partition
划分数据存储
语法
说明
示例
为大型文件集合创建数据存储。对于此示例,请使用示例文件 airlinesmall.csv 的十个副本。要处理表格数据中的缺失字段,请指定名称-值对组 TreatAsMissing 和 MissingValue。
files = repmat({'airlinesmall.csv'},1,10);
ds = tabularTextDatastore(files,...
'TreatAsMissing','NA','MissingValue',0);将数据存储划分为三个部分并返回第一个分区。partition 函数返回数据存储 ds 中大约三分之一的数据。
subds = partition(ds,3,1);
数据存储的 Files 属性包含该数据存储中所包含文件的列表。检查数据存储 ds 和分区后的数据存储 subds 的 Files 属性中的文件数。数据存储 ds 包含十个文件,分区 subds 包含前四个文件。
length(ds.Files)
ans = 10
length(subds.Files)
ans = 4
根据示例文件 mapredout.mat(mapreduce 函数的输出文件)创建一个数据存储。
ds = datastore('mapredout.mat');为 ds 获取默认数量的分区。
n = numpartitions(ds);
将数据存储划分到默认数量的分区中并返回与第一个分区对应的数据存储。
subds = partition(ds,n,1);
读取 subds 中的数据。
while hasdata(subds) data = read(subds); end
创建一个包含三个图像文件的数据存储。
ds = imageDatastore({'street1.jpg','peppers.png','corn.tif'})
ds =
ImageDatastore with properties:
Files: {
' ...\folder1\street1.jpg';
' ...\folder1\peppers.png';
' ...\folder1\corn.tif'
}
ReadSize: 1
Labels: {}
ReadFcn: @readDatastoreImage
按文件划分数据存储并返回与第二个文件对应的部分。
subds = partition(ds,'Files',2)
subds =
ImageDatastore with properties:
Files: {
' ...\folder1\peppers.png'
}
ReadSize: 1
Labels: {}
ReadFcn: @readDatastoreImage
subds 包含一个文件。
根据示例文件 mapredout.mat(mapreduce 函数的输出文件)创建一个数据存储。
ds = datastore('mapredout.mat');将数据存储划分为并行池中的三个工作单元的 3 个部分。
numWorkers = 3; p = parpool('local',numWorkers); n = numpartitions(ds,p); parfor ii=1:n subds = partition(ds,n,ii); while hasdata(subds) data = read(subds); end end
比较粗粒度分区和细粒度子集。
读取视频文件 xylophone.mp4 中的所有帧,并构造一个 ArrayDatastore 对象对其进行迭代。生成的对象有 141 个帧。
v = VideoReader("xylophone.mp4"); allFrames = read(v); arrds = arrayDatastore(allFrames,IterationDimension=4,OutputType="cell",ReadSize=4);
要提取一组特定的相邻帧,请创建 16 个粗粒度 arrds 分区。提取第二个分区,它有 9 个帧。
partds = partition(arrds,16,2); imshow(imtile(partds.readall()))
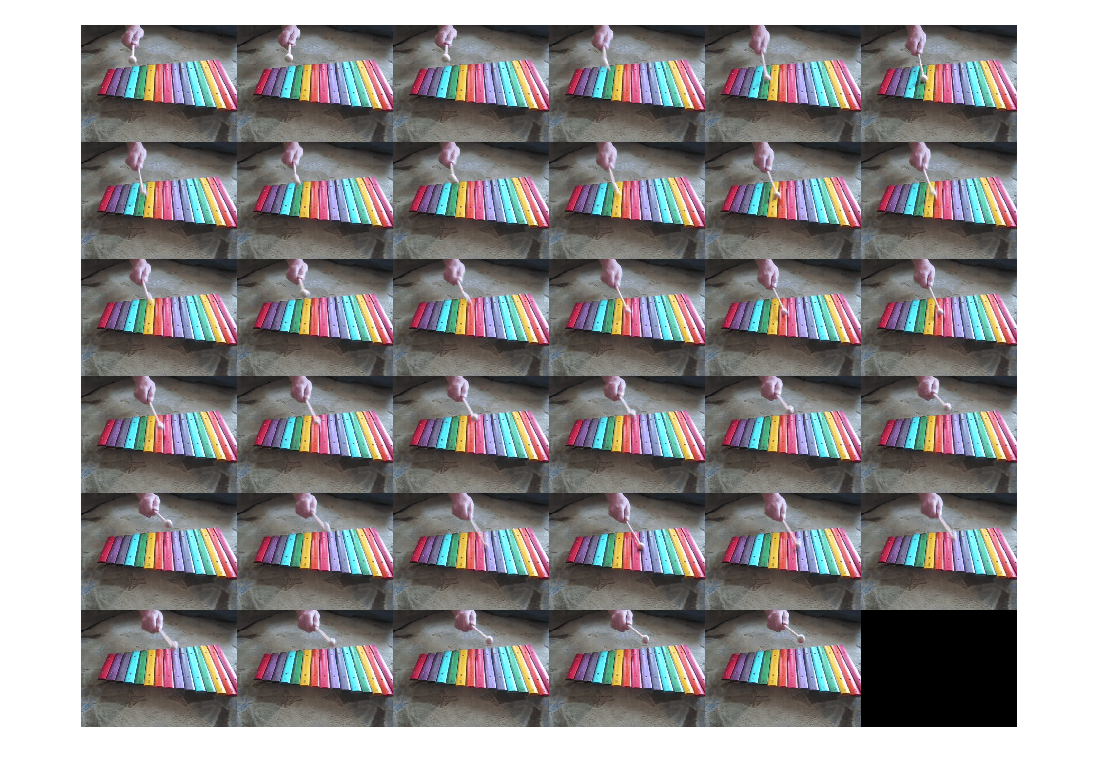
使用细粒度子集在指定索引处从 arrds 中提取两个不相邻的帧。
subds = subset(arrds,[67 79]); imshow(imtile(subds.readall()))

输入参数
输出参量
扩展功能
版本历史记录
在 R2015a 中推出