利用 HPC Challenge 对您的集群进行基准测试
此示例展示如何使用 HPC Challenge 基准测试来评估计算集群的性能。该基准测试由几项测量不同内存访问模式的测试组成。欲了解更多信息,请参阅 HPC Challenge 基准。
准备 HPC Challenge
使用 parpool 函数在集群中启动并行工作单元池。默认情况下,parpool 使用您的默认集群配置文件创建一个并行池。在主页选项卡上的并行 > 选择默认集群中检查您的默认集群配置文件。在这个基准上,工作单元互相通信。为了确保优化工作单元之间的通信,将 'SpmdEnabled' 设置为 true。
pool = parpool(64,'SpmdEnabled',true);Starting parallel pool (parpool) using the 'MyCluster' profile ... Connected to parallel pool with 64 workers.
使用 hpccDataSizes 函数计算满足 HPC Challenge 要求的每个单独基准的问题规模。这个大小取决于工作单元的数量和每个工作单元可用的内存量。例如,允许每个工作单元使用 1 GB。
gbPerWorker = 1; dataSizes = hpccDataSizes(pool.NumWorkers,gbPerWorker);
运行 HPC Challenge
HPC Challenge 基准测试由几个部分组成,每个部分探索系统不同方面的性能。在下面的代码中,每个函数运行一个基准测试,并返回包含性能结果的行表。这些函数测试分布式数组上的各种操作。MATLAB® 将分布式数组分区到多个并行工作单元中,以便它们能够使用集群的组合内存和计算资源。有关分布式数组的更多信息,请参阅 分布式数组。
HPL
hpccHPL(m),即 Linpack 基准,用于测量求解线性方程组的执行率。它创建了一个大小为 A×m 的随机分布实数矩阵 m 和一个长度为 b 的实数随机分布向量 m,并测量并行求解系统 x = A\b 的时间。其性能以 gigaflops(每秒十亿次浮点运算)为单位。
hplResult = hpccHPL(dataSizes.HPL);
Starting HPCC benchmark: HPL with data size: 27.8255 GB. Running on a pool of 64 workers Analyzing and transferring files to the workers ...done. Finished HPCC benchmark: HPL in 196.816 seconds.
DGEMM
hpccDGEMM(m) 测量实数矩阵-矩阵乘法的执行速率。它创建随机分布的实数矩阵 A、B 和 C,大小为 m×m,并测量并行执行矩阵乘法 C = beta*C + alpha*A*B 的时间,其中 alpha 和 beta 是随机标量。性能以 gigaflops 为单位返回。
dgemmResult = hpccDGEMM(dataSizes.DGEMM);
Starting HPCC benchmark: DGEMM with data size: 9.27515 GB. Running on a pool of 64 workers Analyzing and transferring files to the workers ...done. Finished HPCC benchmark: DGEMM in 69.3654 seconds.
STREAM
hpccSTREAM(m) 评估集群的内存带宽。它创建长度为 b 的随机分布向量 c 和 m,以及随机标量 k,并计算 a = b + c*k。该基准测试不使用工作单元之间的通信。性能以每秒千兆字节数返回。
streamResult = hpccSTREAM(dataSizes.STREAM);
Starting HPCC benchmark: STREAM with data size: 10.6667 GB. Running on a pool of 64 workers Analyzing and transferring files to the workers ...done. Finished HPCC benchmark: STREAM in 0.0796962 seconds.
PTRANS
hpccPTRANS(m) 测量系统的进程间通信速度。它创建两个大小为 A×B 的随机分布矩阵 m 和 m,并计算 A' + B。结果以每秒千兆字节为单位返回。
ptransResult = hpccPTRANS(dataSizes.PTRANS);
Starting HPCC benchmark: PTRANS with data size: 9.27515 GB. Running on a pool of 64 workers Analyzing and transferring files to the workers ...done. Finished HPCC benchmark: PTRANS in 6.43994 seconds.
RandomAccess
hpccRandomAccess(m) 测量分布式向量中每秒可随机更新的内存位置数量。结果以 GUPS(每秒千兆更新)的形式返回。在这次测试中,工作单元使用编译成 MEX 函数的随机数生成器。将此 MEX 函数针对每个操作系统架构的版本附加到并行池,以便工作单元可以访问与其操作系统相对应的版本。
addAttachedFiles(pool,{'hpccRandomNumberGeneratorKernel.mexa64','hpccRandomNumberGeneratorKernel.mexw64','hpccRandomNumberGeneratorKernel.mexmaci64'});
randomAccessResult = hpccRandomAccess(dataSizes.RandomAccess);Starting HPCC benchmark: RandomAccess with data size: 16 GB. Running on a pool of 64 workers Analyzing and transferring files to the workers ...done. Finished HPCC benchmark: RandomAccess in 208.103 seconds.
