irf
Generate vector error-correction (VEC) model impulse responses
Syntax
Description
The irf function returns the dynamic response, or the impulse response
function (IRF), to a one-standard-deviation shock to each variable in a VEC(p – 1)
model. A fully specified vecm model object
characterizes the VEC model.
IRFs trace the effects of an innovation shock to one variable on the response of all
variables in the system. In contrast, the forecast error variance decomposition (FEVD)
provides information about the relative importance of each innovation in affecting all
variables in the system. To estimate the FEVD of a VEC model characterized by a
vecm model object, see fevd.
You can supply optional data, such as a presample, as a numeric array, table, or
timetable. However, all specified input data must be the same data type. When the input model
is estimated (returned by estimate), supply
the same data type as the data used to estimate the model. The data type of the outputs
matches the data type of the specified input data.
Response = irf(Mdl)Mdl characterized by a
fully specified vecm model object.
irf shocks variables at time 0, and returns the IRF for
times 0 through 19.
If Mdl is an estimated model (returned by estimate) fit to
a numeric matrix of input response data, this syntax applies.
Response = irf(Mdl,Name,Value)irf(Mdl,NumObs=10,Method="generalized") specifies estimating a
generalized IRF for 10 time points starting at time 0, during which
irf applies the shock.
If Mdl is an estimated model (returned by estimate) fit to
a numeric matrix of input response data, this syntax applies.
[
returns numeric arrays of lower Response,Lower,Upper] = irf(___)Lower and upper
Upper 95% confidence bounds for confidence intervals on the true
IRF, for each period and variable in the IRF, using any input argument combination in the
previous syntaxes. By default, irf estimates confidence
bounds by conducting Monte Carlo simulation.
If Mdl is an estimated model fit to a numeric matrix of input
response data, this syntax applies.
If Mdl is a custom vecm model object
(an object not returned by estimate or
modified after estimation), irf can require a sample size for
the simulation SampleSize or presample responses
Y0.
Tbl = irf(___)Tbl containing the IRFs and, optionally, corresponding 95%
confidence bounds, of the response variables that compose the VEC(p –
1) model Mdl. The variables in Tbl correspond to
the variables in the system shocked at time 0. Each variable contains a matrix with
columns corresponding to the IRFs of the variables in the system. (since R2022b)
If you set at least one name-value argument that controls the 95% confidence bounds on
the IRF, Tbl also contains a variable for each of the lower and upper
bounds. For example, Tbl contains confidence bounds when you set the
NumPaths name-value argument.
If Mdl is an estimated model fit to a table or timetable of input
response data, this syntax applies.
Examples
Fit a 4-D VEC(2) model with two cointegrating relations to Danish money and income rate series data in a numeric matrix. Then, estimate the orthogonalized IRF from the estimated model.
Load the Danish money and income data set.
load Data_JDanishThe data set includes four time series in the table DataTable. For more details on the data set, enter Description at the command line.
Create a vecm model object that represents a 4-D VEC(2) model with two cointegrating relations. Specify the variable names.
Mdl = vecm(4,2,2); Mdl.SeriesNames = DataTable.Properties.VariableNames;
Mdl is a vecm model object specifying the structure of a 4-D VEC(2) model; it is a template for estimation.
Fit the VEC(2) model to the numeric matrix of time series data Data.
EstMdl = estimate(Mdl,Data);
Mdl is a fully specified vecm model object representing an estimated 4-D VEC(2) model.
Estimate the orthogonalized IRF from the estimated VEC(2) model.
Response = irf(EstMdl);
Response is a 20-by-4-by-4 array representing the IRF of Mdl. Rows correspond to consecutive time points from time 0 to 19, columns correspond to variables receiving a one-standard-deviation innovation shock at time 0, and pages correspond to responses of variables to the variable being shocked. Mdl.SeriesNames specifies the variable order.
Display the IRF of the bond rate (variable 3, IB) when the log of real income (variable 2, Y) is shocked at time 0.
