mode
数组中出现次数最多的值
说明
M = mode(A)A 的样本众数,即 A 中出现次数最多的值。如果有多个值以相同的次数出现,mode 将返回其中最小的值。对复杂的输入,最小值是排序列表的第一个值。
如果
A为向量,则mode(A)返回A中出现次数最多的值。如果
A为非空矩阵,那么mode(A)将返回包含A每列众数的行向量。如果
A为 0×0 空矩阵,mode(A)返回NaN。如果
A为多维数组,则mode(A)将沿大小不等于1的第一个数组维度的值视为向量,并返回一个由出现次数最多的值组成的数组。此维度的大小将变为1,而所有其他维度的大小保持不变。如果
A是表或时间表,则mode(A)返回单行表,其中包含每个变量的模式。 (自 R2023a 起)
示例
输入参数
输入数组,指定为向量、矩阵、多维数组、表或时间表。A 可以是数值数组、分类数组、日期时间数组、持续时间数组,或是其变量具有上述任何数据类型的表或时间表。
输入数组 A 中的 NaN 或 NaT(非时间值)值被忽略。分类数组中未定义的值类似于数值数组中的 NaN。
沿其运算的维度,指定为正整数标量。如果不指定维度,则默认值是大小不等于 1 的第一个数组维度。
维度 dim 表示长度减至 1 的维度。size(M,dim) 为 1,而所有其他维度的大小保持不变。
以一个 m×n 输入矩阵 A 为例:
mode(A,1)计算A的每列中元素的众数,并返回一个1×n行向量。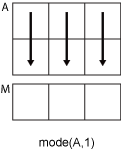
mode(A,2)计算A的每行中元素的众数,并返回一个m×1列向量。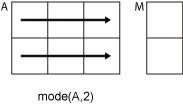
如果 dim 大于 ndims(A),则 mode 返回 A。
维度向量,指定为正整数向量。每个元素代表输入数组的一个维度。指定的操作维度的输出长度为 1,而其他保持不变。
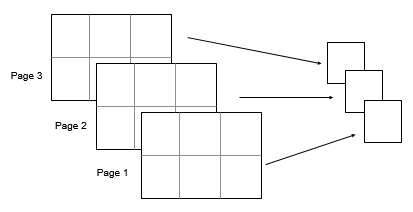
以 2×3×3 输入数组 A 为例。然后 mode(A,[1 2]) 返回一个 1×1×3 数组,其元素是 A 的每个页面的众数。
输出参量
提示
mode函数对于离散数据或粗略舍入数据非常有用。一个连续概率分布的众数被定义为其密度函数的峰值。将mode函数应用到不太可能产生良好峰值估计值的分布样本;这样能更好地计算出直方图或密度估计值并计算估计值的峰值。此外,mode函数也不适合查找具有多个众数的分布的峰值。
扩展功能
版本历史记录
在 R2006a 之前推出另请参阅
mean | median | histogram | histcounts | sort