fillmissing
填充缺失条目
语法
说明
F = fillmissing(A,method)method 指定的方法填充缺失的条目。例如,对于 A 的每列中的缺失条目,fillmissing(A,"previous") 用其前一个非缺失条目进行填充。
缺失值的定义取决于 A 的数据类型:
NaN-double、single、duration和calendarDurationNaT—datetime<missing>—string<undefined>—categorical{''}- 字符向量的cell
如果 A 是表,则每个变量的数据类型定义该变量的缺失值。
您可以通过将清洗缺失数据任务添加到实时脚本中,以交互方式使用 fillmissing 功能。
F = fillmissing(___,Name=Value)t 是时间值向量,则 fillmissing(A,"linear",SamplePoints=t) 会基于 t 中的时间值对 A 中的数据进行插值。
示例
创建包含 NaN 值的向量,并使用前一个非缺失值替换每个 NaN。
A = [1 3 NaN 4 NaN NaN 5];
F = fillmissing(A,"previous")F = 1×7
1 3 3 4 4 4 5
创建一个 2×2 矩阵,每列有一个 NaN 值。在第一列中用 100 填充 NaN,在第二列中用 1000 填充。
A = [1 NaN; NaN 2];
F = fillmissing(A,"constant",[100 1000])F = 2×2
1 1000
100 2
使用插值来替换非均匀采样的数据中的 NaN 值。
定义非均匀采样点向量,并计算这些点上的正弦函数。
x = [-4*pi:0.1:0, 0.1:0.2:4*pi]; A = sin(x);
将 NaN 值插入 A 中。
A(A < 0.75 & A > 0.5) = NaN;
使用线性插值填充缺失数据,并返回填充的向量 F 和逻辑向量 TF。TF 项中的值 1 (true) 对应于 F 中的填充值。
[F,TF] = fillmissing(A,"linear",SamplePoints=x);绘制原始数据和填充的数据。
scatter(x,A) hold on scatter(x(TF),F(TF)) legend("Original Data","Filled Data")
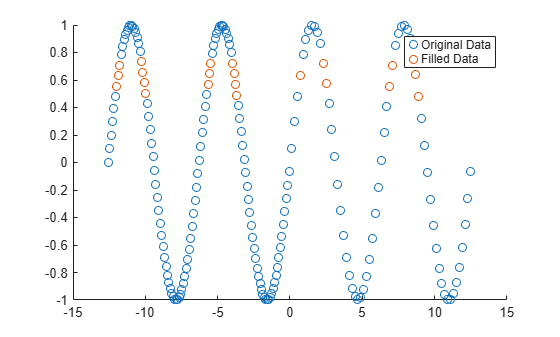
使用移动中位数填充缺失的数值数据。
创建样本点向量 x 和包含缺失值的数据向量 A。
x = linspace(0,10,200); A = sin(x) + 0.5*(rand(size(x))-0.5); A([1:10 randi([1 length(x)],1,50)]) = NaN;
使用窗长度为 10 的移动中位数替换 A 中的 NaN 值,并绘制原始数据和填充的数据。
F = fillmissing(A,"movmedian",10); plot(x,F,".-") hold on plot(x,A,".-") legend("Original Data","Filled Data")
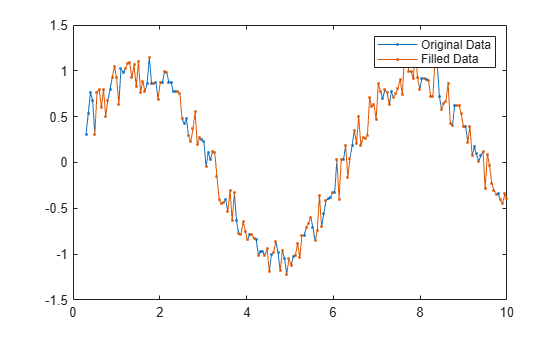
定义一个自定义函数,用上一个非缺失值填充 NaN 值。
定义采样点向量 t 和包含 NaN 值的对应数据向量 A。绘制数据图。
t = 10:10:100; A = [0.1 0.2 0.3 NaN NaN 0.6 0.7 NaN 0.9 1]; scatter(t,A)
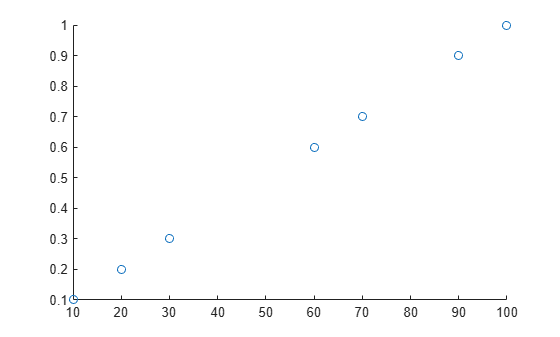
使用局部函数 forwardfill 用前一个非缺失值填充缺失空缺。函数句柄输入包括:
xs- 用于填充的数据值ts- 用于填充的值相对于采样点的位置tq- 缺失值相对于采样点的位置n- 要填充的空缺中的值的数目
