Time Series Regression IX: Lag Order Selection
This example shows how to select statistically significant predictor histories for multiple linear regression models. It is the ninth in a series of examples on time series regression, following the presentation in previous examples.
Introduction
Predictors in dynamic regression models may include lagged values of exogenous explanatory variables (distributed lag, or DL, terms), lagged values of endogenous response variables (autoregressive, or AR, terms), or both. Lagged values of an innovations process (moving average, or MA, terms) may have economic significance, representing the persistence of shocks, but they are most often included to offset the need for additional DL or AR terms. (See the example Time Series Regression VIII: Lagged Variables and Estimator Bias.)
Ideally, economic theory suggests which lags to include in a model. Often, however, the delay between predictor changes and corresponding response changes must be discovered through data analysis. A common modeling approach is to include the history of a predictor at times t - 1, t - 2, t - 3, ..., t - p, with the assumption that significant effects on the current response are only produced by recent changes in the predictor. Specification analysis then considers extending or restricting the lag structure, and finally selecting an appropriate lag order p.
This example investigates strategies for lag order selection. Although details depend on the data and the modeling context, a common goal is to identify a concise, easy-to-interpret description of the data-generating process (DGP) that leads to accurate estimation and reliable forecasting.
We begin by loading relevant data from previous examples in this series:
load Data_TSReg8Basic Tests
The classical, normal linear model (CNLM), introduced in the example Time Series Regression I: Linear Models, filters data to generate white noise residuals. Econometric models do not always aspire to such a thorough statistical description of the DGP, especially when predictors are dictated by theory or policy, and modeling goals are focused on specific effects. Nevertheless, departures from the CNLM, and their degree, are common measures of model misspecification.
At any point in the model specification process, residuals may display nonnormality, autocorrelation, heteroscedasticity, and other violations of CNLM assumptions. As predictors are added or removed, models can be evaluated by the relative improvement in the quality of the residuals. Tests for model fit via residual analysis are described in the example Time Series Regression VI: Residual Diagnostics.
Model specification must also consider the statistical significance of predictors, to avoid over-fitting in the service of residual whitening, and to produce a parsimonious representation of the DGP. Basic tests include the t-test, which evaluates the significance of individual predictors, and the F-test, which is used to evaluate the joint significance of, say, an entire lag structure. These tests are usually used together, since a predictor with an insignificant individual effect may still contribute to a significant joint effect.
Many lag order selection procedures use these basic tests to evaluate extensions and restrictions of an initial lag specification. Good econometric practice suggests careful evaluation of each step in the process. Econometricians must judge statistical decisions in the context of economic theory and model assumptions. Automated procedures are discussed in the example on Time Series Regression V: Predictor Selection, but it is often difficult to completely automate the identification of a useful lag structure. We take a more "manual" approach in this example. Of course, the reliability of any such procedure depends critically on the reliability of the underlying tests.
Consider the basic model of credit defaults introduced in the example Time Series Regression I: Linear Models:
M0
M0 =
Linear regression model:
IGD ~ 1 + AGE + BBB + CPF + SPR
Estimated Coefficients:
Estimate SE tStat pValue
_________ _________ _______ _________
(Intercept) -0.22741 0.098565 -2.3072 0.034747
AGE 0.016781 0.0091845 1.8271 0.086402
BBB 0.0042728 0.0026757 1.5969 0.12985
CPF -0.014888 0.0038077 -3.91 0.0012473
SPR 0.045488 0.033996 1.338 0.1996
Number of observations: 21, Error degrees of freedom: 16
Root Mean Squared Error: 0.0763
R-squared: 0.621, Adjusted R-Squared: 0.526
F-statistic vs. constant model: 6.56, p-value = 0.00253
Based on the p-values of the t-statistics, AGE is the most significant individual risk factor (positive coefficient) for the default rates measured by the response IGD. AGE represents the percentage of investment-grade bond issuers first rated 3 years ago. Defaults often occur after this period, when capital from an initial issue is expended, but they may occur sooner or later. It seems reasonable to consider models that include lags or leads of AGE.
The fit of M0 is based on only 21 observations, and the 5 coefficients already estimated leave only 16 degrees of freedom for further fitting. Extended lag structures, and the corresponding reduction in sample size, would bring into question the validity of diagnostic statistics.
