为非虚拟子系统生成模块化函数代码
关于非虚拟子系统代码生成
默认情况下,在为非虚拟子系统生成代码时,代码生成器将与非虚拟子系统相关联的内部数据放在与父模型的内部数据相同的数据结构体中。这使得跟踪和测试代码变得困难,特别是对于不可重用的子系统。此外,在包含非虚拟子系统的大型模型中,数据结构体会变得很大,可能难以编译。
要为非虚拟子系统(包括原子子系统和条件执行子系统)生成模块化函数代码,请使用子系统模块参数具有独立数据的函数。此模块参数指示代码生成器为独立于父模型数据结构体的非虚拟子系统函数生成模块 I/O 和 DWork 数据结构体。这样为子系统生成的代码具有以下好处:
更容易跟踪。
更容易测试。
可减小模型的全局数据结构体的大小。
要使用具有独立数据的函数参数,需要执行以下操作:
使用基于 ERT 的系统目标文件配置模型。
将子系统配置为原子或条件执行子系统。
将子系统模块参数函数打包设置为不可重用函数。
要配置子系统以生成模块化函数代码,请调用“子系统参数”对话框,并进行一系列选择以显示和启用具有独立数据的函数选项。有关详细信息,请参阅配置子系统以生成模块化函数代码和 非虚拟子系统的模块化函数代码。有关适用的限制,请参阅 非虚拟子系统模块化函数代码限制。
有关为原子子系统生成代码的详细信息,请参阅将子系统代码生成为单独的函数和文件。
配置子系统以生成模块化函数代码
验证包含子系统的模型使用基于 ERT 的系统目标文件。
选择要为其生成模块化函数代码的子系统,并打开“子系统参数”对话框。原子子系统的对话框如下所示。(在条件执行子系统的对话框中,对话框选项视为原子单元灰显,您可以跳过步骤 3。)

如果模块参数视为原子单元可供选择但未选择,则该子系统既不是原子子系统,也不是条件执行子系统。选择参数视为原子单元,这将启用代码生成选项卡上的函数打包参数。选择代码生成选项卡。
对于函数打包参数,选择不可重用函数。进行此选择后,将显示具有独立数据的函数参数。
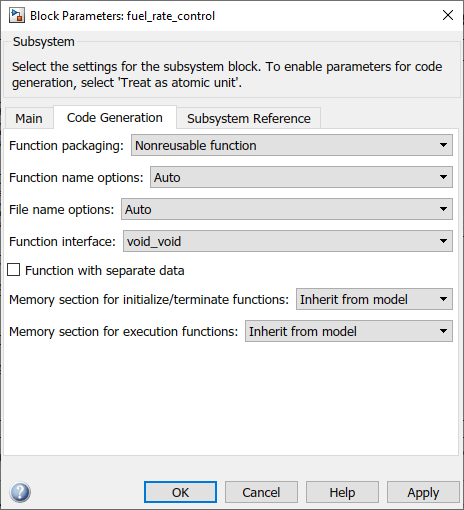
在为选中具有独立数据的函数参数的非虚拟子系统生成代码之前,请考虑在清除该参数的情况下生成函数代码,并将生成的函数
.c和.h文件保存在单独的目录中,以供以后比较。选择具有独立数据的函数参数。将显示其他参数。

要控制生成的子系统函数和子系统文件的命名,请修改子系统参数函数名称选项和文件名选项。
保存您的子系统参数更改,并通过点击确定退出对话框。
为子系统生成代码并检查生成的文件,包括根据您的子系统参数设定命名的函数
.c和.h文件。
有关为非虚拟子系统生成代码的详细信息,请参阅将子系统代码生成为单独的函数和文件。有关生成的子系统函数代码的示例,请参阅非虚拟子系统的模块化函数代码。
非虚拟子系统的模块化函数代码
此示例说明如何在分别清除和选中具有独立数据的函数参数的情况下生成非虚拟子系统函数代码,并比较结果。
打开示例模型
SubsystemAtomic。openExample("SubsystemAtomic")打开 Embedded Coder。将系统目标文件更改为 ert.tlc。
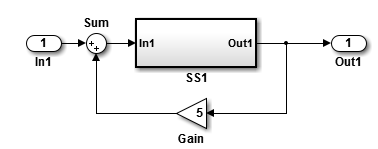
此模型说明如何保持虚拟子系统的边界。当您选中子系统模块参数视为原子单元时,代码生成器为子系统生成的代码作为原子单元执行。当配置为原子时,您可以通过在代码生成选项卡上设置函数打包参数来指定代码生成器如何表示子系统。您可以指定将子系统转换为以下实现类型之一:
内联:调用位置上的内联子系统代码。
函数:在模型全局数据结构体中具有 I/O 和内部数据的
void/void函数。可重用函数:数据作为函数参量传入的可重入函数。
自动:代码生成器基于上下文优化实现。
双击
SS1子系统并检查内容。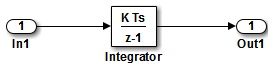
然后,关闭子系统窗口。
右键点击
SS1子系统,然后点击“模块参数”按钮 。检查设置。当您将子系统设置为原子子系统并启用子系统参数尽量减少出现人为代数环时,Simulink® 和代码生成器可以避免人为代数环。
。检查设置。当您将子系统设置为原子子系统并启用子系统参数尽量减少出现人为代数环时,Simulink® 和代码生成器可以避免人为代数环。创建一个