function y = forwardfill(xs,ts,tq,n) y = NaN(1,numel(tq)); y(1:min(numel(tq),n)) = xs; end n = 2; gapwindow = [10 0]; [F,TF] = fillmissing(A,@(xs,ts,tq) forwardfill(xs,ts,tq,n),gapwindow,SamplePoints=t);
空缺窗值 [10 0] 指示 fillmissing 考虑缺失值空缺之前的一个数据点,不考虑空缺之后的任何数据点,因为上一个非缺失值位于空缺之前 10 个单位。对于第一个空缺,由 fillmissing 确定的函数句柄输入值为:
xs = 0.3ts = 30tq = [40 50]
第二个空缺的函数句柄输入值为:
xs = 0.7ts = 70tq = 80
绘制原始数据和填充的数据。
scatter(t,A)
hold on
scatter(t(TF),F(TF))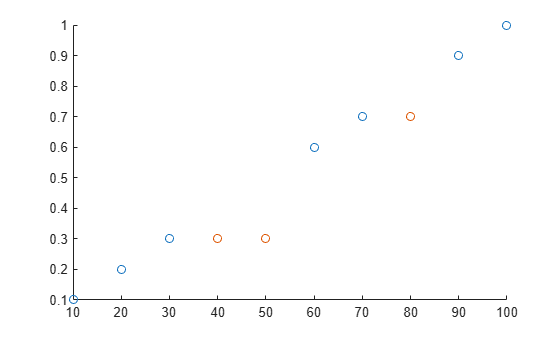
创建包含缺失条目的矩阵并使用线性插值填充各列(第二个维度),一次一行。对于每行,使用该行中距离最近的非缺失值填充前导和尾随缺失值。
A = [NaN NaN 5 3 NaN 5 7 NaN 9 NaN;
8 9 NaN 1 4 5 NaN 5 NaN 5;
NaN 4 9 8 7 2 4 1 1 NaN]A = 3×10
NaN NaN 5 3 NaN 5 7 NaN 9 NaN
8 9 NaN 1 4 5 NaN 5 NaN 5
NaN 4 9 8 7 2 4 1 1 NaN
F = fillmissing(A,"linear",2,EndValues="nearest")
F = 3×10
5 5 5 3 4 5 7 8 9 9
8 9 5 1 4 5 5 5 5 5
4 4 9 8 7 2 4 1 1 1
使用不同数据类型填充表变量的缺失值。
创建表,其变量包括 categorical、double 和 string 数据类型。
A = table(categorical(["Sunny"; "Cloudy"; " "]),[66; NaN; 54],[" "; "N"; "Y"],[37; 39; NaN],... VariableNames=["Description" "Temperature" "Rain" "Humidity"])
A=3×4 table
Description Temperature Rain Humidity
___________ ___________ ____ ________
Sunny 66 " " 37
Cloudy NaN "N" 39
<undefined> 54 "Y" NaN
用上一个条目的值替换所有缺失的条目。由于 Rain 变量中不存在前一个元素,缺失的字符向量将不会被替换。
F = fillmissing(A,"previous")F=3×4 table
Description Temperature Rain Humidity
___________ ___________ ____ ________
Sunny 66 " " 37
Cloudy 66 "N" 39
Cloudy 54 "Y" 39
将 A 中 Temperature 和 Humidity 变量的 NaN 值替换为 0。
F = fillmissing(A,"constant",0,DataVariables=["Temperature" "Humidity"])
F=3×4 table
Description Temperature Rain Humidity
___________ ___________ ____ ________
Sunny 66 " " 37
Cloudy 0 "N" 39
<undefined> 54 "Y" 0