For reference, we create tables and fit models with AGE lag orders of 1, 2, 3, 4, and 5:
% Lagged data: AGE = DataTable.AGE; maxLag = 5; lags = 1:maxLag; AGELags = lagmatrix(AGE,lags); lagNames = strcat({'AGELag'},num2str(lags','%-d')); AGELags = array2table(AGELags,'VariableNames',lagNames); % Preallocate tables and models: DTAL = cell(maxLag,1); MAL = cell(maxLag,1); % Fit models: AL = AGELags; DT = DataTable; for lagOrder = lags lagRange = 1:lagOrder; % Trim next presample row: AL(1,:) = []; DT(1,:) = []; % Fit model: DTAL{lagOrder} = [AL(:,lagRange),DT]; MAL{lagOrder} = fitlm(DTAL{lagOrder}); MALName{lagOrder} = strcat('MAL',num2str(lagRange,'%u')); end
We begin by considering the model with AGE lag order 2, that is, with AGE data on issuers first rated 3 years ago, and lagged AGE data on issuers first rated 4 and 5 years ago:
MAL12 = MAL{2}MAL12 =
Linear regression model:
IGD ~ 1 + AGELag1 + AGELag2 + AGE + BBB + CPF + SPR
Estimated Coefficients:
Estimate SE tStat pValue
_________ _________ _______ ________
(Intercept) -0.31335 0.12871 -2.4345 0.031471
AGELag1 0.0030903 0.012504 0.24714 0.80898
AGELag2 0.014322 0.0090639 1.5802 0.14006
AGE 0.017683 0.010243 1.7263 0.10993
BBB 0.003078 0.0035264 0.87284 0.39988
CPF -0.013744 0.0047906 -2.869 0.014115
SPR 0.030392 0.034582 0.87883 0.39675
Number of observations: 19, Error degrees of freedom: 12
Root Mean Squared Error: 0.0723
R-squared: 0.732, Adjusted R-Squared: 0.598
F-statistic vs. constant model: 5.46, p-value = 0.00618
The lagged variables reduce the sample size by two. Together with two new estimated coefficients, the degrees of freedom are reduced by 4, to 12.
The model fit, as measured by the root-mean-squared error and the adjusted statistic (which accounts for the additional predictors), is slightly improved relative to M0. The significance of the predictors already in M0, as measured by the p values of their t-statistics, is reduced. This is typical when predictors are added, unless the new predictors are completely insignificant. The overall F-statistic shows that the extended model has a slightly reduced significance in describing the variation of the response.
Of the two new predictors, AGELag2 appears to be much more significant than AGELag1. This is difficult to interpret in economic terms, and it brings into question the accuracy of the significance measures. Are the p-values an artifact of the small-sample size? Are they affected by violations of the CNLM assumptions that underly ordinary least squares (OLS) estimation? In short, do they provide a legitimate reason to modify the lag structure? Obtaining reliable answers to these questions in realistically-sized economic data samples is often a challenge.
The distribution of any diagnostic statistic depends on the distribution of process innovations, as exhibited in the model residuals. For t and F tests, normal innovations are sufficient to produce test statistics with t and F distributions in finite samples. If the innovations depart from normality, however, statistics may not follow these expected distributions. Tests suffer from size distortions, where nominal significance levels misrepresent the actual frequency of rejecting the null hypothesis. When this happens, inferences about predictor significance become unreliable.
This is a fundamental problem in specification analysis, since at any stage in the process, candidate models are likely to be misspecified, and data incompletely filtered. Tests results must be considered in the context of the residual series. A normal probability plot of the MAL12 residuals shows some reason to suspect the reported p-values:
resAL12 = MAL12.Residuals.Raw; normplot(resAL12) xlabel('Residual') title('{\bf MAL12 Residuals}')
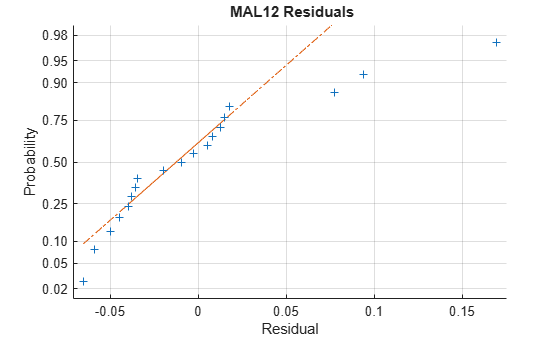
A common belief is that t and F tests are robust to nonnormal innovations. To some degree, this is true. Innovations from elliptically symmetric distributions, such as t distributions, which generalize the multivariate normal distribution, produce t and F statistics that follow t and F distributions in finite samples [12]. This result, however, assumes a diagonal covariance structure. When innovations exhibit heteroscedasticity and autocorrelation, standard t and F tests become much less robust [5], [16]. Size distortions can be substantial in finite samples. Practically, however, the nature of the innovations distribution, and the degree of distortion, can be difficult to measure.
Robust Tests
t and F statistics involve both coefficient estimates and their standard errors. In the presence of heteroscedasticity or autocorrelation, OLS coefficient estimates remain unbiased, provided the predictors are exogenous. Standard errors, however, when estimated with the usual CNLM formulas, are biased.
One response is to form statistics using standard error estimates that are robust to nonspherical innovations [2], [3], as in the example Time Series Regression X: Generalized Least Squares and HAC Estimators. We illustrate this strategy here.
The p-value of a t statistic is usually computed using Student's t distribution. For example, for AGELag2 in MAL12:
AGELag2Idx = find(strcmp(MAL12.CoefficientNames,'AGELag2'));
coeff_AGELag2 = MAL12.Coefficients.Estimate(AGELag2Idx);
se_AGELag2 = MAL12.Coefficients.SE(AGELag2Idx);
t_AGELag2 = coeff_AGELag2/se_AGELag2;
dfeAL12 = MAL12.DFE;
p_AGELag2 = 2*(1-tcdf(t_AGELag2,dfeAL12))p_AGELag2 = 0.1401
This is the p-value reported in the previous display of MAL12.
