunk from the audio file.
Use
detectspeechnnto detect any regions of speech in the frame. Usesigroi2binmaskto convert the region indices to a binary mask.Plot the audio signal and the detected speech.
Play the audio with the device writer.
while ~isDone(afr) audioIn = afr(); segments = detectspeechnn(audioIn,afr.SampleRate,LengthThreshold=0.01); mask = sigroi2binmask(segments,afr.SamplesPerFrame); scope(audioIn,mask) adw(audioIn); end

Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
References
[1] Ravanelli, Mirco, et al. SpeechBrain: A General-Purpose Speech Toolkit. arXiv, 8 June 2021. arXiv.org, http://arxiv.org/abs/2106.04624