优化 parfor 循环,使用并行池仪表板
此示例演示了如何利用并行池仪表板中的池监控数据来优化一个 parfor 循环。
并行池仪表板是一个提供可视化界面来监控和优化并行任务的工具。您可以可视化工作单元之间的工作负载分布,以帮助您优化并行代码。
在此示例中,您使用一个 parfor 循环 来处理一组图像,通过计算它们的快速傅里叶变换 (FFT) 来完成处理。每张图像的计算负载取决于其文件大小,而文件大小可能存在显著差异。使用“并行池仪表板”了解工作单元的工作负载分布,并识别 parfor 循环中的任何瓶颈。
设置池并创建图像文件
使用 parpool 函数创建并行池。默认情况下,parpool 使用您的默认配置文件。在 MATLAB 主页选项卡上的并行 > 选择并行环境中检查您的默认配置文件。
pool = parpool;
Starting parallel pool (parpool) using the 'Processes' profile ... Connected to parallel pool with 6 workers.
使用 createFiles 辅助函数创建用于分析的图像文件集合,该函数在本示例末尾定义。
createFiles;
56 images generated.
获取图像文件名的列表,并提取图像的数量。预先分配一个结构体用于存储结果数据。
imageFiles = dir("images/*.jpg"); numImages = numel(imageFiles); outputSpectra = struct("scanNumber",[],"spectra",[]);
打开并行池仪表板
要打开“并行池仪表板”,请选择以下选项之一:
MATLAB® 工具条:在环境部分的主页选项卡中,选择并行>打开并行池仪表板。
并行状态指示灯:点击指示图标,然后选择打开并行池仪表板。
MATLAB 命令提示符:输入
parpoolDashboard。
使用 parfor 收集池监控数据用于图像处理
通过计算图像的快速傅里叶变换 (FFT) 来处理图像集合。使用 parfor 循环 加速图像处理,并借助在本示例末尾定义的 fftImage 辅助函数。
使用并行池仪表板收集监控数据。在并行池仪表板的监控部分,选择开始监控。当并行池仪表板开始收集监控数据时,返回实时编辑器,然后点击运行部分。
parfor idx = 1:numImages imgName = imageFiles(idx).name; outputSpectra(idx) = fftImage(imgName); end disp("Section complete.")
Section complete.