或者,使用 isnumeric 函数识别要对其执行运算的数字变量。
F = fillmissing(A,"constant",0,DataVariables=@isnumeric)F=3×4 table
Description Temperature Rain Humidity
___________ ___________ ____ ________
Sunny 66 " " 37
Cloudy 0 "N" 39
<undefined> 54 "Y" 0
现在,用包含在元胞数组中的指定常量来填充 A 中每个表变量的缺失值。
F = fillmissing(A,"constant",{categorical("None"),1000,"Unknown",1000})
F=3×4 table
Description Temperature Rain Humidity
___________ ___________ ____ ________
Sunny 66 " " 37
Cloudy 1000 "N" 39
None 54 "Y" 1000
创建以秒为单位的时间向量 t 和对应的包含 NaN 值的数据向量 A。
t = seconds([2 4 8 17 98 134 256 311 1001]); A = [1 3 23 NaN NaN NaN 100 NaN 233];
仅填充 A 中与最大为 250 秒的空缺大小对应的缺失值。由于第二个空缺大于 250 秒,因此不会填充 NaN 值。
F = fillmissing(A,"linear",SamplePoints=t,MaxGap=seconds(250))F = 1×9
1.0000 3.0000 23.0000 25.7944 50.9435 62.1210 100.0000 NaN 233.0000
使用自定义距离函数用最近邻行中的值来填充缺失条目。
创建一个包含 NaN 值的矩阵,然后创建一个逻辑向量来指示第三行中缺失条目的位置。
A = [1 3 9 3; -5 1 7 2; -1 1 7 NaN; 12 1 9 1]; m = isnan(A(3,:));
定义两个自定义函数来测量行之间的距离。
函数 d1 通过合计每个坐标对组之间的距离来测量行之间的距离;函数 dinf 通过查找坐标对组中的最大距离来测量行之间的距离。
d1 = @(x,~) sum(abs(diff(x)),'omitnan'); dinf = @(x,isNaN) norm(diff(x(:,~isNaN(1,:))),'inf');
计算第三行和其他三行中每行之间的 d1 测量距离。第二行距离最近。
d1s = arrayfun(@(r) d1(A([r 3],:),m), setdiff(1:4,3))
d1s = 1×3
6 4 15
fillmissing 函数将第三行中的 NaN 替换为第二行中对应的 2。
F1 = fillmissing(A,'knn','Distance',d1)
F1 = 4×4
1 3 9 3
-5 1 7 2
-1 1 7 2
12 1 9 1
使用 dinf 测量距离的类似分析发现第一行与第三行距离最近。现在 fillmissing 函数将第三行中的 NaN 替换为第一行中对应的 3。
dinfs = arrayfun(@(r) dinf(A([r 3],:),m), setdiff(1:4,3))
dinfs = 1×3
2 4 13
Finf = fillmissing(A,'knn','Distance',dinf)
Finf = 4×4
1 3 9 3
-5 1 7 2
-1 1 7 3
12 1 9 1
自 R2024a 起
创建一个表并填充定义为 -99 的缺失条目。创建一个逻辑变量表 loc,该表指示要填充的缺失条目的位置。然后,使用 MissingLocations 名称-值参量指定 fillmissing 的已知缺失条目位置。