Response(:,2,3)
ans = 20×1
0.0021
0.0057
0.0064
0.0067
0.0064
0.0061
0.0057
0.0056
0.0057
0.0058
0.0059
0.0059
0.0059
0.0059
0.0059
⋮
The armairf function plots the IRF of VAR models characterized by AR coefficient matrices. Plot the IRF of a VEC model by:
Expressing the VEC(2) model as a VAR(3) model by passing
MdltovarmPassing the VAR model AR coefficients and innovations covariance matrix to
armairf
Plot the VEC(2) model IRF for 40 periods.
VARMdl = varm(EstMdl);
armairf(VARMdl.AR,[],InnovCov=VARMdl.Covariance, ...
NumObs=40);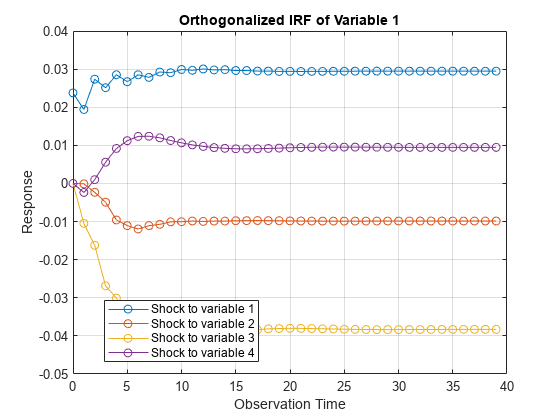
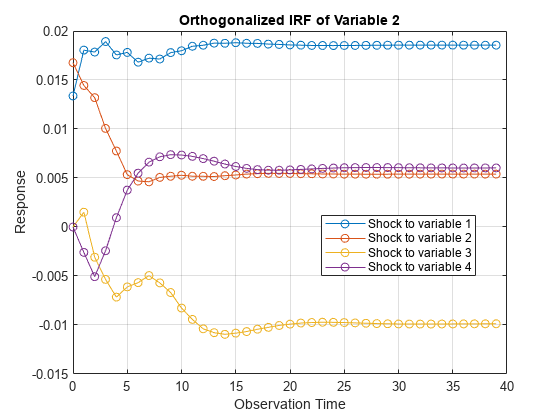
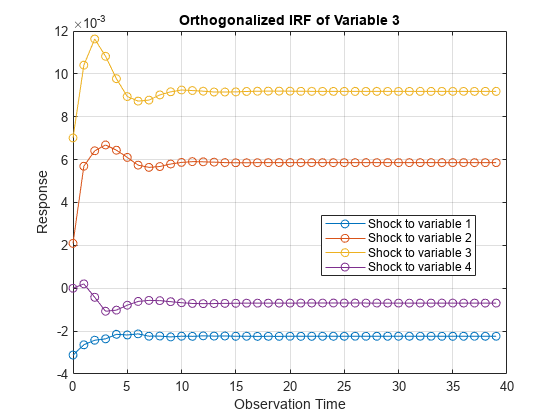
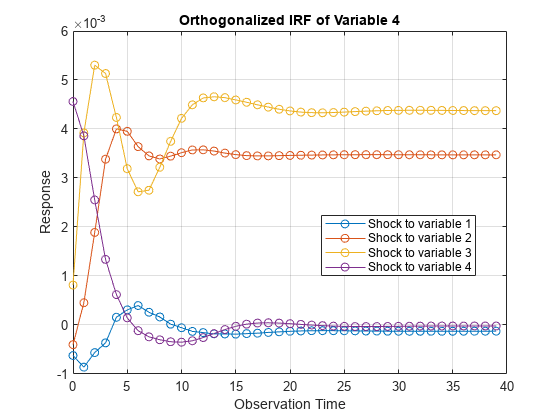
Each plot shows the four IRFs of a variable when all other variables are shocked at time 0. Mdl.SeriesNames specifies the variable order.
Consider the 4-D VEC(2) model with two cointegrating relations in Specify Data in Numeric Matrix When Plotting IRF. Estimate the generalized IRF of the system for 50 periods.
Load the Danish money and income data set, then estimate the VEC(2) model.
load Data_JDanish
Mdl = vecm(4,2,2);
Mdl.SeriesNames = DataTable.Properties.VariableNames;
Mdl = estimate(Mdl,DataTable.Series);Estimate the generalized IRF from the estimated VEC(2) model.
