清除表中的杂乱数据和缺失数据
此示例说明如何清理和重新组织拥有杂乱和缺失数据值的表。首先,您可以使用导入工具或 summary 和 ismissing 等函数来标识缺失数据。接下来,您可以使用 standardizeMissing、fillmissing 或 rmmissing 函数或者实时编辑器中的清洗缺失数据任务来标准化、填充或删除缺失值。然后,您可以使用 sortrows 和 movevars 函数通过重新排列表行和变量来重新组织表。
检查文件中的数据
使用“导入工具”检查示例逗号分隔值 (CSV) 文件 messy.csv 中的数据。该工具支持预览数据,并且可用于指定数据导入方式。要在导入工具中检查 messy.csv,请在 MATLAB® 中打开此示例后,在主页选项卡的变量部分中,点击导入数据。然后,使用文件选择对话框打开 messy.csv。
导入工具显示 messy.csv 具有五个包含文本和数值的列。
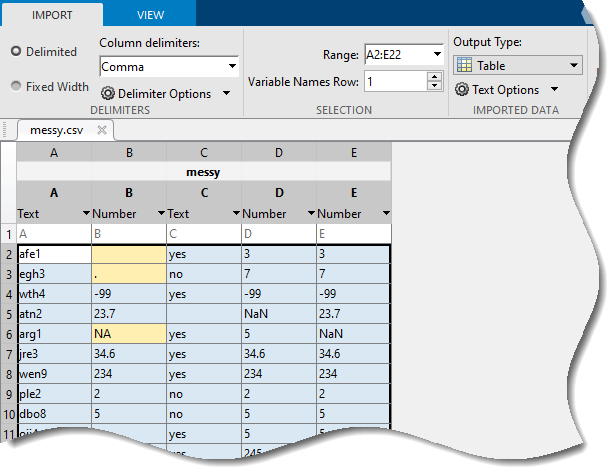
该文件包含许多不同的缺失数据指示符:
空文本
句点(.)
NANaN-99
导入工具会自动识别(但不在外观上突出显示)一些缺失数据指示符,例如数值列中的 NaN 和文本列中的空文本。
该工具会突出显示其他指示符,如出现在列 B 中的空文本、句点和 NA。这些值不是标准的缺失值。但是,数值列中的非数值可能表示缺失值。在导入选项卡的无法导入的单元格部分中,您可以添加规则以将这些值视为缺失值。
当数值数据由正值组成时,如出现单个负值(如 -99),它可能是缺失数据的标志。如果像 -99 这样的数字表示表中的缺失数据,则您在清洗表时必须指定它是缺失值。
以表的形式导入数据
您可以使用 readtable 函数从文件中读取数据,并以表的形式导入数据。
使用 readtable 函数导入 messy.csv 中的数据。要将文本数据读入字符串数组形式的表变量,请使用 TextType 名称-值参量。要将数值列中指定的非数值视为缺失值,请使用 TreatAsMissing 名称-值参量。对于包含文本数据的列 A 和 C,readtable 将任何空文本作为缺失字符串导入,这些字符串显示为 <missing>。对于包含数值数据的列 B、D 和 E,当您使用 TreatAsMissing 指定它们时,readtable 会将空文本作为 NaN 值导入,还会将 . 和 NA 作为 NaN 值导入。但值 -99 保持不变,因为它们是数值。
messyTable = readtable("messy.csv",TextType="string",TreatAsMissing=["." "NA"])
messyTable=21×5 table
A B C D E
______ ____ _________ ____ ____
"afe1" NaN "yes" 3 3
"egh3" NaN "no" 7 7
"wth4" -99 "yes" -99 -99
"atn2" 23.7 <missing> NaN 23.7
"arg1" NaN "yes" 5 NaN
"jre3" 34.6 "yes" 34.6 34.6
"wen9" 234 "yes" 234 234
"ple2" 2 "no" 2 2
"dbo8" 5 "no" 5 5
"oii4" 5 "yes" 5 5
"wnk3" 245 "yes" 245 245
"abk6" 563 "no" 563 563
"pnj5" 463 "no" 463 463
"wnn3" 6 "no" 6 6
"oks9" 23 "yes" 23 23
"wba3" 14 "yes" 14 14
⋮
查看表的摘要
要查看表的摘要,请使用 summary 函数。对于每个表变量,摘要显示每个表变量的数据类型和其他描述性统计量。例如,summary 显示 messyTable 的每个数值变量中缺失值的数目。
summary(messyTable)
messyTable: 21×5 table
Variables:
A: string
B: double
C: string
D: double
E: double
Statistics for applicable variables:
NumMissing Min Median Max Mean Std
A 0
B 3 -99 22.5000 563 90.1056 174.0532
C 1
D 2 -99 14 563 83.8000 171.0755
E 1 -99 21.5000 563 81.5950 166.7100
查找具有缺失值的行
要查找 messyTable 中至少有一个缺失值的行,请使用 ismissing 函数。如果您的数据中有非标准缺失值,例如 -99,您可以将其与标准缺失值一起指定。
ismissing 的输出是逻辑数组,用于标识 messyTable 中具有缺失值的元素。
missingElements = ismissing(messyTable,{string(missing),NaN,-99})missingElements = 21×5 logical array
0 1 0 0 0
0 1 0 0 0