A = [1; 4; 9; -99; 3]; B = [9; 0; 6; 2; 1]; C = [-99; 4; 2; 3; 8]; T = table(A,B,C)
T=5×3 table
A B C
___ _ ___
1 9 -99
4 0 4
9 6 2
-99 2 3
3 1 8
loc = T==-99
loc=5×3 table
A B C
_____ _____ _____
false false true
false false false
false false false
true false false
false false false
T = fillmissing(T,"next",MissingLocations=loc)T=5×3 table
A B C
_ _ _
1 9 4
4 0 4
9 6 2
3 2 3
3 1 8
输入参数
输入数据,指定为向量、矩阵、多维数组、字符向量元胞数组、表或时间表。
如果
A为时间表,则仅填充表值。如果关联的行时间向量包含NaT或NaN值,则fillmissing会产生错误。行时间必须是唯一的并按升序列出。如果
A是元胞数组或包含元胞数组变量的表,则fillmissing仅在元胞数组包含字符向量时填充缺失元素。
数据类型: single | double | char | string | table | timetable | cell | categorical | datetime | duration | calendarDuration
填充常量,指定为与 A 类型相同的标量、向量或元胞数组。
如果
A是矩阵或多维数组,则v可以是向量,表示每个运算维度的一个不同填充值。v的长度必须与运算维度的长度相匹配。如果
A是表或时间表,则v可以是填充值的元胞数组,表示每个变量的一个不同填充值。元胞数组中的元素数必须与表中的变量数目相匹配。
填充方法,指定为下表中的值之一。
| 方法 | 描述 |
|---|---|
"previous" | 上一个非缺失值 |
"next" | 下一个非缺失值 |
"nearest" | 由 x 轴定义的最接近的非缺失值 |
"linear" | 基于相邻的非缺失值进行线性插值 |
"spline" | 分段三次样条插值 |
"pchip" | 保形分段三次样条插值 |
"makima" | 修正 Akima 三次埃尔米特插值 |
| 非缺失值的均值 |
| 非缺失值的中位数 |
| 非缺失值的众数 |
填充方法沿运算维度计算每个填充值。
某些输入类型仅支持这些填充方法中的部分方法。
填充缺失数据的移窗方法,指定为下列值之一:
| 方法 | 描述 |
|---|---|
"movmean" | 长度为 window 的窗的移动平均值 |
"movmedian" | 长度为 window 的窗的移动中位数 |
移窗法的窗长度,指定为正整数标量、由非负整数组成的二元素向量、正持续时间标量或由正持续时间组成的二元素向量。窗是相对于采样点定义的。
如果 window 是正整数标量,则窗以当前元素为中心并且包含 window-1 个相邻元素。如果 window 是偶数,则窗口以当前元素和上一个元素为中心。
如果 window 是由正整数组成的二元素向量 [b f],则窗口包含当前元素、其之前的 b 个元素和之后的 f 个元素。
如果 A 是时间表或 SamplePoints 指定为 datetime 或 duration 向量,则窗口必须为 duration 类型。
有关窗位置的详细信息,请参阅移动窗大小。
用 "knn" 方法计算平均值的最近邻的数量,指定为正整数标量。
示例: @(xs,ts,tq) myfun(xs,ts,tq)
自定义填充方法,指定为具有以下三个输入参量的函数句柄:
| 输入参量 | 描述 |
|---|---|
xs | 与 A 类型相同的向量,包含用于填充的数据值。xs 的长度必须与指定窗的长度匹配。 |
