Voice Activity Detection in Noise Using Deep Learning
In this example, you perform batch and streaming voice activity detection (VAD) in a low SNR environment using a pretrained deep learning model. For details about the model and how it was trained, see Train Voice Activity Detection in Noise Model Using Deep Learning.
Load and Inspect Data
Read in an audio file that consists of words spoken with pauses between and listen to it. Use resample to resample the signal to the sample rate to 16 kHz. Use detectSpeech on the clean signal to determine the ground-truth speech regions.
fs = 16e3; [speech,fileFs] = audioread("Counting-16-44p1-mono-15secs.wav"); speech = resample(speech,fs,fileFs); speech = speech./max(abs(speech)); sound(speech,fs) detectSpeech(speech,fs,Window=hamming(0.04*fs,"periodic"),MergeDistance=round(0.5*fs))
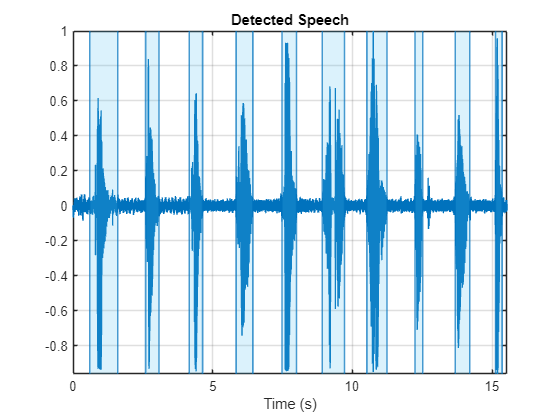
Load a noise signal and resample to the audio sample rate.
[noise,fileFs] = audioread("WashingMachine-16-8-mono-200secs.mp3");
noise = resample(noise,fs,fileFs);Use the supporting function mixSNR to corrupt the clean speech signal with washing machine noise at a desired SNR level in dB. Listen to the corrupted audio. The network was trained under -10 dB SNR conditions.
SNR =  -10;
noisySpeech = mixSNR(speech,noise,SNR);
sound(noisySpeech,fs)
-10;
noisySpeech = mixSNR(speech,noise,SNR);
sound(noisySpeech,fs)The algorithm-based VAD, detectSpeech, fails under these noisy conditions.
detectSpeech(noisySpeech,fs,Window=hamming(0.04*fs,"periodic"),MergeDistance=round(0.5*fs))
Download Pretrained Network
Download and load a pretrained network and a configured audioFeatureExtractor object. The network was trained to detect speech in low SNR environments given features output from the audioFeatureExtractor object.
downloadFolder = matlab.internal.examples.downloadSupportFile("audio/examples","vadbilsmtnet.zip"); dataFolder = tempdir; netFolder = fullfile(dataFolder,"vadbilsmtnet"); unzip(downloadFolder,netFolder) pretrainedNetwork = load(fullfile(netFolder,"voiceActivityDetectionExample.mat")); afe = pretrainedNetwork.afe; net = pretrainedNetwork.speechDetectNet;
The audioFeatureExtractor object is configured to extract features from 256-sample windows with 128 samples overlap between windows. At a 16 kHz sample rate, features are extracted from 16 ms windows with 8 ms overlap. From each window, the audioFeatureExtractor object extracts nine features: spectral centroid, spectral crest, spectral entropy, spectral flux, spectral kurtosis, spectral rolloff point, spectral skewness, spectral slope, and harmonic ratio.
afe
afe =
audioFeatureExtractor with properties:
Properties
Window: [256×1 double]
OverlapLength: 128
SampleRate: 16000
FFTLength: []
SpectralDescriptorInput: 'linearSpectrum'
FeatureVectorLength: 9
Enabled Features
spectralCentroid, spectralCrest, spectralEntropy, spectralFlux, spectralKurtosis, spectralRolloffPoint
spectralSkewness, spectralSlope, harmonicRatio
Disabled Features
linearSpectrum, melSpectrum, barkSpectrum, erbSpectrum, mfcc, mfccDelta
mfccDeltaDelta, gtcc, gtccDelta, gtccDeltaDelta, spectralDecrease, spectralFlatness
spectralSpread, pitch, zerocrossrate, shortTimeEnergy
To extract a feature, set the corresponding property to true.