在完成部分代码后,在并行池仪表板的监控部分,选择停止。并行池仪表板显示监控结果。
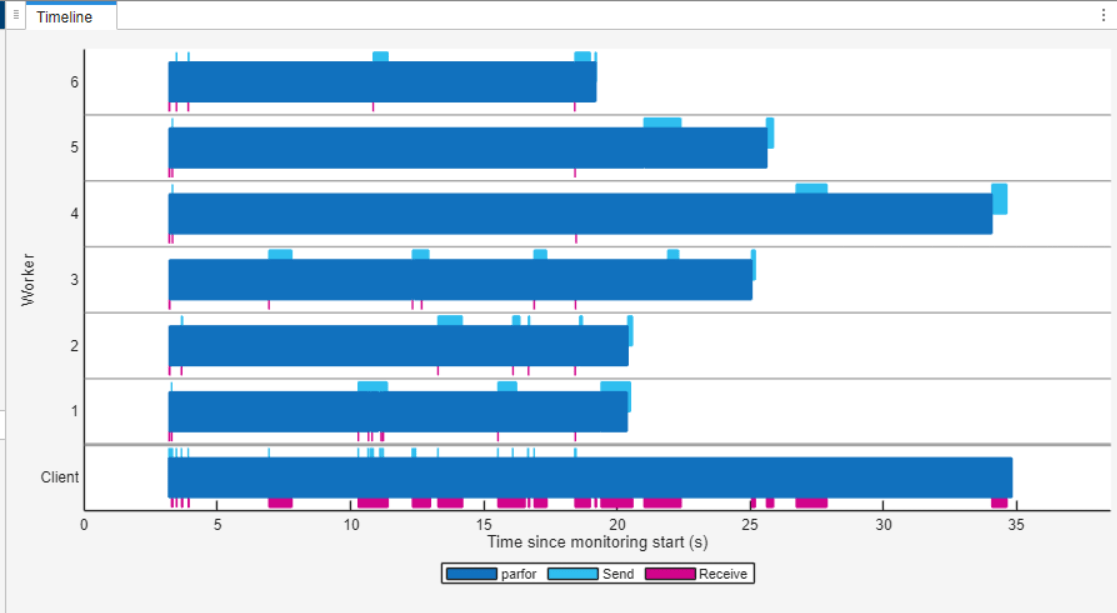
要查看监控数据,请关注时间轴图表。时间轴图直观地显示了工作单元和客户端运行 parfor 循环以及传输数据所花费的时间。深蓝色表示运行 parfor 循环所花费的时间,浅蓝色表示发送数据,而品红色表示接收数据。您可以看到,与其它工作单元相比,工作单元 3、4 和 5 处理 parfor 函数分配给它们的图像所需的时间明显更长。这一观察结果表明,负载在工作单元之间分配不均匀。
优化 parfor 负载分布
您可以采用不同的方法来优化 parfor 循环的负载分布。本节讨论了在每次迭代的工作负载未知和已知的情况下,如何实现更均衡的工作负载分布。
随机化文件
如果您对每次迭代的工作负载没有相关信息,随机调整处理顺序可以帮助平衡工作负载。要以随机顺序处理图像,请使用 randperm 函数生成图像文件索引的随机排列。
使用并行池仪表板收集监控数据,在并行池仪表板的监控部分,选择开始监控。当并行池仪表板开始收集监控数据时,返回实时编辑器,然后点击运行部分。
randIndices = randperm(numImages); randImageFiles = imageFiles(randIndices); parfor idx = 1:numImages imgName = randImageFiles(idx).name; outputSpectra(idx) = fftImage(imgName); end disp("Section complete")
Section complete
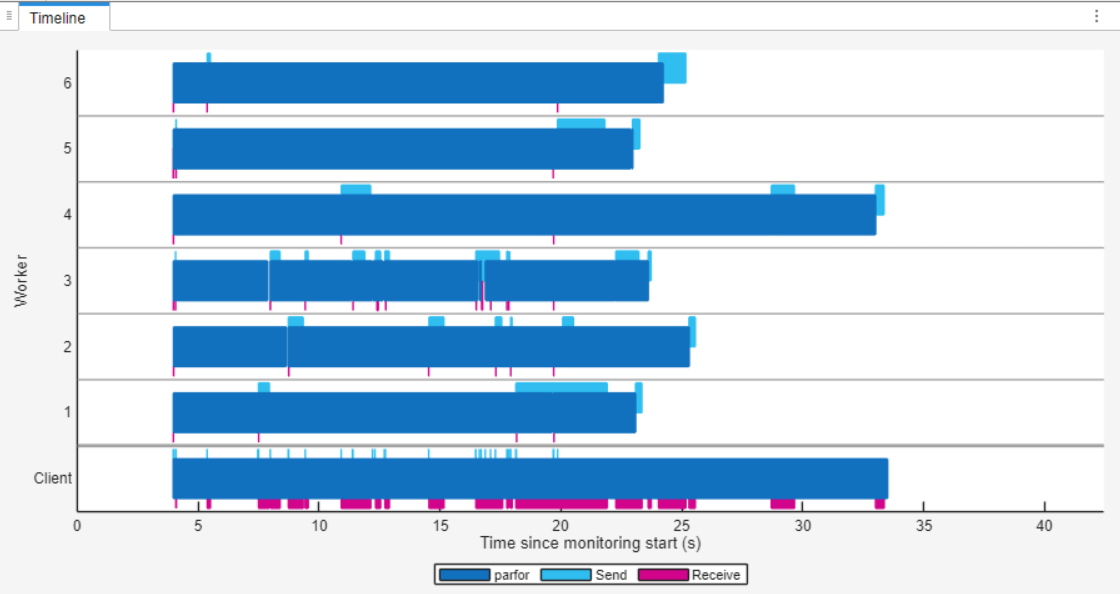
在完成部分代码后,在并行池仪表板的监控部分,选择停止。在时间轴图中,您可以看到与第一个 parfor 循环相比,工作单元的空闲时间更短。这一观察结果表明,负载分布比以前更加均衡。
控制 parfor 范围分区
在 parfor 循环中,子范围是一个连续的循环迭代块,作为一个组在工作单元上执行。您可以通过使用 parfor 函数来控制 parforOptions 如何将这些迭代划分为子范围。有关详细信息,请参阅parforOptions。
为了获得最佳性能,请尽量创建满足以下条件的子范围:
足够大,以使计算时间与子范围调度的开销相比相当可观
足够小,以确保有足够的子范围来保持所有工作单元的繁忙状态