ts | 包含用于填充的值的位置的向量。ts 的长度必须与指定窗的长度匹配。ts 是采样点向量的子集。 |
tq | 包含缺失值位置的向量。tq 是采样点向量的子集。 |
该函数必须返回标量或与 tq 长度相同、与 A 类型相同的向量。
自定义填充函数的空缺窗长度,指定为正整数标量、由正整数组成的二元素向量、正持续时间标量或由正持续时间组成的二元素向量。空缺窗是相对于采样点定义的。
为填充方法指定函数句柄 fillfun 时,gapwindow 的值表示围绕输入数据中缺失值的每个空缺的固定窗长度。然后由 fillfun 使用该窗中的值计算填充值。例如,对于默认采样点 t = 1:10 和数据 A = [10 20 NaN NaN 50 60 70 NaN 90 100],窗口长度 gapwindow = 3 将第一个空缺窗指定为 [20 NaN NaN 50],fillfun 对其进行运算以计算填充值。fillfun 进行运算的第二个空缺窗是 [70 NaN 90]。
当 A 是时间表或 SamplePoints 指定为 datetime 或 duration 向量时,gapwindow 必须为 duration 类型。
沿其运算的数组维度,指定为正整数标量。如果未指定值,则默认值是大小不等于 1 的第一个数组维度。
以一个 m×n 输入矩阵 A 为例:
fillmissing(A,method,1)根据A的每列中的数据填充缺失值,并返回一个m×n矩阵。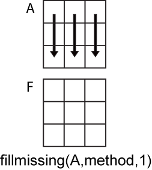
fillmissing(A,method,2)根据A的每行中的数据填充缺失值,并返回一个m×n矩阵。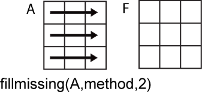
对于表或时间表输入数据,不支持 dim,并且分别对每个表或时间表变量进行运算。
名称-值参数
输出参量
详细信息
下表说明默认等间距样本点向量 [1 2 3 4 5 6 7] 上的窗位置。
描述 | 窗大小和位置 | 窗中的采样点 | 图 |
|---|---|---|---|
对于标量窗大小,不包括窗的左边界,但包括窗的右边界。 |
当前采样点 = 4 | 3、4、5 |
|
当前采样点 = 4 | 2、3、4、5 |
| |
对于向量窗大小,包括窗的左边界和右边界。 |
当前采样点 = 4 | 2、3、4、5、6 |
|
对于输入数据端点附近的采样点, |
当前采样点 = 2 | 1、2、3、4 |
|


![Given elements 1 to 7, if the current sample point is 4, then the corresponding window spans the range [2, 6].](movwindow_vector.png)
![Given elements 1 to 7, if the current sample point is 2, then the corresponding window spans the range [1, 4].](movwindow_edgetruncate.png)
提示
对于非字符向量的结构体数组或元胞数组的输入数据,
fillmissing不填充任何条目。要填充结构体数组中缺失的条目,请使用structfun函数将fillmissing应用于结构体中的每个字段。要填充非字符向量元胞数组中缺失的条目,请使用cellfun函数将fillmissing应用于元胞数组中的每个元胞。
替代功能
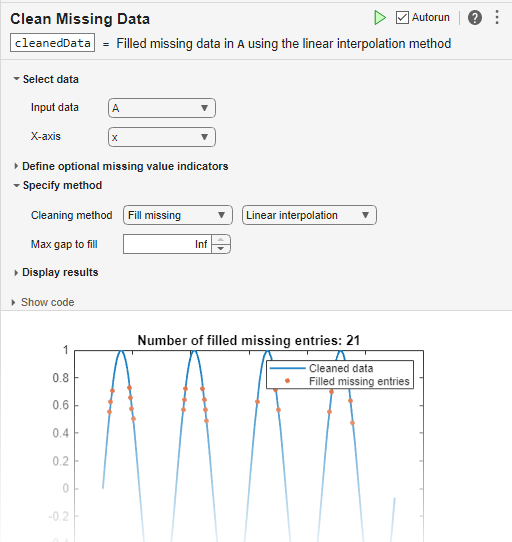
扩展功能
版本历史记录
在 R2016b 中推出另请参阅
函数
fillmissing2|ismissing|standardizeMissing|anymissing|rmmissing|filloutliers|isnan|missing|isnat|smoothdata