For example, obj.mfcc = true, adds mfcc to the list of enabled features.
The network consists of two bidirectional LSTM layers, each with 200 hidden units, and a classification output that returns either class 0 corresponding to no voice activity detected or class 1 corresponding to voice activity detected.
net.Layers
ans =
5×1 Layer array with layers:
1 'sequenceinput' Sequence Input Sequence input with 9 channels
2 'biLSTM_1' BiLSTM BiLSTM with 200 hidden units
3 'biLSTM_2' BiLSTM BiLSTM with 200 hidden units
4 'fc' Fully Connected Fully connected layer with output size 2
5 'softmax' Softmax Softmax
Perform Voice Activity Detection
Extract features from the speech data and then standardize them. Orient the features so that time is across columns.
features = extract(afe,noisySpeech); features = (features - mean(features,1))./std(features,[],1); features = features';
Pass the features through the speech detection network to classify each feature vector as belonging to a frame of speech or not.
scores = predict(net,features.'); decisionsCategorical = scores2label(scores,categorical([0 1]));
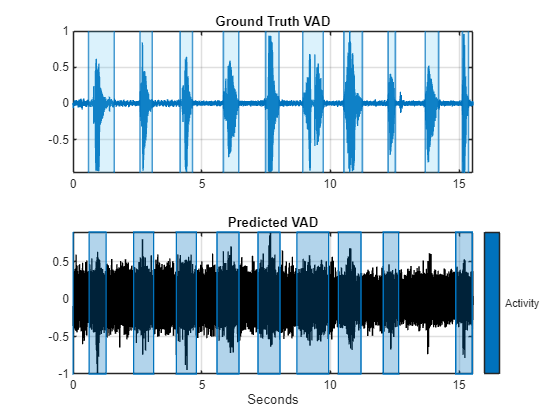
Each decision corresponds to an analysis window analyzed by the audioFeatureExtractor. Replicate the decisions so that they are in one-to-one correspondence with the audio samples. Use detectSpeech with no output arguments to plot the ground truth. Use signalMask and plotsigroi to plot the predicted VAD.
decisions = (double(decisionsCategorical) - 1); decisionsPerSample = [decisions(1:round(numel(afe.Window)/2));repelem(decisions,numel(afe.Window)-afe.OverlapLength,1)]; tiledlayout(2,1) nexttile detectSpeech(speech,fs,Window=hamming(0.04*fs,"periodic"),MergeDistance=round(0.5*fs)) title("Ground Truth VAD") xlabel("") nexttile mask = signalMask(decisionsPerSample,SampleRate=fs,Categories="Activity"); plotsigroi(mask,noisySpeech,true) title("Predicted VAD")
Perform Streaming Voice Activity Detection
The audioFeatureExtractor object is intended for batch processing and does not retain state between calls. Use generateMATLABFunction to create a streaming-friendly feature extractor. You can use the trained VAD network in a streaming context using classifyAndUpdateState (Deep Learning Toolbox).
generateMATLABFunction(afe,"featureExtractor",IsStreaming=true)To simulate a streaming environment, save the speech and noise signals as WAV files. To simulate streaming input, you will use dsp.AudioFileReader to read frames from the files and mix them at a desired SNR. You can also use audioDeviceReader so that your microphone is the speech source.
audiowrite("Speech.wav",speech,fs) audiowrite("Noise.wav",noise,fs)
Define parameters for the streaming voice activity detection in noise demonstration:
signal- Signal source, specified as either the speech file previously recorded, or your microphone.noise- Noise source, specified as a noise sound file to mix with the signal.SNR- Signal-to-noise ratio to mix the signal and noise, specified in dB.testDuration- Test duration, specified in seconds.playbackSource- Playback source, specified as either the original clean signal, the noisy signal, or the detected speech. AnaudioDeviceWriterobject is used to play the audio to your speakers.