FFT
hpccFFT(m) 测量长度为 m 的分布式向量上的并行快速傅里叶变换 (FFT) 计算的执行速率。该测试既测量系统的算术能力,也测量通信性能。性能以 gigaflops 为单位返回。
fftResult = hpccFFT(dataSizes.FFT);
Starting HPCC benchmark: FFT with data size: 8 GB. Running on a pool of 64 workers Analyzing and transferring files to the workers ...done. Finished HPCC benchmark: FFT in 11.772 seconds.
显示结果
每个基准测试的结果都包含在一张包含统计数据的表中。连接这些行以提供测试结果的摘要。
allResults = [hplResult; dgemmResult; streamResult; ...
ptransResult; randomAccessResult; fftResult];
disp(allResults); Benchmark DataSizeGB Time Performance PerformanceUnits
______________ __________ ________ ___________ ________________
"HPL" 27.826 196.82 773.11 "GFlops"
"DGEMM" 9.2752 69.365 1266.4 "GFlops"
"STREAM" 10.667 0.079696 431.13 "GBperSec"
"PTRANS" 9.2752 6.4399 1.5465 "GBperSec"
"RandomAccess" 16 208.1 0.010319 "GUPS"
"FFT" 8 11.772 6.6129 "GFlops"
使用 batch 卸载计算
您可以使用 batch 函数将 HPC Challenge 中的计算卸载到您的集群并继续在 MATLAB 中工作。
在使用 batch 之前,请删除当前并行池。如果并行池已使用所有可用工作单元,则无法处理批处理作业。
delete(gcp);
使用 hpccBenchmark 将函数 batch 作为批处理作业发送到集群。该函数调用 HPC 挑战中的测试并在表中返回结果。当您使用 batch 时,一个工作单元将扮演 MATLAB 客户端的角色并执行该函数。此外,指定这些名称-值对参量:
'Pool':为该作业创建一个具有工作单元的并行池。在这种情况下,指定32工作单元。hpccBenchmark在这些工作单元上运行 HPC 挑战。'AttachedFiles':将文件传输到池中的工作单元。在这种情况下,为每个操作系统架构附加一个hpccRandomNumberGeneratorKernel版本。当执行hpccRandomAccess测试时,工作单元会访问与其操作系统相对应的那个。'CurrentFolder':设置工作单元的工作目录。如果不指定此参量,MATLAB 会将工作单元的当前目录更改为 MATLAB 客户端中的当前目录。如果您想使用工作单元的当前文件夹,请将其设置为'.'。当工作单元有不同的文件系统时这很有用。
gbPerWorker = 1;
job = batch(@hpccBenchmark,1,{gbPerWorker}, ...
'Pool',32, ...
'AttachedFiles',{'hpccRandomNumberGeneratorKernel.mexa64','hpccRandomNumberGeneratorKernel.mexw64','hpccRandomNumberGeneratorKernel.mexmaci64'}, ...
'CurrentFolder','.');提交作业后,您可以继续在 MATLAB 中工作。您可以使用作业监控程序检查作业的状态。在主页选项卡上的环境区域中,选择并行 > 监控作业。
在本例中,我们等待作业完成。要从集群中检索结果,请使用 fetchOutputs 函数。
wait(job);
results = fetchOutputs(job);
disp(results{1}) Benchmark DataSizeGB Time Performance PerformanceUnits
______________ __________ ________ ___________ ________________
"HPL" 13.913 113.34 474.69 "GFlops"
"DGEMM" 4.6376 41.915 740.99 "GFlops"
"STREAM" 5.3333 0.074617 230.24 "GBperSec"
"PTRANS" 4.6376 3.7058 1.3437 "GBperSec"
"RandomAccess" 8 189.05 0.0056796 "GUPS"
"FFT" 4 7.6457 4.9153 "GFlops"
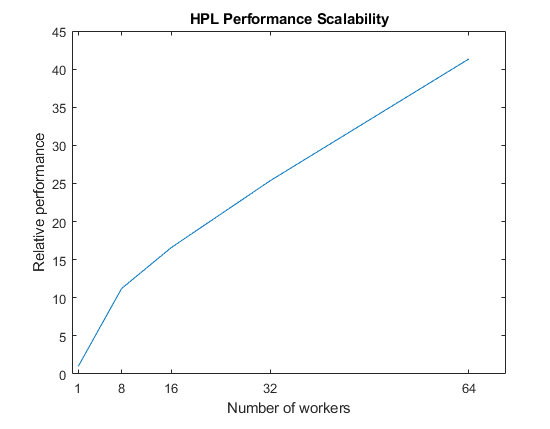
当您使用大型集群时,您可以增加可用的计算资源。如果计算时间超过了工作单元之间的通信时间,则您的问题可以通过增加资源得到很好的解决。下图显示了在具有 4 个计算机且每台计算机有 18 个物理核心的集群中,HPL 基准测试随工作单元数量的变化情况。请注意,在此基准测试中,数据的大小随着工作单元数量的增加而增加。