SubsystemAtomic的变体,用于展示没有数据分离的函数代码。在“子系统参数”对话框中,执行以下操作:
在主选项卡中,选择视为原子单元。
在代码生成选项卡中,执行以下操作:
将函数打包设置为不可重用函数。
将函数名称选项设置为用户指定。
将函数名称设置为
myfun。将函数名称选项设置为使用函数名称。此设置是可选的,但它通过将原子子系统函数代码生成到文件
myfun.c和myfun.h中,简化了后面的代码比较任务。
请不要选择具有独立数据的函数参数。
点击应用以应用更改,然后点击确定退出对话框。
将具有唯一文件名的模型变体(例如,
SubsystemAtomic1)保存到可写位置。
创建一个
SubsystemAtomic的变体,用于展示具有数据分隔的函数代码。打开模型
SubsystemAtomic。打开 Embedded Coder。将系统目标文件更改为 ert.tlc。
在模型画布中,右键点击 SS1 子系统,然后选择模块参数(子系统)。在“子系统参数”对话框中,执行以下操作:
在主选项卡中,选择视为原子单元。
在代码生成选项卡中,执行以下操作:
将函数打包设置为不可重用函数。
将函数名称选项设置为用户指定。
将函数名称设置为
myfun。将函数名称选项设置为使用函数名称。
选择具有独立数据的函数。
点击应用以应用更改,然后点击确定退出对话框。
将具有唯一文件名的模型变体(例如,
SubsystemAtomic2)保存到可写位置。
为每个模型(例如,
SubsystemAtomic1和SubsystemAtomic2)生成代码。比较为这两个模型生成的
model.c.h和myfun.c/.h文件。有关代码比较的讨论,请参阅非虚拟子系统函数数据分离产生的 H 文件差异和非虚拟子系统函数数据分离的 C 文件差异。在此示例中,
ert_main.c、model_private.hmodel_types.hrtwtypes.h的生成变体没有显著差异。
非虚拟子系统函数数据分离产生的 H 文件差异
选择具有独立数据的函数会导致代码生成器将子系统数据的类型定义放在
myfun.h的SubsystemAtomic2文件中:/* Block states (default storage) for system '<Root>/SS1' */ typedef struct { real_T Integrator_DSTATE; /* '<S1>/Integrator' */ } DW_myfun_T;对于
SubsystemAtomic1,子系统数据的类型定义属于该模型并出现在SubsystemAtomic1.h中:/* Block signals (default storage) */ typedef struct { real_T Sum; /* '<Root>/Sum' */ } B_SubsystemAtomic_1_T; /* Block states (default storage) for system '<Root>' */ typedef struct { real_T Integrator_DSTATE; /* '<S1>/Integrator' */ } DW_SubsystemAtomic_1_T;选择具有独立数据的函数会在
myfun.h的SubsystemAtomic2文件中生成以下外部声明:/* Extern declarations of internal data for system '<Root>/SS1' */ extern DW_myfun_T myfun_DW; extern void myfun_Update(void); extern void myfun(void);
相反,
SubsystemAtomic1的生成代码包含子系统BlockIO和D_Work数据的模型级外部声明,位于SubsystemAtomic1.h中:/* Block signals (default storage) */ extern B_SubsystemAtomic_1_T SubsystemAtomic_1_B; /* Block states (default storage) */ extern DW_SubsystemAtomic_1_T SubsystemAtomic_1_DW;