Using heteroscedasticity-consistent (HC), or more general heteroscedasticity-and-autocorrelation-consistent (HAC), estimates of the standard error, while continuing to assume a Student's t distribution for the resulting statistics, leads to very different p-values:
% HC estimate: [~,seHC] = hac(MAL12,'type','HC','weights','HC3','display','off'); se_AGELag2HC = seHC(AGELag2Idx); t_AGELag2HC = coeff_AGELag2/se_AGELag2HC; p_AGELag2HC = 2*(1-tcdf(t_AGELag2HC,dfeAL12))
p_AGELag2HC = 0.3610
% HAC estimate: [~,seHAC] = hac(MAL12,'type','HAC','weights','BT','display','off'); se_AGELag2HAC = seHAC(AGELag2Idx); t_AGELag2HAC = coeff_AGELag2/se_AGELag2HAC; p_AGELag2HAC = 2*(1-tcdf(t_AGELag2HAC,dfeAL12))
p_AGELag2HAC = 0.0688
The HC p-value shows AGELag2 to be relatively insignificant, while the HAC p-value shows it to be potentially quite significant. The CNLM p-value lies in-between.
There are a number of problems with drawing reliable inferences from these results. First, without a more thorough analysis of the residual series (as in the example Time Series Regression VI: Residual Diagnostics), there is no reason to choose one standard error estimator over the other. Second, the standard error estimates are only consistent asymptotically, and the sample here is small, even by econometric standards. Third, the estimators require several, sometimes arbitrarily selected, nuisance parameters ('weights', 'bandwidth', 'whiten') that can significantly change the results, especially in small samples. Finally, the newly-constituted t and F statistics, formed with the robust standard errors, do not follow t and F distributions in finite samples.
In short, the significance estimates here may be no better than the traditional ones, based on CNLM assumptions. Modifications of HAC-based tests, such as KVB tests [11], are effective in addressing issues with individual nuisance parameters, but they do not address the larger problem of applying asymptotic techniques to finite samples.
Bootstrapped Tests
Another response to size distortions in traditional specification tests is bootstrapping. The test statistic computed from the original data is maintained, but its distribution is re-evaluated through simulated resampling, with the goal of producing a more accurate p-value.
Resampling data from a population is a standard technique for evaluating the distribution of a statistic. The nature of economic time series, however, usually makes this impractical. Economies have fixed histories. Generating realistic alternative paths, with statistical properties similar to empirical data, requires additional assumptions.
In a bootstrapped test, a null model is fit to the available data, and the null distribution of residuals is used to approximate the population distribution of innovations. The residuals are then resampled, with replacement, to generate new residual series. Corresponding bootstrap responses are computed using the fixed predictor histories. Finally, the new response data is used to refit the alternative (original) model and recompute the test statistic. This process is repeated, to generate a bootstrapped distribution.
For comparison, we bootstrap the t statistic of AGELag2 under the null hypothesis that its coefficient is zero. The null model is:
MAL1 = MAL{1}MAL1 =
Linear regression model:
IGD ~ 1 + AGELag1 + AGE + BBB + CPF + SPR
Estimated Coefficients:
Estimate SE tStat pValue
_________ _________ ________ _________
(Intercept) -0.1708 0.11961 -1.428 0.17521
AGELag1 -0.011149 0.011266 -0.98959 0.33917
AGE 0.01323 0.010845 1.2198 0.24268
BBB 0.0062225 0.0033386 1.8638 0.083456
CPF -0.017738 0.0047775 -3.7129 0.0023176
SPR 0.05048 0.036097 1.3985 0.18373
Number of observations: 20, Error degrees of freedom: 14
Root Mean Squared Error: 0.0786
R-squared: 0.634, Adjusted R-Squared: 0.503
F-statistic vs. constant model: 4.84, p-value = 0.00885
AGELag1, highly insignificant in the model MAL12 that includes both AGELag1 and AGELag2, becomes more significant in the absence of AGELag2, but its role is still minor relative to the predictors in M0. Its coefficient becomes negative, contrary to our understanding of it as a predictor of default risk. The inference may be that AGELag1 is irrelevant. Nevertheless, we maintain it to evaluate the specific restriction of MAL12 to MAL1, reducing the lag order by 1:
DTAL1 = DTAL{1}; % Lag order 1 table
DTAL12 = DTAL{2}; % Lag order 2 table (one less observation)
numBoot = 1e3; % Number of statistics
res0 = MAL1.Residuals.Raw; % Bootstrap "population"
[~,IdxBoot] = bootstrp(numBoot,[],res0); % Bootstrap indices
ResBoot = res0(IdxBoot); % Bootstrap residuals
IGD0 = DTAL1.IGD - res0; % Residual-free response
IGDB = zeros(size(DTAL12,1),numBoot); % Bootstrap responses
DTBoot = DTAL12;
tBoot = zeros(numBoot,1); % Bootstrap t statistics
for boot = 1:numBoot
IGDBoot = IGD0 + ResBoot(:,boot);
IGDBoot(1) = []; % Trim to size of DTBoot
IGDBoot(IGDBoot < 0) = 0; % Set negative default rates to 0
DTBoot.IGD = IGDBoot;
MBoot = fitlm(DTBoot);
tBoot(boot) = MBoot.Coefficients.tStat(AGELag2Idx);
IGDB(:,boot) = IGDBoot;
endThe procedure generates numBoot bootstrap responses, which replace the original response to the fixed predictor data:
figure hold on bootDates = dates(3:end); hIGD = plot(bootDates,IGDB,'b.'); hIGDEnd = plot(bootDates,IGDB(:,end),'b-'); hIGD0 = plot(bootDates,DTAL12.IGD,'ro-','LineWidth',2); hold off xlabel('Date') ylabel('Default Rate') title('{\bf Bootstrap Responses}') legend([hIGD(end),hIGDEnd,hIGD0],'Bootstrap Responses',... 'Typical Bootstrap Response',... 'Empirical Response',... 'Location','NW')
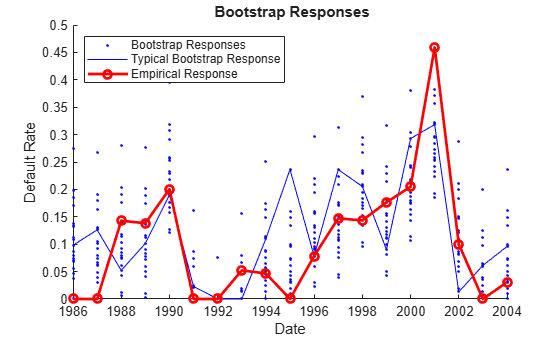
The bootstrapped p-value is not very different from the original p-value, p_AGELag2, found using Student's t distribution:
p_AGELag2
p_AGELag2 = 0.1401
p_AGELag2Boot = sum(tBoot > t_AGELag2)/length(tBoot)
p_AGELag2Boot = 0.1380
However, a histogram shows that the distribution of bootstrapped t statistics has shifted:
figure hold on numBins = 50; hHist = histogram(tBoot,numBins,'Normalization','probability',... 'FaceColor',[.8 .8 1]); x = hHist.BinLimits(1):0.001:hHist.BinLimits(end); y = tpdf(x,dfeAL12); hPDF = plot(x,y*hHist.BinWidth,'m','LineWidth',2); hStat = plot(t_AGELag2,0,'ro','MarkerFaceColor','r'); line([t_AGELag2 t_AGELag2],1.2*[0 max(hHist.Values)],'Color','r') axis tight legend([hHist,hPDF,hStat],'Bootstrap {\it t} Distribution',... 'Student''s {\it t} Distribution',... 'Original {\it t} Statistic',... 'Location','NE') xlabel('{\it t}') title('{\bf Bootstrap {\it t} Statistics}') hold off
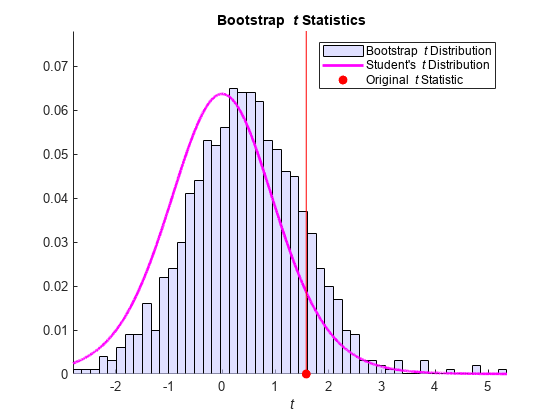
The t statistic is less significant in the bootstrap distribution, suggesting the possible influence of nonspherical innovations on the original test.
The bootstrapped test has its own difficulties. To enforce nonnegativity of default rates, it is necessary to trim bootstrapped responses with negative values. The consequences for inference are unclear. Moreover, the bootstrapped test relies, fundamentally, on the assumption that the empirical distribution of residuals faithfully represents the relevant characteristics of the distribution of innovations in the DGP. In smaller samples, this is hard to justify.
There are many variations of the bootstrap. For example, the wild bootstrap [7], which combines robust estimation with residual resampling, seems to perform well with smaller samples in the presence of heteroscedasticity.
Likelihood-Based Tests
Versions of t and F tests, formulated using CNLM assumptions, can provide reliable inferences in a variety of situations where the innovations distribution departs from specification. Likelihood-based tests, by contrast, require a formal model of the innovations to operate at all. Data likelihoods are typically computed under the assumption of independent and normally distributed innovations with fixed variance. This underlying model of the DGP can be adjusted to accommodate different innovation patterns, including higher probabilities for extreme events, but the strong distributional assumption remains.
Like F statistics, data likelihoods (or, in practice, loglikelihoods) measure the fit of an entire model, or lag structure, rather than the significance of individual model terms. Likelihoods are based on the joint probability of the data under the distributional assumption, rather than on residual sums of squares. Larger likelihoods indicate a better fit, but to evaluate the relative quality of models, the statistical significance of likelihood differences must be evaluated.
