正则表达式
本主题说明什么是正则表达式以及如何使用它们来搜索文本。正则表达式灵活而强大,尽管它们使用复杂的语法。正则表达式的一种替代选择是pattern(自 R2020b 开始提供),它更易于定义,并且生成的代码更易于阅读。有关详细信息,请参阅构建模式表达式。
什么是正则表达式?
正则表达式是一串用于定义某种模式的字符。在有些情况下(例如,在解析程序输入或处理文本块时),您通常会使用正则表达式在文本中搜索与该模式匹配的一组单词。
字符向量 'Joh?n\w*' 是一个正则表达式的示例。该字符串定义的模式以字母 Jo 开头,后面可跟,也可不跟字母 h(由 'h?' 指示),然后跟有字母 n,最后以任意数量的单词字符结尾(由 '\w*' 指示),此处的单词字符指字母、数字或下划字符。该模式与以下任意条目匹配:
Jon, John, Jonathan, Johnny
正则表达式提供了一种在大量文本中搜索特定字符子集的独特方式。正则表达式使您能够查找特定模式的字符,而不必像使用 strfind 等函数那样查找字符的完全匹配项。
例如,有多种表示公制速率的方式:
km/h km/hr km/hour kilometers/hour kilometers per hour
您可以通过发出五个单独的搜索命令在文本中查找以上任意词汇:
strfind(text, 'km/h'); strfind(text, 'km/hour'); % etc.
当然,为了提高效率,您也可以构建一个适用于所有这些搜索词汇的短语:
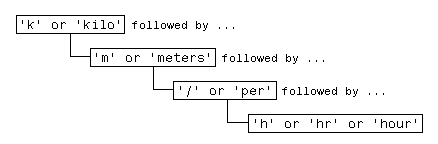
将此短语转换为正则表达式(本部分后面将会介绍),您将具有如下表达式:
pattern = 'k(ilo)?m(eters)?(/|\sper\s)h(r|our)?';
现在仅使用一个命令来查找一个或多个词汇:
text = ['The high-speed train traveled at 250 ', ... 'kilometers per hour alongside the automobile ', ... 'travelling at 120 km/h.']; regexp(text, pattern, 'match')
ans =
1×2 cell array
{'kilometers per hour'} {'km/h'}
有四个 MATLAB® 函数支持使用正则表达式搜索和替换字符。前三个函数在接受的输入值和返回的输出值方面类似。有关详细信息,请点击函数参考页的链接。
| 函数 | 描述 |
|---|---|
regexp | 匹配正则表达式。 |
regexpi | 匹配正则表达式并忽略大小写。 |
regexprep | 使用正则表达式替换部分文本。 |
regexptranslate | 将文本转换为正则表达式。 |
调用前三个函数中的任何一个函数时,请在前两个输入参量中传递要解析的文本以及正则表达式。调用 regexprep 时,还需再传递一个额外的输入,该输入是一个表达式,用于指定替代的模式。
构建表达式的步骤
使用正则表达式在文本中搜索特定词涉及以下三个步骤:
此部分中显示的示例搜索包含群组中五个朋友的联系信息的记录。该信息包括每个人的姓名、电话号码、居住地和电子邮件地址。目标是从文本中提取特定信息。
contacts = { ...
'Harry 287-625-7315 Columbus, OH hparker@hmail.com'; ...
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'; ...
'Mike 793-136-0975 Richmond, VA sue_and_mike@hmail.net'; ...
'Nadine 648-427-9947 Tampa, FL nadine_berry@horizon.net'; ...