在此示例中,每张图像的计算负载取决于其大小。为了更有效地划分迭代,您可以根据文件大小计算子范围。groupImageFilesBySize 辅助函数根据文件大小对图像文件进行分组,每个组中文件的累计大小不得超过最大图像文件大小的 1.5 倍。groupImageFilesBySize 函数作为支持文件附加到此示例。
[subranges,groupedImageFiles] = groupImageFilesBySize(imageFiles);
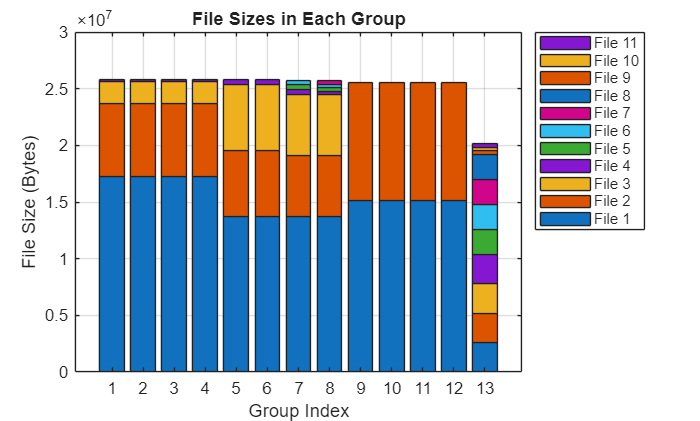
要了解 groupImageFilesBySize 函数如何对图像进行分组,请查看分组中文件大小的分布情况,以条形图形式展示。
barSubranges(groupedImageFiles,subranges);
要使用计算出的子范围运行 parfor 循环,请将函数句柄传递给 'RangePartitionMethod' 名称-值参量。该函数句柄必须返回一个子范围大小的向量,其总和必须等于迭代次数。
opts = parforOptions(pool,RangePartitionMethod=@(n,nw) subranges);
要使用并行池仪表板收集监控数据,请在监控部分中选择开始监控。当并行池仪表板开始收集监控数据时,返回实时编辑器,然后点击运行部分。
parfor (idx = 1:numImages,opts) imgName = groupedImageFiles(idx).name; outputSpectra(idx) = fftImage(imgName); end disp("Section complete")
Section complete
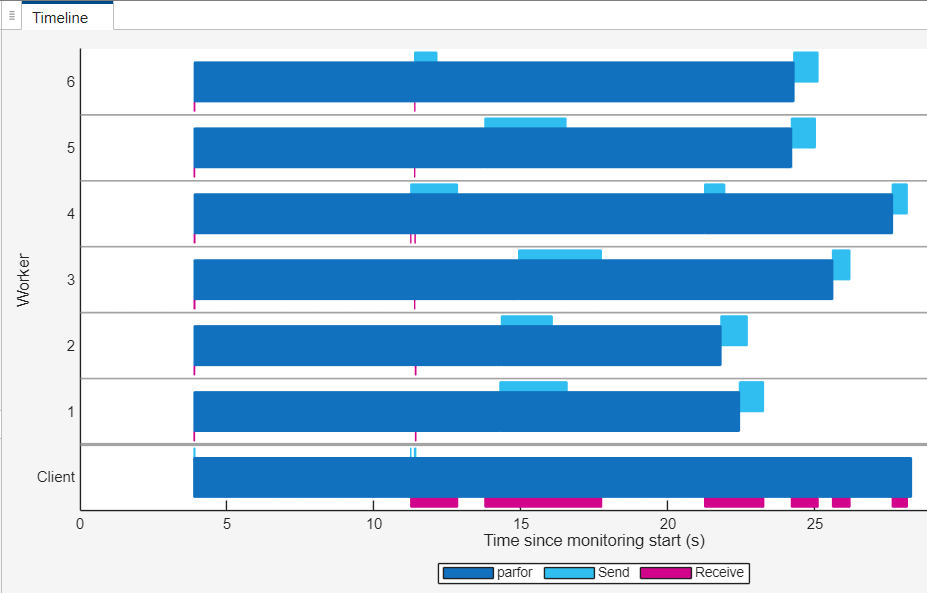
在完成部分代码后,在并行池仪表板的监控部分,选择停止。在时间轴图中,您可以看到与第一个 parfor 循环相比,几乎所有工作单元的空闲时间都较短。parfor 循环也以更短的时间完成。
将 parfor 循环转换为 parfeval 计算
并行处理时,除了使用 parfor 之外,还可以使用 parfeval 函数。使用 parfeval,您可以安排在每个迭代中对池工作单元进行函数评估。这种方法为工作单元的工作调度提供了更大的灵活性,并有助于防止工作单元处于空闲状态,因为每个工作单元每次只被分配一个迭代,如果没有新的 parfeval 计算任务,则可以执行其他任务。
对于每张图像,您可以使用 fftImage 调用 parfeval 辅助函数。该软件将每个函数调用排入并行池中的一个工作单元的执行队列。与将迭代分为子范围的 parfor 不同,parfeval 允许您单独管理每个任务。
要使用并行池仪表板收集监控数据,请在监控部分中选择开始监控。当并行池仪表板开始收集监控数据时,返回实时编辑器,然后点击运行部分。