Consider the normal loglikelihoods of the OLS estimates of MAL12 and its restrictions. We begin by constructing MAL2, with only AGELag2, to complete the set of restrictions considered:
DTAL2 = [AGELags(:,2),DataTable]; MAL2 = fitlm(DTAL2)
MAL2 =
Linear regression model:
IGD ~ 1 + AGELag2 + AGE + BBB + CPF + SPR
Estimated Coefficients:
Estimate SE tStat pValue
_________ _________ _______ _________
(Intercept) -0.29694 0.10622 -2.7955 0.01516
AGELag2 0.013694 0.0083803 1.6341 0.12621
AGE 0.017022 0.0095247 1.7872 0.097235
BBB 0.0035843 0.0027645 1.2965 0.21733
CPF -0.014476 0.0036275 -3.9907 0.0015388
SPR 0.033047 0.031661 1.0438 0.31562
Number of observations: 19, Error degrees of freedom: 13
Root Mean Squared Error: 0.0696
R-squared: 0.731, Adjusted R-Squared: 0.627
F-statistic vs. constant model: 7.05, p-value = 0.00216
% Unrestricted loglikelihood of MAL12:
uLLOLS = MAL12.LogLikelihooduLLOLS = 27.3282
% Restricted loglikelihoods of M0, MAL1, and MAL2:
rLLOLS = [M0.LogLikelihood;MAL1.LogLikelihood;MAL2.LogLikelihood]rLLOLS = 3×1
27.0796
26.0606
27.2799
These are OLS loglikelihoods, based on the residual series. For example, the loglikelihood of the data with respect to M0 is computed using:
resM0 = M0.Residuals.Raw; MSEM0 = M0.MSE; muM0 = mean(resM0); LLM0 = sum(log(normpdf(resM0,muM0,sqrt(MSEM0))))
LLM0 = 26.7243
Since OLS does not, necessarily, maximize likelihoods, unless CNLM assumptions are satisfied, it is possible for restrictions of the model parameter space to increase data likelihoods. We see this for the restrictions M0 and MAL2. This suggests, once again, a nonnormal innovations process.
For comparison, consider measures based on maximum likelihood estimates (MLEs) of model coefficients, using the arima function. We fit ARMAX models with zero-order AR and MA specifications (that is, pure regression models):
% Prepare data: LLOLS = [uLLOLS;rLLOLS]; DataAL12 = table2array(DTAL12); y = DataAL12(:,7); X = DataAL12(:,1:6); PredCols = {1:6,3:6,[1,3:6],2:6}; ModelNames = {'MAL12','M0','MAL1','MAL2'}; % Compute MLEs: LLMLE = zeros(4,1); Mdl = arima(0,0,0); options = optimoptions(@fmincon,'Display','off','Diagnostics','off',... 'Algorithm','sqp','TolCon',1e-7); for model = 1:4 [~,~,LL] = estimate(Mdl,y,'X',X(:,PredCols{model}),... 'Display','off','Options',options); LLMLE(model) = LL; end % Display results: fprintf('\nLoglikelihoods\n')
Loglikelihoods
fprintf('\n%-8s%-9s%-9s','Model |','OLSLL','MLELL')
Model | OLSLL MLELL
fprintf(['\n',repmat('=',1,24)])
========================
for model = 1:4 fprintf(['\n%-6s','| ','%-9.4f%-9.4f'],... ModelNames{model},LLOLS(model),LLMLE(model)) end
MAL12 | 27.3282 27.3282 M0 | 27.0796 25.5052 MAL1 | 26.0606 25.5324 MAL2 | 27.2799 27.2799
In the case of MLEs, all of the restricted models have a reduced likelihood of describing the data, as expected. The OLS and MLE measures disagree on the model of largest likelihood, with OLS choosing M0, and MLE choosing MAL12.
Are the differences in likelihood significant? For MLEs, this question has traditionally been addressed by some version of the likelihood ratio test (implemented by lratiotest), the Wald test (implemented by waldtest), or the Lagrange multiplier test (implemented by lmtest). These are discussed in the example Classical Model Misspecification Tests (CMM tests). The geometry of comparison for CMM tests is based, fundamentally, on the optimality of the model coefficients. They should not be used with OLS likelihoods unless there is evidence that CNLM assumptions are satisfied.
Like F tests, CMM tests are only applicable to comparisons of nested models, which are restrictions or extensions of each other. This is the typical situation when evaluating lag structures. Unlike F tests, CMM tests are applicable to comparisons involving nonlinear models, nonlinear restrictions, and nonnormal (but fully specified) innovation distributions. This is important in certain econometric settings, but rarely in lag order selection. A disadvantage of CMM tests is that they assign significance to model differences only asymptotically, and so must be used with caution in finite samples.
For example, the likelihood ratio test, the most direct assessment of MLE likelihood differences, can be used to evaluate the adequacy of various restrictions:
% Restrictions of |MAL12| to |M0|, |MAL1|, and |MAL2|: dof = [2;1;1]; % Number of restrictions [hHist,pValue] = lratiotest(LLMLE(1),LLMLE(2:4),dof)
hHist = 3×1 logical array
0
0
0
pValue = 3×1
0.1615
0.0581
0.7561
% Restrictions of |MAL1| and |MAL2| to |M0|: dof = [1;1]; % Number of restrictions [hHist,pValue] = lratiotest(LLMLE(3:4),LLMLE(2),dof)
hHist = 2×1 logical array
0
0
pValue = 2×1
0.8154
0.0596
At the default 5% significance level, the test fails to reject the null, restricted model in favor of the alternative, unrestricted model in all cases. That is, the statistical case for including any lag structure is weak. The original model, M0, might be chosen solely for reasons of model parsimony.