0 1 0 1 1
0 0 1 1 0
0 1 0 0 1
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
⋮
要创建标识有缺失值的行的逻辑向量,请使用 any 函数。
rowsWithMissingValues = any(missingElements,2)
rowsWithMissingValues = 21×1 logical array
1
1
1
1
1
0
0
0
0
0
0
0
0
0
0
⋮
要对表进行索引并只返回有缺失值的行,请使用逻辑向量 rowsWithMissingValues。
missingValuesTable = messyTable(rowsWithMissingValues,:)
missingValuesTable=6×5 table
A B C D E
______ ____ _________ ___ ____
"afe1" NaN "yes" 3 3
"egh3" NaN "no" 7 7
"wth4" -99 "yes" -99 -99
"atn2" 23.7 <missing> NaN 23.7
"arg1" NaN "yes" 5 NaN
"gry5" 21 "yes" NaN 21
填充缺失值
清洗表中缺失值的一个策略是用更有意义的值替换它们。您可以通过插入标准缺失值来替换非标准缺失值。然后,您还可以用调整后的值来填充缺失值。例如,您可以用最近邻值或表变量的均值来填充缺失值。
在此示例中,-99 是非标准值,用于指示缺失值。要用标准缺失值替换 -99 的实例,请使用 standardizeMissing 函数。NaN 是单精度和双精度浮点数值数组的标准缺失值。
messyTable = standardizeMissing(messyTable,-99)
messyTable=21×5 table
A B C D E
______ ____ _________ ____ ____
"afe1" NaN "yes" 3 3
"egh3" NaN "no" 7 7
"wth4" NaN "yes" NaN NaN
"atn2" 23.7 <missing> NaN 23.7
"arg1" NaN "yes" 5 NaN
"jre3" 34.6 "yes" 34.6 34.6
"wen9" 234 "yes" 234 234
"ple2" 2 "no" 2 2
"dbo8" 5 "no" 5 5
"oii4" 5 "yes" 5 5
"wnk3" 245 "yes" 245 245
"abk6" 563 "no" 563 563
"pnj5" 463 "no" 463 463
"wnn3" 6 "no" 6 6
"oks9" 23 "yes" 23 23
"wba3" 14 "yes" 14 14
⋮
要填充缺失值,请使用 fillmissing 函数。该函数提供多个填充缺失值的方法。例如,用最近邻的非缺失值来填充缺失值。
filledTable = fillmissing(messyTable,"nearest")filledTable=21×5 table
A B C D E
______ ____ _____ ____ ____
"afe1" 23.7 "yes" 3 3
"egh3" 23.7 "no" 7 7
"wth4" 23.7 "yes" 7 23.7
"atn2" 23.7 "yes" 5 23.7
"arg1" 34.6 "yes" 5 34.6
"jre3" 34.6 "yes" 34.6 34.6
"wen9" 234 "yes" 234 234
"ple2" 2 "no" 2 2
"dbo8" 5 "no" 5 5
"oii4" 5 "yes" 5 5
"wnk3" 245 "yes" 245 245
"abk6" 563 "no" 563 563
"pnj5" 463 "no" 463 463
"wnn3" 6 "no" 6 6
"oks9" 23 "yes" 23 23
"wba3" 14 "yes" 14 14
⋮
删除具有缺失值的行
清洗表中缺失值的另一个策略是删除包含这些值的行。
要删除包含缺失值的行,请使用 rmmissing 函数。
remainingTable = rmmissing(messyTable)
remainingTable=15×5 table
A B C D E
______ ____ _____ ____ ____
"jre3" 34.6 "yes" 34.6 34.6
"wen9" 234 "yes" 234 234
"ple2" 2 "no" 2 2
"dbo8" 5 "no" 5 5
"oii4" 5 "yes" 5 5
"wnk3" 245 "yes" 245 245
"abk6" 563 "no" 563 563
"pnj5" 463 "no" 463 463
"wnn3" 6 "no" 6 6
"oks9" 23 "yes" 23 23
"wba3" 14 "yes" 14 14
"pkn4" 2 "no" 2 2
"adw3" 22 "no" 22 22
"poj2" 34.6 "yes" 34.6 34.6