futures(1:numImages) = parallel.Future; for idx = 1:numImages imgName = imageFiles(idx).name; futures(idx) = parfeval(@fftImage,1,imgName); end
随着每个任务的完成,您可以使用 fetchNext 函数获取任务结果。fetchNext 函数返回已完成任务的索引及其输出内容,从而使您能够按正确顺序存储结果。
for idx = 1:numImages [resultIdx,output] = fetchNext(futures); outputSpectra(resultIdx) = output; end disp("Section complete")
Section complete
在完成部分代码后,在并行池仪表板的监控部分,选择停止。
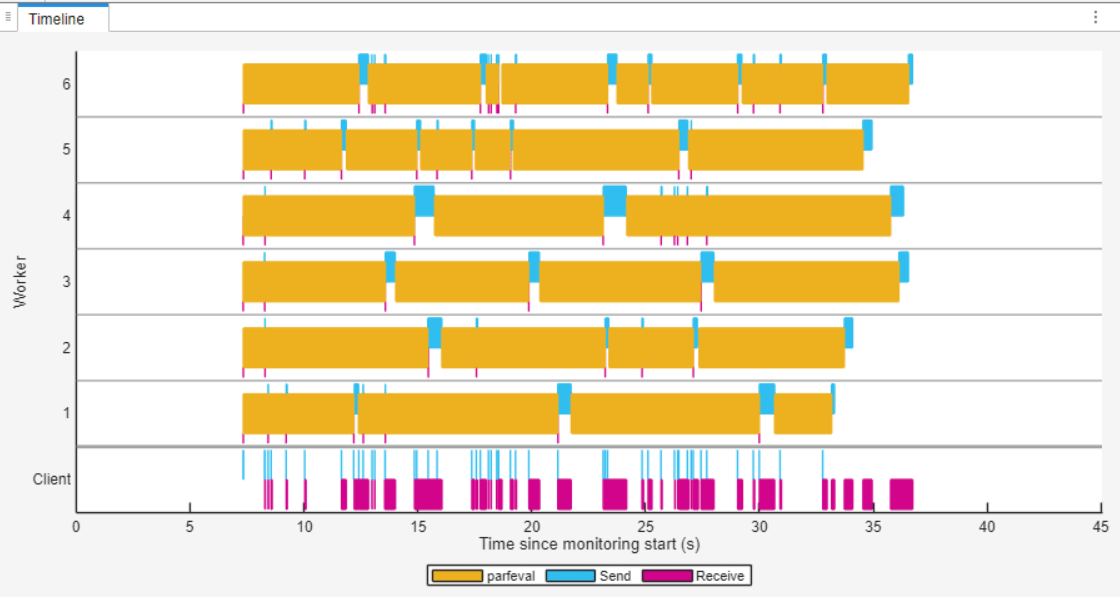
时间轴图表以黄色表示工作单元运行 parfeval 计算所花费的时间。在时间轴图中,您可以看到每个工作单元都完成了多个 parfeval 计算。一些工作单元在将结果数据传输回客户端时,会在两个 parfeval 计算之间保持 1 到 2 秒的空闲状态。然而,与第一个 parfor 循环相比,工作单元的空闲时间更短。
清理
使用后删除图像文件。
rmdir("images","s");
定义辅助函数
fftImage 函数计算图像的快速傅里叶变换 (FFT),并将结果存储在一个结构体中。
function output = fftImage(filename) % Read the image img = imread(fullfile("images",filename)); % Perform FFT imgFFT = fft2(double(img)); % Store the magnitude spectrum scanNum = "scan" + extract(filename,digitsPattern); output.scanNumber = scanNum; output.spectra = abs(fftshift(imgFFT)); end
createFiles 函数生成用于示例处理的图像,并将这些图像保存到 images 文件夹中。