An alternative to CMM tests are the various forms of information criteria (IC). IC also consider goodness-of-fit, measured by likelihoods, but penalize for lack of parsimony, measured by the number of model coefficients. As with pure likelihoods, adjusted IC likelihoods provide a relative, but not an absolute, measure of model adequacy. However, there are no commonly-used hypothesis tests, corresponding to CMM tests, for evaluating the significance of IC differences. The main advantage, in practice, is that IC can be used to compare non-nested models, though this is often irrelevant when comparing lag structures.
The following table compares two common IC, AIC and BIC, together with the OLS equivalent, the adjusted :
AR2 = [MAL12.Rsquared.Adjusted; M0.Rsquared.Adjusted; ... MAL1.Rsquared.Adjusted; MAL2.Rsquared.Adjusted]; AIC = [MAL12.ModelCriterion.AIC; M0.ModelCriterion.AIC; ... MAL1.ModelCriterion.AIC; MAL2.ModelCriterion.AIC]; BIC = [MAL12.ModelCriterion.BIC; M0.ModelCriterion.BIC; ... MAL1.ModelCriterion.BIC; MAL2.ModelCriterion.BIC]; fprintf('\nSize-Adjusted Fit\n')
Size-Adjusted Fit
fprintf('\n%-8s%-7s%-9s%-9s','Model |','AR2','AIC','BIC')
Model | AR2 AIC BIC
fprintf(['\n',repmat('=',1,32)])
================================
for model = 1:4 fprintf(['\n%-6s','| ','%-7.4f','%-9.4f','%-9.4f'],... ModelNames{model},AR2(model),AIC(model),BIC(model)) end
MAL12 | 0.5979 -40.6563 -34.0452 M0 | 0.5264 -44.1593 -38.9367 MAL1 | 0.5028 -40.1213 -34.1469 MAL2 | 0.6269 -42.5598 -36.8932
When comparing models, higher adjusted , and lower IC, indicate a better trade-off between the fit and the reduced degrees of freedom. The results show a preference for including a lag structure when evaluated by adjusted , but not when evaluated by IC. This kind of disagreement is not uncommon, especially with small samples, and further suggests the comparative use of multiple testing methods.
BIC, with its typically heavier penalties on additional coefficients, tends to choose simpler models, though often not as simple as those selected by sequential t and F testing with standard settings. BIC has some superior large-sample properties, such as being asymptotically consistent, but Monte Carlo studies have shown AIC can outperform BIC in correctly identifying the DGP in small data samples [6]. An alternative version of AIC, AICc, corrects for small samples, and is especially useful in these situations.
Testing Up, Testing Down
When attempting to specify significant but parsimonious lag structures in econometric models, two general strategies are often used. The first is to start with a small model, then test additional lags until their individual significance, or the joint significance of the entire lag structure, drops below a set level. This is called testing up. Alternatively, a generous initial lag structure is systematically trimmed until the largest lag, or the entire lag structure, becomes significant. This is called testing down.
Testing up starts with a parsimonious description of the data, such as a static model with contemporaneous values of relevant predictors but no dynamic terms. It then proceeds from the specific to the general. Each step in the process evaluates the effect of adding a new lag, usually using some combination of t tests, F tests, CMM tests, or IC. It stops when adding a new lag becomes insignificant at some predetermined level. It guarantees, in this way, that the initial model parsimony is maintained to some degree.
Acknowledging Occam's razor and principles of scientific method, testing up offers a number of advantages. Simple models are less costly to compute, easier to interpret and detect misspecification, work better with small samples, and are more amenable to generalization. Moreover, they often produce better forecasts [10].
However, testing up is often discouraged for lag order selection, and economic modeling in general. There is a common scenario where significant lags lie beyond the first insignificant one, such as with seasonal lags. Automatic testing up will not detect these. Moreover, sequential testing in the presence of omitted variables, which have not yet been added to the model, creates estimator bias and distortions of test sizes and power, ultimately leading to incorrect inferences. Omitted variable bias is discussed in the examples Time Series Regression IV: Spurious Regression and Time Series Regression VIII: Lagged Variables and Estimator Bias.
As a consequence, testing down is often recommended [9]. This strategy begins with a model that includes all potential explanatory variables. That is, it includes a mix of predictors with more or less significance in explaining the variation of the response. It then proceeds from the general to the specific (sometimes called GETS). Each step in the process evaluates the effect of removing a predictor, using the same sorts of tests used for testing up. It stops when the restricted model achieves some predetermined level of significance.
There are several advantages to this approach. If the initial model and lag structure is comprehensive enough, then all of the testing is done, at least in principle, in the absence of omitted variable bias. Localized tests, such as tests on the largest lag, can lead to models that continue to contain a mix of significant and insignificant lags, but since they are all present in the model, they can be examined for joint significance. A disadvantage to this approach is the lack of theoretical guidance, or even good heuristic tips, when choosing the initial lag order in different modeling situations.