Response = irf(Mdl,Method="generalized",NumObs=50);Response is a 50-by-4-by-4 array representing the generalized IRF of Mdl.
Plot the generalized IRF of the bond rate when real income is shocked at time 0.
figure; plot(0:49,Response(:,2,3)) title("IRF of IB When Y Is Shocked") xlabel("Observation Time") ylabel("Response") grid on
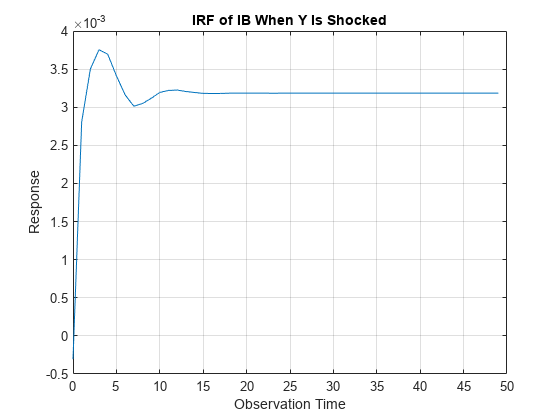
When real income is shocked, the bond rate reacts and then settles at approximately 0.0032 after 15 periods.
Since R2022b
Fit a 4-D VEC(2) model with two cointegrating relations to Danish money and income rate series data in a numeric matrix. Then, estimate and plot the orthogonalized IRF and corresponding confidence intervals from the estimated model.
Load the Danish money and income data set.
load Data_JDanishCreate a vecm model object that represents a 4-D VEC(2) model with two cointegrating relations. Specify the variable names.
Mdl = vecm(4,2,2); Mdl.SeriesNames = DataTable.Properties.VariableNames;
Mdl is a vecm model object specifying the structure of a 4-D VEC(2) model; it is a template for estimation.
Fit the VEC(2) model to the data set.
EstMdl = estimate(Mdl,DataTimeTable);
EstMdl is a fully specified vecm model object representing an estimated 4-D VEC(2) model.
Estimate the orthogonalized IRF and corresponding 95% confidence intervals from the estimated VEC(2) model. To return confidence intervals, you must set a name-value argument that controls confidence intervals, for example, Confidence. Set Confidence to 0.95.
rng(1); % For reproducibility
Tbl = irf(EstMdl,Confidence=0.95);
Tbl.Time(1)ans = datetime
01-Oct-1974
size(Tbl)
ans = 1×2
20 12
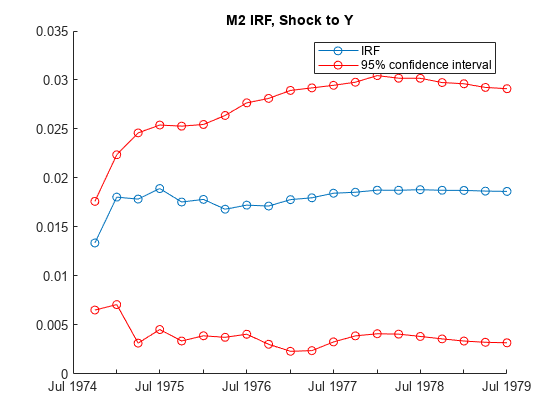
Tbl is a timetable with 20 rows, representing the periods in the IRF, and 12 variables. Each variable is a 20-by-4 matrix of the IRF or confidence bound of all variables resulting from shocking the variable. For example, Tbl.M2_IRF(:,2) is the IRF of Mdl.SeriesNames(2), which is the variable Y, resulting from a 1-standard-deviation shock on 01-Oct-1974 (period 0) to M2. [Tbl.M2_IRF_LowerBound(:,2),Tbl.M2_IRF_UpperBound(:,2)] are the corresponding 95% confidence intervals. By default, irf uses the H1 Johansen form, which is the same default form that estimate uses.