signal ="Speech.wav"; noise = "Noise.wav"; SNR =
-10; % dB testDuration =
20; % seconds playbackSource =
"noisy";
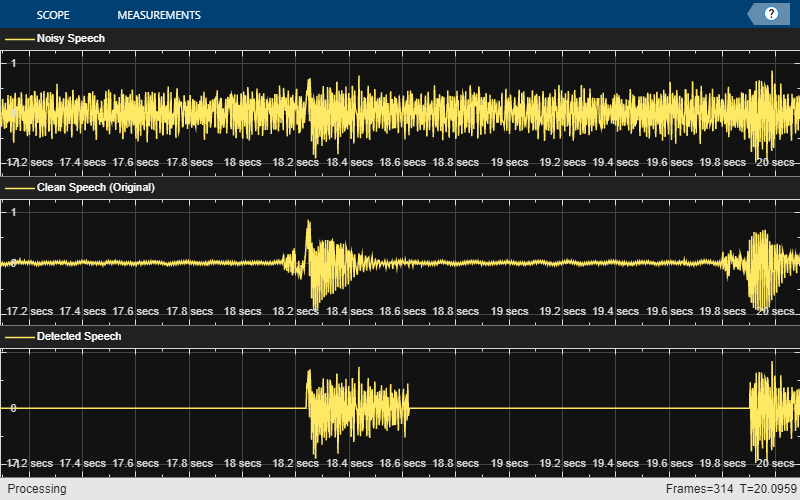
Call the supporting function streamingDemo to observe the performance of the VAD network on streaming audio. The parameters you set using the live controls do not interrupt the streaming example. After the streaming demo is complete, you can modify parameters of the demonstration, then run the streaming demo again.
streamingDemo(net,afe, ... signal,noise,SNR, ... testDuration,playbackSource);
References
[1] Warden P. "Speech Commands: A public dataset for single-word speech recognition", 2017. Available from https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz. Copyright Google 2017. The Speech Commands Dataset is licensed under the Creative Commons Attribution 4.0 license
Supporting Functions
Streaming Demo
function streamingDemo(net,afe,signal,noise,SNR,testDuration,playbackSource) % streamingDemo(net,afe,signal,noise,SNR,testDuration,playbackSource) runs % a real-time VAD demo. % Create dsp.AudioFileReader objects to read speech and noise files frame % by frame. If the speech signal is specified as Microphone, use an % audioDeviceReader as the source. if strcmpi(signal,"Microphone") speechReader = audioDeviceReader(afe.SampleRate); else speechReader = dsp.AudioFileReader(signal,PlayCount=inf); end noiseReader = dsp.AudioFileReader(noise,PlayCount=inf,SamplesPerFrame=speechReader.SamplesPerFrame); fs = speechReader.SampleRate; % Create a dsp.MovingStandardDeviation object and a dsp.MovingAverage % object. You will use these to determine the standard deviation and mean % of the audio features for standardization. The statistics should improve % over time. movSTD = dsp.MovingStandardDeviation(Method="Exponential weighting",ForgettingFactor=1); movMean = dsp.MovingAverage(Method="Exponential weighting",ForgettingFactor=1); % Create a dsp.MovingMaximum object. You will use it to standardize the % audio. movMax = dsp.MovingMaximum(SpecifyWindowLength=false); % Create a dsp.MovingRMS object. You will use this to determine the signal % and noise mix at the desired SNR. This object is only useful for example % purposes where you are artificially adding noise. movRMS = dsp.MovingRMS(Method="Exponential weighting",ForgettingFactor=1); % Create three dsp.AsyncBuffer objects. One to buffer the input audio, one % to buffer the extracted features, and one to buffer the output audio so % that VAD decisions correspond to the audio signal. The output buffer is % only necessary for visualizing the decisions in real time. audioInBuffer = dsp.AsyncBuffer(2*speechReader.SamplesPerFrame); featureBuffer = dsp.AsyncBuffer(ceil(2*speechReader.SamplesPerFrame/(numel(afe.Window)-afe.OverlapLength))); audioOutBuffer = dsp.AsyncBuffer(2*speechReader.SamplesPerFrame); % Create a time scope to visualize the original speech signal, the noisy % signal that the network is applied to, and the decision output from the % network. scope = timescope(SampleRate=fs, ... TimeSpanSource="property", ... TimeSpan=3, ... BufferLength=fs*3*3, ... TimeSpanOverrunAction="Scroll", ... AxesScaling="updates", ... MaximizeAxes="on", ... AxesScalingNumUpdates=20, ... NumInputPorts=3, ... LayoutDimensions=[3,1], ... ChannelNames=["Noisy Speech","Clean Speech (Original)","Detected Speech"], ... ... ActiveDisplay = 1, ... ShowGrid=true, ... ... ActiveDisplay = 2, ... ShowGrid=true, ... ... ActiveDisplay=3, ... ShowGrid=true); % Create