非虚拟子系统函数数据分离的 C 文件差异
选择具有独立数据的函数会在
myfun_initialize的myfun.c文件中生成单独的子系统初始化函数SubsystemAtomic2:void myfun_initialize(void) { { ((real_T*)&SubsystemAtomic2_myfunB.Integrator)[0] = 0.0; } SubsystemAtomic2_myfunDW.Integrator_DSTATE = 0.0; }myfun.c中的子系统初始化函数由SubsystemAtomic2.c中的模型初始化函数调用:/* Model initialize function */ void SubsystemAtomic2_initialize(void) { ... /* Initialize subsystem data */ myfun_initialize(); }而对于
SubsystemAtomic1,子系统数据由SubsystemAtomic1.c中的模型初始化函数初始化:/* Model initialize function */ void SubsystemAtomic1_initialize(void) { ... /* block I/O */ { ... ((real_T*)&SubsystemAtomic1_B.Integrator)[0] = 0.0; } /* states (dwork) */ SubsystemAtomic1_DWork.Integrator_DSTATE = 0.0; ... }选择具有独立数据的函数会在
myfun.c的SubsystemAtomic2文件中生成以下声明:/* Declare variables for internal data of system '<Root>/SS1' */ DW_myfun_T myfun_DW;
而
SubsystemAtomic1的生成代码包含子系统BlockIO和D_Work数据的模型级声明,位于SubsystemAtomic1.c中:/* Block signals (default storage) */ B_SubsystemAtomic_1_T SubsystemAtomic_1_B; /* Block states (default storage) */ DW_SubsystemAtomic_1_T SubsystemAtomic_1_DW;
选择具有独立数据的函数所生成的标识符名称会反映数据项的子系统方向。子系统函数(如
myfun和myfun_update)中对子系统数据的引用在模型model_stepmyfun的SubsystemAtomic2中的代码/* DiscreteIntegrator: '<S1>/Integrator' */ SubsystemAtomic_2_Y.Out1 = myfun_DW.Integrator_DSTATE;
与来自
myfun的SubsystemAtomic1中的对应代码进行比较。/* DiscreteIntegrator: '<S1>/Integrator' */ SubsystemAtomic_1_Y.Out1 = SubsystemAtomic_1_DW.Integrator_DSTATE;
非虚拟子系统模块化函数代码限制
非虚拟子系统模块参数具有独立数据的函数有以下限制:
该参数可用于使用基于 ERT 的系统目标文件配置的模型。
应用该参数的非虚拟子系统不能有多个采样时间或连续采样时间;也就是说,子系统必须为具有离散采样时间的单速率子系统。
非虚拟子系统不能包含连续状态。
非虚拟子系统不能输出函数调用信号。
非虚拟子系统不能包含非内联 S-Function。
非虚拟子系统的生成文件将引用模型范围内的头文件,如
model.hmodel_private.h该参数与模型配置参数代码接口打包的可重用函数设置不兼容。同时选择这两个参数会出错。
为子系统选择该参数时,包含该子系统的模型不能包含选中了跨模型实例共享的 Data Store Memory 模块。请参阅 Data Store Memory。