Optimize SIMD Code by Performing Fused Multiply Add Operations
This example shows how to generate optimized single instruction, multiple data (SIMD) code that performs fused multiply-add operations. A fused multiply-add operation is performed in one step with a single rounding rather than performing a multiplication operation followed by an addition, with multiple roundings.
For processors that support fused multiply-add (FMA) instructions, when you set the Leverage target hardware instruction set to FMA or select the FMA parameter, the code generator generates code that includes FMA intrinsics to perform fused multiply-add operations. Using this optimization improves the execution speed of the generated SIMD code. Because of the single rounding behavior of fused multiply-add operations, this optimization might introduce a mismatch between simulation and code generation results.
Example Model
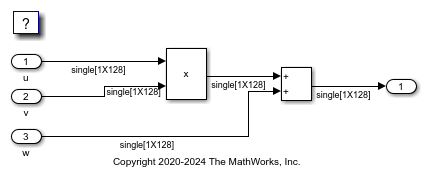
Open the example model rtwdemo_simd_with_fma. The model contains a multiplication operation followed by an addition.
model = 'rtwdemo_simd_with_fma';
open_system(model)
Generate SIMD Code Without FMA Optimization
1. On the Optimization pane, set the Leverage target hardware instruction set extensions to SSE2. Alternatively, you can use the command-line API:
set_param(model, 'InstructionSetExtensions', 'SSE2');
2. Build the model.
slbuild(model);
### Starting build procedure for: rtwdemo_simd_with_fma ### Successful completion of build procedure for: rtwdemo_simd_with_fma Build Summary Top model targets: Model Build Reason Status Build Duration ======================================================================================================================== rtwdemo_simd_with_fma Information cache folder or artifacts were missing. Code generated and compiled. 0h 0m 57.194s 1 of 1 models built (0 models already up to date) Build duration: 0h 1m 5.4224s
3. Inspect the generated rtwdemo_simd_with_fma_step step function in the rtwdemo_simd_with_fma.c.
file = fullfile('rtwdemo_simd_with_fma_ert_rtw','rtwdemo_simd_with_fma.c'); coder.example.extractLines(file,'/* Model step function */','/* Model initialize function',1,1);
/* Model step function */
void rtwdemo_simd_with_fma_step(void)
{
int32_T i;
/* Outport: '<Root>/Out1' incorporates:
* Inport: '<Root>/u'
* Inport: '<Root>/v'
* Inport: '<Root>/w'
* Product: '<Root>/Product'
* Sum: '<Root>/Add'
*/
for (i = 0; i <= 124; i += 4) {
_mm_storeu_ps(&rtwdemo_simd_with_fma_Y.Out1[i], _mm_add_ps(_mm_mul_ps
(_mm_loadu_ps(&rtwdemo_simd_with_fma_U.single1X128[i]), _mm_loadu_ps
(&rtwdemo_simd_with_fma_U.single1X128_f[i])), _mm_loadu_ps
(&rtwdemo_simd_with_fma_U.single1X128_k[i])));
}
/* End of Outport: '<Root>/Out1' */
}
The generated code contains a vectorized loop that performs the multiplication and addition operations sequentially, with two roundings.
Generate SIMD Code with FMA Optimization
1. To enable FMA optimization, on the Optimization pane, set the Leverage target hardware instruction set extensions to FMA. If your target hardware does not include the FMA instruction set, select an instruction set and then select the parameter FMA. Alternatively, you can use the command-line API:
set_param(model, 'InstructionSetExtensions', 'FMA');
2. Build the model again.
[status, message, messageid] = rmdir('slprj\ert\_sharedutils', 's'); slbuild(model);
### Starting build procedure for: rtwdemo_simd_with_fma ### Successful completion of build procedure for: rtwdemo_simd_with_fma Build Summary Top model targets: Model Build Reason Status Build Duration ==================================================================================================== rtwdemo_simd_with_fma Generated code was out of date. Code generated and compiled. 0h 0m 12.325s 1 of 1 models built (0 models already up to date) Build duration: 0h 0m 13.738s
3. Inspect the generated rtwdemo_simd_with_fma_step step function in the rtwdemo_simd_with_fma.c.
file = fullfile('rtwdemo_simd_with_fma_ert_rtw','rtwdemo_simd_with_fma.c'); coder.example.extractLines(file,'/* Model step function */','/* Model initialize function',1,1);
/* Model step function */
void rtwdemo_simd_with_fma_step(void)
{
int32_T i;
/* Outport: '<Root>/Out1' incorporates:
* Inport: '<Root>/u'
* Inport: '<Root>/v'
* Inport: '<Root>/w'
* Product: '<Root>/Product'
* Sum: '<Root>/Add'
*/
for (i = 0; i <= 120; i += 8) {
_mm256_storeu_ps(&rtwdemo_simd_with_fma_Y.Out1[i], _mm256_fmadd_ps
(_mm256_loadu_ps(&rtwdemo_simd_with_fma_U.single1X128[i]),
_mm256_loadu_ps(&rtwdemo_simd_with_fma_U.single1X128_f[i]),
_mm256_loadu_ps(&rtwdemo_simd_with_fma_U.single1X128_k[i])));
}
/* End of Outport: '<Root>/Out1' */
}
The vectorized loop contains the intrinsic function mm256_fmadd_ps that performs multiplication-addition in one step, with a single rounding. This optimization improves the execution speed of the generated code. It is possible that the execution of the generated code does not produce the same result as the simulation.
The presence of FMA optimization is reported in the code generation report as follows.

It is reported that the code generator used FMA instruction set extensions and the FMA optimization is triggered for the rtwdemo_simd_with_fma model code. If you are working with a model hierarchy and FMA optimization is triggered only for referenced models, the code generator does not report the presence of FMA optimization in the code generation report created for the top model.
Clean Up Example Folders and Files
Close the model and remove temporary folders and files.
bdclose(model);
See Also
Leverage target hardware instruction set extensions