'Jason 697-336-7728 Montrose, CO jason_blake@mymail.com'};
此示例的第一部分构建一个表示标准电子邮件地址的格式的正则表达式。通过该表达式,此示例就可以在信息中搜索群组中一个朋友的电子邮件地址。Janice 的联系信息位于 contacts 元胞数组的第 2 行:
contacts{2}
ans =
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'
步骤 1 - 确定文本中的独特模式
典型的电子邮件地址包含以下标准部分:用户的帐户名称(后跟 @ 符号)、用户的 Internet 服务提供商 (ISP) 的名称、点(句点)以及该 ISP 所属的域。下表在左列中列出了这些部分,在右列中概述了每部分的格式。
| 电子邮件地址的独特模式 | 每种模式的一般说明 |
|---|---|
以帐户名称开头jan_stephens . . . | 一个或多个小写字母和下划线 |
添加 '@'jan_stephens@ . . . | @ 符号 |
添加 ISP jan_stephens@horizon . . . | 一个或多个小写字母,无下划线 |
添加点(句点)jan_stephens@horizon. . . . | 点(句点)字符 |
以域结尾jan_stephens@horizon.net | com 或 net |
步骤 2 - 将每种模式表示为正则表达式
在此步骤中,您将步骤 1 中得到的一般格式转换为正则表达式的段。然后,将这些段添加到一起以构成整个表达式。
下表在最左侧的列中显示了每种字符模式的广义格式说明。(这是从步骤 1 的表的右列中继承过来的。)第二列显示表示字符模式的运算符或元字符。
| 每个段的说明 | 模式 |
|---|---|
| 一个或多个小写字母和下划线 | [a-z_]+ |
@ 符号 | @ |
| 一个或多个小写字母,无下划线 | [a-z]+ |
| 点(句点)字符 | \. |
com 或 net | (com|net) |
将这些模式组合成一个字符向量可得到完整的表达式:
email = '[a-z_]+@[a-z]+\.(com|net)';
步骤 3 - 调用合适的搜索函数
在此步骤中,您使用步骤 2 中得到的正则表达式来匹配群组中其中一个朋友的电子邮件地址。使用 regexp 函数执行搜索。
下面列出了此部分先前显示的联系信息。每个人的记录占用 contacts 元胞数组的一行:
contacts = { ...
'Harry 287-625-7315 Columbus, OH hparker@hmail.com'; ...
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'; ...
'Mike 793-136-0975 Richmond, VA sue_and_mike@hmail.net'; ...
'Nadine 648-427-9947 Tampa, FL nadine_berry@horizon.net'; ...
'Jason 697-336-7728 Montrose, CO jason_blake@mymail.com'};
以下是步骤 2 中得到的表示电子邮件地址的正则表达式:
email = '[a-z_]+@[a-z]+\.(com|net)';
调用 regexp 函数,并传递 contacts 元胞数组的第 2 行以及 email 正则表达式。这将返回 Janice 的电子邮件地址。
regexp(contacts{2}, email, 'match')
ans =
1×1 cell array
{'jan_stephens@horizon.net'}
MATLAB 从左至右解析字符向量,并随着解析的进行“消减”该向量。如果找到匹配的字符,regexp 将会记录相应位置并继续解析字符向量(仅从最新匹配项结尾之后开始)。
执行相同调用,但这次是针对列表中的第五个人进行调用:
regexp(contacts{5}, email, 'match')
ans =
1×1 cell array
{'jason_blake@mymail.com'}
您也可以使用整个元胞数组作为输入参量,以搜索列表中每个人的电子邮件地址:
regexp(contacts, email, 'match');
运算符和字符
正则表达式可包含用于指定要匹配的模式的字符、元字符、运算符、词元和标志,如下面各部分所述:
元字符
元字符表示字母、字母范围、数字和空格字符。使用它们来构造广义的字符模式。
元字符 | 描述 | 示例 |
|---|---|---|
| 任何单个字符,包括空白 |
|
| 包含在方括号中的任意字符。下列字符将按字面意义进行处理: |
|
| 未包含在方括号中的任意字符。下列字符将按字面意义进行处理: |
|
|
|
|
| 任意字母、数字或下划线字符。对于英语字符集, |
|
| 字母、数字或下划线之外的任意字符。对于英语字符集, |
|
| 任意空白字符;等同于 |
|
| 任意非空白字符;等同于 |
|
| 任意数字;等同于 |
|
| 任意非数字字符;等同于 |
|
| 八进制值 |
|
| 十六进制值 |
|
字符表示
运算符 | 描述 |
|---|---|
| 警报(蜂鸣) |
| 退格符 |
| 换页符 |
| 换行符 |
| 回车符 |