an audioDeviceWriter object to play either the original or noisy % audio from your speakers. deviceWriter = audioDeviceWriter(SampleRate=fs); % Initialize variables used in the loop. windowLength = numel(afe.Window); hopLength = windowLength - afe.OverlapLength; % Run the streaming demonstration. loopTimer = tic; while toc(loopTimer) < testDuration % Read a frame of the speech signal and a frame of the noise signal speechIn = speechReader(); noiseIn = noiseReader(); % Mix the speech and noise at the specified SNR energy = movRMS([speechIn,noiseIn]); noiseGain = 10^(-SNR/20) * energy(end,1) / energy(end,2); noisyAudio = speechIn + noiseGain*noiseIn; % Update a running max to scale the audio myMax = movMax(abs(noisyAudio)); noisyAudio = noisyAudio/myMax(end); % Write the noisy audio and speech to buffers write(audioInBuffer,[noisyAudio,speechIn]); % If enough samples are in the audio buffer to calculate a feature % vector, read the samples, normalize them, extract the feature % vectors, and write the latest feature vector to the features buffer. while (audioInBuffer.NumUnreadSamples >= hopLength) x = read(audioInBuffer,numel(afe.Window),afe.OverlapLength); write(audioOutBuffer,x(end-hopLength+1:end,:)); noisyAudio = x(:,1); features = featureExtractor(noisyAudio); write(featureBuffer,features'); end if featureBuffer.NumUnreadSamples >= 1 % Read the audio data corresponding to the number of unread % feature vectors. audioHop = read(audioOutBuffer,featureBuffer.NumUnreadSamples*hopLength); % Read all unread feature vectors. features = read(featureBuffer); % Use only the new features to update the standard deviation and % mean. Normalize the features. rmean = movMean(features); rstd = movSTD(features); features = (features - rmean(end,:)) ./ rstd(end,:); % Network inference [score,state] = predict(net,features); net.State = state; [~,decision] = max(score,[],2); decision = decision-1; % Convert the decisions per feature vector to decisions per sample decision = repelem(decision,hopLength,1); % Apply a mask to the noisy speech for visualization vadResult = audioHop(:,1); vadResult(decision==0) = 0; % Listen to the speech or speech+noise switch playbackSource case "clean" deviceWriter(audioHop(:,2)); case "noisy" deviceWriter(audioHop(:,1)); case "detectedSpeech" deviceWriter(vadResult); end % Visualize the speech+noise, the original speech, and the voice % activity detection. scope(audioHop(:,1),audioHop(:,2),vadResult) end end end
Mix SNR
function [noisySignal,requestedNoise] = mixSNR(signal,noise,ratio) % [noisySignal,requestedNoise] = mixSNR(signal,noise,ratio) returns a noisy % version of the signal, noisySignal. The noisy signal has been mixed with % noise at the specified ratio in dB. numSamples = size(signal,1); % Convert noise to mono noise = mean(noise,2); % Trim or expand noise to match signal size if size(noise,1)>=numSamples % Choose a random starting index such that you still have numSamples % after indexing the noise. start = randi(size(noise,1) - numSamples + 1); noise = noise(start:start+numSamples-1); else numReps = ceil(numSamples/size(noise,1)); temp = repmat(noise,numReps,1); start = randi(size(temp,1) - numSamples - 1); noise = temp(start:start+numSamples-1); end signalNorm = norm(signal); noiseNorm = norm(noise); goalNoiseNorm = signalNorm/(10^(ratio/20)); factor = goalNoiseNorm/noiseNorm; requestedNoise = noise.*factor; noisySignal = signal + requestedNoise; noisySignal = noisySignal./max(abs(noisySignal)); end