Plot the IRF of Y and its 95% confidence interval resulting from a 1-standard-deviation shock on 01-Oct-1974 (period 0) to M2.
idxM2 = startsWith(Tbl.Properties.VariableNames,"M2"); M2IRF = Tbl(:,idxM2); irfIdx = 2; figure hold on plot(M2IRF.Time,M2IRF.M2_IRF(:,irfIdx),"-o") plot(M2IRF.Time,[M2IRF.M2_IRF_LowerBound(:,irfIdx) ... M2IRF.M2_IRF_UpperBound(:,irfIdx)],"-o",Color="r") legend("IRF","95% confidence interval") title("Y IRF, Shock to M2") hold off
Consider the 4-D VEC(2) model with two cointegrating relations in Specify Data in Numeric Matrix When Plotting IRF. Estimate and plot its orthogonalized IRF and 95% Monte Carlo confidence intervals on the true IRF.
Load the Danish money and income data set, then estimate the VEC(2) model.
load Data_JDanish
Mdl = vecm(4,2,2);
Mdl.SeriesNames = DataTable.Properties.VariableNames;
Mdl = estimate(Mdl,DataTable.Series);Estimate the IRF and corresponding 95% Monte Carlo confidence intervals from the estimated VEC(2) model.
rng(1); % For reproducibility
[Response,Lower,Upper] = irf(Mdl);Response, Lower, and Upper are 20-by-4-by-4 arrays representing the orthogonalized IRF of Mdl and corresponding lower and upper bounds of the confidence intervals. For all arrays, rows correspond to consecutive time points from time 0 to 19, columns correspond to variables receiving a one-standard-deviation innovation shock at time 0, and pages correspond to responses of variables to the variable being shocked. Mdl.SeriesNames specifies the variable order.
Plot the orthogonalized IRF with its confidence bounds of the bond rate when real income is shocked at time 0.
irfshock2resp3 = Response(:,2,3); IRFCIShock2Resp3 = [Lower(:,2,3) Upper(:,2,3)]; figure; h1 = plot(0:19,irfshock2resp3); hold on h2 = plot(0:19,IRFCIShock2Resp3,"r--"); legend([h1 h2(1)],["IRF" "95% Confidence Interval"]) xlabel("Time Index"); ylabel("Response"); title("IRF of IB When Y Is Shocked"); grid on hold off
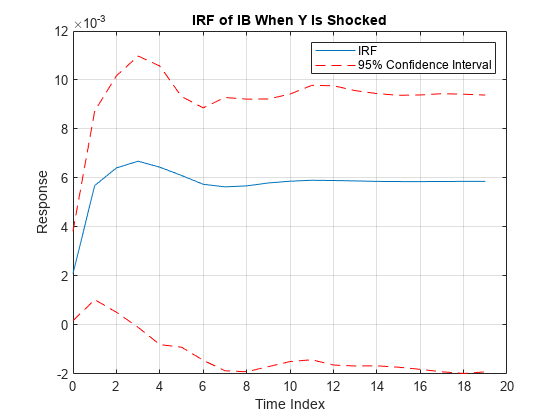
When real income is shocked, the bond rate reacts and then settles between –0.002 and 0.0095 with 95% confidence.
Consider the 4-D VEC(2) model with two cointegrating relations in Specify Data in Numeric Matrix When Plotting IRF. Estimate and plot its orthogonalized IRF and 90% bootstrap confidence intervals on the true IRF.
Load the Danish money and income data set, then estimate the VEC(2) model. Return the residuals from model estimation.
load Data_JDanish Mdl = vecm(4,2,2); Mdl.SeriesNames = DataTable.Properties.VariableNames; [Mdl,~,~,Res] = estimate(Mdl,DataTable.Series); T = size(DataTable,1) % Total sample size
T = 55
n = size(Res,1) % Effective sample sizen = 52
Res is a 52-by-4 array of residuals. Columns correspond to the variables in Mdl.SeriesNames. The estimate function requires Mdl.P = 3 observations to initialize a VEC(2) model for estimation. Because presample data (Y0) is unspecified, estimate takes the first three observations in the specified response data to initialize the model. Therefore, the resulting effective sample size is T – Mdl.P = 52, and rows of Res correspond to the observation indices 4 through T.