| 水平制表符 |
| 垂直制表符 |
| 正则表达式中您要从字面上匹配(例如,使用 |
限定符
限定符指定某个模式必须出现在匹配文本中的次数。
限定符 | 表达式出现的次数 | 示例 |
|---|---|---|
| 0 次或连续多次。 |
|
| 0 次或 1 次。 |
|
| 1 次或连续多次。 |
|
| 至少
|
|
| 至少连续
|
|
| 恰好连续 等效于 |
|
限定符可以以三种模式显示,如下表所述。q 表示上表中的任意限定符。
模式 | 描述 | 示例 |
|---|---|---|
| 积极表达式:与尽可能多的字符匹配。 | 给定文本 |
| 消极表达式:与所需的尽可能少的字符匹配。 | 给定文本 |
| 主动表达式:最大程度地匹配,但不重新扫描文本的任何部分。 | 给定文本 |
分组运算符
分组运算符允许您捕获词元,将一个运算符应用于多个元素或在特定组中禁止追溯。
分组运算符 | 描述 | 示例 |
|---|---|---|
| 将表达式元素分组并捕获词元。 |
|
| 分组但不捕获词元。 |
不进行分组时, |
| 以原子方式分组。不在组中追溯以完成匹配,并且不捕获词元。 |
|
| 匹配表达式 如果存在与 您可以在左括号后包括 |
|
定位点
表达式中的定位点与字符向量或单词的开头或结尾匹配。
定位点 | 与以下项匹配 | 示例 |
|---|---|---|
| 输入文本的开头。 |
|
| 输入文本的结尾。 |
|
| 单词开头。 |
|
| 单词结尾。 |
|
环顾断言
环顾断言查找紧邻预期匹配项前后但并非该匹配项一部分的模式。
指针停留在当前位置,并且将放弃或不捕获对应于 test 表达式的字符。因此,前向断言可匹配重叠字符组。
环顾断言 | 描述 | 示例 |
|---|---|---|
| 向前查找与 |
|
| 向前查找与 |
|
| 向后查找与 |
|
| 向后查找与 |
|
如果您在表达式之前指定前向断言,则运算等同于逻辑 AND。
运算 | 描述 | 示例 |
|---|---|---|
| 同时与 |
|
| 匹配 |
|
有关详细信息,请参阅正则表达式中的前向断言。
逻辑和条件运算符
逻辑和条件运算符允许您测试给定条件的状态,然后使用结果确定哪个模式(如果有)与下一条件匹配。这些运算符支持逻辑 OR、if 或 if/else 条件。(对于 AND 条件,请参阅环顾断言。)
条件可以是词元、环顾断言或 (?@cmd) 形式的动态表达式。动态表达式必须返回逻辑值或数值。
条件运算符 | 描述 | 示例 |
|---|---|---|
| 匹配表达式 如果存在与 |
|
| 如果条件 |
|
| 如果条件 |
|
词元运算符
词元是您通过将正则表达式的部分括在括号中而定义的匹配文本的部分。您可以按词元在文本中的顺序引用该词元(顺序词元),或将名称分配给词元以便于代码维护和使输出更易于阅读。
顺序词元运算符 | 描述 | 示例 |
|---|---|---|
| 在词元中捕获与括起来的表达式匹配的字符。 |
|
| 匹配第 |
|
| 如果找到第 |
|
命名词元运算符 | 描述 | 示例 |
|---|---|---|
| 在命名词元中捕获与括起来的表达式匹配的字符。 |
|
| 匹配 |
|
| 如果找到命名词元,则匹配 |
|
注意
如果表达式具有嵌套括号,则 MATLAB 捕获对应于最外层括号的词元。例如,给定搜索模式 '(and(y|rew))',MATLAB 将为 'andrew' 但不为 'y' 或 'rew' 创建一个词元。
有关详细信息,请参阅正则表达式中的词元。
动态表达式
动态表达式允许您执行 MATLAB 命令或正则表达式以确定要匹配的文本。
将动态表达式括起来的括号不创建捕获组。
运算符 | 描述 | 示例 |
|---|---|---|
| 解析 解析后, |
|
| 执行 |
|
| 执行 |
|
在动态表达式中,使用下列运算符定义替代项。
替代运算符 | 描述 |
|---|---|
| 当前作为匹配项的输入文本部分 |
| 位于当前匹配项之前的输入文本部分 |
| 紧随当前匹配项的输入文本部分(使用 |
| 第 |
| 命名词元 |
| 在 MATLAB 执行命令 |
有关详细信息,请参阅动态正则表达式。
注释
通过 comment 运算符,可以在代码中插入注释,以使代码更易于维护。根据输入文本进行匹配时,MATLAB 会忽略注释的文本。
字符 | 描述 | 示例 |
|---|---|---|
(?#comment) | 在正则表达式中插入注释。匹配输入时将忽略注释文本。 |
|
搜索标志
搜索标志修改匹配表达式的行为。
标志 | 描述 |
|---|---|
(?-i) | 匹配字母大小写( |
(?i) | 不匹配字母大小写( |
(?s) | 将模式中的点 ( |
(?-s) | 将模式中的点与并非换行符的任意字符匹配。 |
(?-m) | 匹配文本开头和结尾的 |
(?m) | 匹配行开头和结尾的 |
(?-x) | 在匹配时包括空格字符和注释(默认值)。 |
(?x) | 在匹配时忽略空格字符和注释。使用 |
该标志修改的表达式可显示在括号后,例如
(?i)\w*
或显示在括号内并使用冒号 (:) 与该标志分隔开,例如
(?i:\w*)
后面的语法允许您更改较大表达式的一部分的行为。
另请参阅
regexp | regexpi | regexprep | regexptranslate | pattern