fminsearch 算法
fminsearch 使用内尔德-米德单纯形算法,如拉加里亚斯等人的著作 [57] 中所述。此算法使用包含 n 维向量 x 的 n + 1 个点的单纯形。此算法首先向 x0 添加各分量 x0(i) 的 5% 并使用这 n 个向量作为除 x0 之外的单纯形元素,以围绕初始估计值 x0 生成一个单纯形。(如果 x0(i) = 0,则算法使用 0.00025 作为分量 i。)然后,此算法按照以下过程反复修改单纯形。
注意
fminsearch 迭代输出中的关键字在相应步骤的说明后以粗体形式显示。
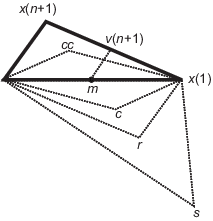
假设 x(i) 表示当前单纯形中点的列表,其中 i = 1...n + 1。
按最小函数值 f(x(1)) 到最大函数值 f(x(n + 1)) 的顺序对单纯形中的点进行排序。在迭代的每一步中,此算法都会放弃当前的最差点 x(n + 1) 并接受单纯形中的另一个点。[或者,在下面的步骤 7 中,此算法会更改值在 f(x(1)) 上方的所有 n 个点。]
生成反射点
r = 2m – x(n + 1),
其中
m = Σx(i)/n,i = 1...n,
并计算 f(r)。
如果 f(x(1)) ≤ f(r) < f(x(n)),则接受 r 并终止迭代。反射
如果 f(r) < f(x(1)),则计算延伸点 s
s = m + 2(m – x(n + 1)),
并计算 f(s)。
如果 f(s) < f(r),则接受 s 并终止迭代。延伸
否则,接受 r 并终止迭代。反射
如果 f(r) ≥ f(x(n)),则在 m 和 x(n + 1) 或 r(取目标函数值较低者)之间执行收缩。
如果 f(r) < f(x(n + 1))(即 r 优于 x(n + 1)),则计算
c = m + (r – m)/2
并计算 f(c)。如果 f(c) < f(r),则接受 c 并终止迭代。外收缩
否则,继续执行步骤 7(收缩)。
如果 f(r) ≥ f(x(n + 1)),则计算
cc = m + (x(n + 1) – m)/2
并计算 f(cc)。如果 f(cc) < f(x(n + 1)),则接受 cc 并终止迭代。内收缩
否则,继续执行步骤 7(收缩)。
计算 n 个点
v(i) = x(1) + (x(i) – x(1))/2
并计算 f(v(i)),i=2...n + 1。下一迭代中的单纯形为 x(1)、v(2)...v(n + 1)。收缩
下图显示了 fminsearch 可在此过程中计算的点,以及每种可能的新单纯形。原始单纯形采用粗体边框。迭代将在符合停止条件之前继续运行。