The following table shows p values of t statistics on coefficients of lagged AGE in lag structures of order 1 to 5:
fprintf('\nt Statistic p Values\n')t Statistic p Values
fprintf('\n%-11s%-5s%-5s%-5s%-5s%-5s','Model |',... 'AL1','AL2','AL3','AL4','AL5')
Model | AL1 AL2 AL3 AL4 AL5
fprintf(['\n',repmat('=',1,35)])
===================================
for lag = 1:5 pVals = MAL{lag}.Coefficients.pValue(2:lag+1); fprintf(['\n%-9s','| ',repmat('%-5.2f',1,lag)],... MALName{lag},pVals(1:lag)) end
MAL1 | 0.34 MAL12 | 0.81 0.14 MAL123 | 0.77 0.45 0.44 MAL1234 | 0.55 0.76 0.55 0.30 MAL12345 | 0.88 0.91 0.19 0.14 0.29
At a 15% significance level, testing up from M0 adds no lags to the model, since it fails to reject a zero coefficient for AgeLag1 in the first model tested, MAL1. At the same level, testing down from the largest model, sequentially evaluating the significance of the largest lag, MAL12 is selected, adding two lags to M0. The relative significance of specific lags across different lag structures highlights the risk of automating these localized evaluations.
F statistics add useful information about joint significance. F tests on additional lags, relative to the model with all previous lags, are equivalent to t tests, with the same p values. However, F tests of an entire lag structure, relative to a static specification, can provide hints of significant lags prior to the largest lag. F ratios are computed by the coefTest method of the LinearModel class:
fprintf('\nF Statistic p Values\n')F Statistic p Values
fprintf('\n%-11s%-5s%-5s','Model |','Last','All')
Model | Last All
fprintf(['\n',repmat('=',1,20)])
====================
for lag = 1:5 % Sequential F test (last lag = 0): HSq = [zeros(1,lag),1,zeros(1,4)]; pSq = coefTest(MAL{lag},HSq); % Static F test (all lags = 0): HSt = [zeros(lag,1),eye(lag),zeros(lag,4)]; pSt = coefTest(MAL{lag},HSt); fprintf(['\n%-9s','| ','%-5.2f','%-5.2f'],MALName{lag},pSq,pSt) end
MAL1 | 0.34 0.34 MAL12 | 0.14 0.32 MAL123 | 0.44 0.65 MAL1234 | 0.30 0.74 MAL12345 | 0.29 0.54
The F statistics cannot jump-start a stalled testing-up strategy, but when testing down, they do give reason to reconsider the largest model, with its relatively lower p value. The increased significance of AgeLag3 and AgeLag4 in MAL12345, indicated by the t statistic p values, raise the joint significance of that lag structure. Still, the most significant overall lag structure is in MAL12, consistent with testing-down via t statistics.
Predictably, Monte Carlo studies show that automated testing up strategies will frequently under-fit when the DGP is a supermodel, and testing down will likewise over-fit when the DGP is a submodel [14]. Performance, in either case, is improved by systematically adjusting significance levels to account for varying degrees of freedom. In general, however, the statistical consequences of excluding relevant lags is usually considered more serious than including irrelevant lags, and rejection tolerances must be set accordingly.
In practice, hybrid strategies are usually preferred, moving predictors in and out of the model until some measure of fit is optimized, and an economically sensible model is obtained. Stepwise regression (described in the example Time Series Regression V: Predictor Selection) is one way to automate this approach. With modern computing power, there is also the possibility, in some cases, to exhaustively evaluate all models of relevance. As this example illustrates, however, automation of model selection procedures must be viewed with some skepticism. The process is necessarily dynamic, tests have varying degrees of relevance, and decisions ultimately require some consideration of economic theory and modeling goals.
Special Cases
Because of the difficulties of using standard testing procedures in modeling contexts where CNLM assumptions are violated, a number of specialized procedures have been developed for use with specific model types. In some cases, appropriate lag orders can be determined solely through data analysis. Other cases require sequential estimation and evaluation of a range of candidate models.
ARMA Models. Stationary time series are often represented, theoretically, by infinite-order MA processes [18]. ARMA models translate these representations into finite, rational form. Lag orders for the AR and MA components of a model must be chosen together, to achieve a balance between accuracy and model parsimony. The standard identification method [4], described in the example Programmatically Select ARIMA Model for Time Series Using Box-Jenkins Methodology, examines patterns in sample autocorrelation functions to determine the relative significance of candidate lag structures.
ARDL Models. Many economic variables are influenced by exogenous driving processes that can impart persistent shocks to a DGP. Theoretically, these are represented by infinite-order DL models, but as with ARMA models, finite, rational forms are required for practical estimation. Standard techniques, such as those proposed by Almon [1] and Koyck [13], assign weights to the lag structure in such a way that the model can be transformed into AR, ARMA, or ARMAX form. The methods are more ad hoc than data-driven, and subject to the problems of collinearity that come from working with many lags of a predictor at proximate times. (See the example Time Series Regression II: Collinearity and Estimator Variance.)