Estimate the orthogonalized IRF and corresponding 90% bootstrap confidence intervals from the estimated VEC(2) model. Draw 500 paths of length n from the series of residuals.
rng(1) % For reproducibility [Response,Lower,Upper] = irf(Mdl,E=Res,NumPaths=500, ... Confidence=0.9);
Plot the orthogonalized IRF with its confidence bounds of the bond rate when real income is shocked at time 0.
irfshock2resp3 = Response(:,2,3); IRFCIShock2Resp3 = [Lower(:,2,3) Upper(:,2,3)]; figure; h1 = plot(0:19,irfshock2resp3); hold on h2 = plot(0:19,IRFCIShock2Resp3,"r--"); legend([h1 h2(1)],["IRF" "90% Confidence Interval"]) xlabel("Time Index"); ylabel("Response"); title("IRF of IB When Y Is Shocked"); grid on hold off
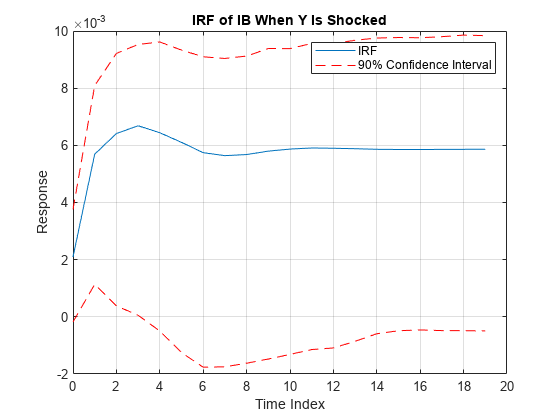
When real income is shocked, the bond rate reacts and then settles between approximately 0 and 0.010 with 90% confidence.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
If
Methodis"orthogonalized", then the resulting IRF depends on the order of the variables in the time series model. IfMethodis"generalized", then the resulting IRF is invariant to the order of the variables. Therefore, the two methods generally produce different results.If
Mdl.Covarianceis a diagonal matrix, then the resulting generalized and orthogonalized IRFs are identical. Otherwise, the resulting generalized and orthogonalized IRFs are identical only when the first variable shocks all variables (for example, all else being the same, both methods yield the same value ofResponse(:,1,:)).The predictor data in
XorInSamplerepresents a single path of exogenous multivariate time series. If you specifyXorInSampleand the modelMdlhas a regression component (Mdl.Betais not an empty array),irfapplies the same exogenous data to all paths used for confidence interval estimation.irfconducts a simulation to estimate the confidence boundsLowerandUpperor associated variables inTbl.If you do not specify residuals by supplying
Eor usingInSample,irfconducts a Monte Carlo simulation by following this procedure:Simulate
NumPathsresponse paths of lengthSampleSizefromMdl.Fit
NumPathsmodels that have the same structure asMdlto the simulated response paths. IfMdlcontains a regression component and you specify predictor data by supplyingXor usingInSample, thenirffits theNumPathsmodels to the simulated response paths and the same predictor data (the same predictor data applies to all paths).Estimate
NumPathsIRFs from theNumPathsestimated models.For each time point t = 0,…,
NumObs, estimate the confidence intervals by computing 1 –ConfidenceandConfidencequantiles (upper and lower bounds, respectively).
Otherwise,
irfconducts a nonparametric bootstrap by following this procedure:Resample, with replacement,
SampleSizeresiduals fromEorInSample. Perform this stepNumPathstimes to obtainNumPathspaths.Center each path of bootstrapped residuals.
Filter each path of centered, bootstrapped residuals through
Mdlto obtainNumPathsbootstrapped response paths of lengthSampleSize.Complete steps 2 through 4 of the Monte Carlo simulation, but replace the simulated response paths with the bootstrapped response paths.
References
[1] Hamilton, James D. Time Series Analysis. Princeton, NJ: Princeton University Press, 1994.
[2] Johansen, S. Likelihood-Based Inference in Cointegrated Vector Autoregressive Models. Oxford: Oxford University Press, 1995.
[3] Juselius, K. The Cointegrated VAR Model. Oxford: Oxford University Press, 2006.
[4] Pesaran, H. H., and Y. Shin. "Generalized Impulse Response Analysis in Linear Multivariate Models." Economic Letters. Vol. 58, 1998, pp. 17–29.