"bas8" 23 "no" 23 23
排序和重新排列表行和变量
一旦清除了表中的缺失值,就可以用其他方式组织它。例如,您可以按照一个或多个变量中的值对表行进行排序。
按照第一个变量 A 中的值对行进行排序。
sortedTable = sortrows(remainingTable)
sortedTable=15×5 table
A B C D E
______ ____ _____ ____ ____
"abk6" 563 "no" 563 563
"adw3" 22 "no" 22 22
"bas8" 23 "no" 23 23
"dbo8" 5 "no" 5 5
"jre3" 34.6 "yes" 34.6 34.6
"oii4" 5 "yes" 5 5
"oks9" 23 "yes" 23 23
"pkn4" 2 "no" 2 2
"ple2" 2 "no" 2 2
"pnj5" 463 "no" 463 463
"poj2" 34.6 "yes" 34.6 34.6
"wba3" 14 "yes" 14 14
"wen9" 234 "yes" 234 234
"wnk3" 245 "yes" 245 245
"wnn3" 6 "no" 6 6
按照 C 以降序对行进行排序,然后按照 A 以升序排序。
sortedBy2Vars = sortrows(remainingTable,["C" "A"],["descend" "ascend"])
sortedBy2Vars=15×5 table
A B C D E
______ ____ _____ ____ ____
"jre3" 34.6 "yes" 34.6 34.6
"oii4" 5 "yes" 5 5
"oks9" 23 "yes" 23 23
"poj2" 34.6 "yes" 34.6 34.6
"wba3" 14 "yes" 14 14
"wen9" 234 "yes" 234 234
"wnk3" 245 "yes" 245 245
"abk6" 563 "no" 563 563
"adw3" 22 "no" 22 22
"bas8" 23 "no" 23 23
"dbo8" 5 "no" 5 5
"pkn4" 2 "no" 2 2
"ple2" 2 "no" 2 2
"pnj5" 463 "no" 463 463
"wnn3" 6 "no" 6 6
按 C 排序。此时,各行先按 "yes" 分组,然后再按 "no" 分组。然后,按 A 排序。此时,各行按字母顺序列出。
要对表进行重新排序,使 A 和 C 彼此相邻,请使用 movevars。
sortedRowsAndMovedVars = movevars(sortedBy2Vars,"C",After="A")
sortedRowsAndMovedVars=15×5 table
A C B D E
______ _____ ____ ____ ____
"jre3" "yes" 34.6 34.6 34.6
"oii4" "yes" 5 5 5
"oks9" "yes" 23 23 23
"poj2" "yes" 34.6 34.6 34.6
"wba3" "yes" 14 14 14
"wen9" "yes" 234 234 234
"wnk3" "yes" 245 245 245
"abk6" "no" 563 563 563
"adw3" "no" 22 22 22
"bas8" "no" 23 23 23
"dbo8" "no" 5 5 5
"pkn4" "no" 2 2 2
"ple2" "no" 2 2 2
"pnj5" "no" 463 463 463
"wnn3" "no" 6 6 6
还可以通过索引对表变量进行重新排序。使用圆括号和变量索引来指定输出表中变量的顺序。
sortedRowsAndMovedVars = sortedBy2Vars(:,["A" "C" "B" "D" "E"])
sortedRowsAndMovedVars=15×5 table
A C B D E
______ _____ ____ ____ ____
"jre3" "yes" 34.6 34.6 34.6
"oii4" "yes" 5 5 5
"oks9" "yes" 23 23 23
"poj2" "yes" 34.6 34.6 34.6
"wba3" "yes" 14 14 14
"wen9" "yes" 234 234 234
"wnk3" "yes" 245 245 245
"abk6" "no" 563 563 563
"adw3" "no" 22 22 22
"bas8" "no" 23 23 23
"dbo8" "no" 5 5 5
"pkn4" "no" 2 2 2
"ple2" "no" 2 2 2
"pnj5" "no" 463 463 463
"wnn3" "no" 6 6 6
另请参阅
table | ismissing | standardizeMissing | fillmissing | rmmissing | sortrows | movevars | Import Tool | readtable | summary