GARCH Models. GARCH models are commonly used to model patterns of heteroscedasticity in an innovations process, especially in financial applications. Like ARMA and ARDL models, they combine two types of lags, with orders that must be balanced appropriately. In practice, there are methods for transforming GARCH models to ARMA form [8], where Box-Jenkins methods can be applied, but this is rarely done in practice. For most economic and financial series, lag orders of 1 and 1 seem to serve well.
Unit Root Tests. Unit root and stationarity tests, such as
adftestandlmctest, use dynamic models of the test process, and require users to choose a lag order. This nuisance parameter can have significant effect on the test results. The potential presence of nonstationary data in this setting calls into question the use of standard t and F tests. However, Sims, Stock, and Watson [17] have shown that they are justified when the regression includes all deterministic components of the DGP.VAR Models. VAR models are a generic, widely-used form for representing systems of interacting economic variables. They require a lag order that captures the relevant past history of all variables in the model. Since the models are multivariate, estimation costs grow quickly with increasing lag order, so a parsimonious selection procedure is essential. Lütkepohl [15] discusses a variety of strategies, most of which are multivariate generalizations of the techniques presented in this example.
Summary
This example surveys common strategies for lag order selection, and makes the case for adapting strategies to individual data sets and models. The data considered here are few, and far from the idealizations of asymptotic analysis. It is also quite possible the model under study may be misspecified, confounding its own evaluation. However, these obstacles are fairly typical in econometric practice. Without considered, "hands-on" application, guided by some sense of economic reality, lag order selection presents many opportunities for distorted inference that can lead to poorly performing models. Familiarity with the common difficulties, however, can help guide the path to sharper specifications.
Of course, it is not always necessary to choose a "best" model or lag order. Often, given the statistical uncertainty, it is enough to eliminate a large subset of highly unlikely candidates, leaving a smaller subset for further analysis and data collection. The strategies of this example serve that purpose well.
References
[1] Almon, S. "The Distributed Lag Between Capital Appropriations and Expenditures." Econometrica. Vol. 33, 1965, pp. 178–196.
[2] Andrews, D. W. K. "Heteroskedasticity and Autocorrelation Consistent Covariance Matrix Estimation." Econometrica. Vol. 59, 1991, pp. 817–858.
[3] Andrews, D. W. K., and J. C. Monohan. "An Improved Heteroskedasticity and Autocorrelation Consistent Covariance Matrix Estimator." Econometrica. Vol. 60, 1992, pp. 953–966.
[4] Box, George E. P., Gwilym M. Jenkins, and Gregory C. Reinsel. Time Series Analysis: Forecasting and Control. 3rd ed. Englewood Cliffs, NJ: Prentice Hall, 1994.
[5] Banerjee, A. N., and J. R. Magnus. "On the Sensitivity of the Usual t- and F-Tests to Covariance Misspecification." Journal of Econometrics. Vol. 95, 2000, pp. 157–176.
[6] Burnham, Kenneth P., and David R. Anderson. Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach. 2nd ed, New York: Springer, 2002.
[7] Davidson, R., and E. Flachaire. "The Wild Bootstrap, Tamed at Last." Journal of Econometrics. Vol. 146, 2008, pp. 162–169.
[8] Hamilton, James D. Time Series Analysis. Princeton, NJ: Princeton University Press, 1994.
[9] Hendry, D. F. Econometrics: Alchemy or Science? Oxford: Oxford University Press, 2001.
[10] Keuzenkamp, H. A., and M. McAleer. "Simplicity, Scientific Inference and Economic Modeling." Economic Journal. Vol. 105, 1995, pp. 1–21.
[11] Kiefer, N. M., T. J. Vogelsang, and H. Bunzel. "Simple Robust Testing of Regression Hypotheses." Econometrica. Vol. 68, 2000, pp. 695–714.
[12] King, M. L. "Robust Tests for Spherical Symmetry and Their Application to Least Squares Regression." Annals of Statistics. Vol. 8, 1980, pp. 1265–1271.
[13] Koyck, L. M. Distributed Lags Models and Investment Analysis. Amsterdam: North-Holland, 1954.
[14] Krolzig, H. -M., and Hendry, D.F. "Computer Automation of General-To-Specific Model Selection Procedures." Journal of Economic Dynamics & Control. Vol. 25, 2001, pp. 831–866.
[15] Lütkepohl, Helmut. New Introduction to Multiple Time Series Analysis. New York, NY: Springer-Verlag, 2007.
[16] Qin, H., and A. T. K. Wan. "On the Properties of the t- and F-Ratios in Linear Regressions with Nonnormal Errors." Econometric Theory. Vol. 20, No. 4, 2004, pp. 690–700.
[17] Sims, C., Stock, J., and Watson, M. "Inference in Linear Time Series Models with Some Unit Roots." Econometrica. Vol. 58, 1990, pp. 113–144.
[18] Wold, Herman. "A Study in the Analysis of Stationary Time Series." Journal of the Institute of Actuaries 70 (March 1939): 113–115. https://doi.org/10.1017/S0020268100011574.