function createFiles % Create folder to save images outputDir = "images"; if exist(outputDir,"dir") mkdir(outputDir); end % Define clusters of image sizes sizes = [50 60 74 60 150 348 400 420 448 160 174 250 260 274]; fileSizes = repmat(sizes,1,4); % Function to generate and save random images generateImages = @(fileSizes,outputDir,prefix) arrayfun(@(n) ... imwrite(repmat(peaks(20),[fileSizes(n)/2 fileSizes(n)]), ... fullfile(outputDir,sprintf("%s_image_%02d.jpg",prefix,n))),1:numel(fileSizes)); % Generate small, medium, and large images generateImages(fileSizes,outputDir,"scan"); fprintf("%d images generated.",numel(fileSizes)); end
barSubranges 函数以条形图的形式绘制每个子范围组中文件的大小。
function barSubranges(groupedImageFiles,subranges) % Initialize variables lastIdx = 0; bytes = [groupedImageFiles.bytes]; cumulativeSums = cumsum(subranges); % Prepare data for the stacked bar chart stackedData = zeros(numel(subranges),max(subranges)); for idx = 1:numel(subranges) firstIdx = lastIdx + 1; lastIdx = cumulativeSums(idx); groupBytes = bytes(firstIdx:lastIdx); stackedData(idx,1:numel(groupBytes)) = groupBytes; end % Plot the stacked bar chart figure; bar(stackedData,"stacked"); xlabel("Group Index"); ylabel("File Size (Bytes)"); title("File Sizes in Each Group"); legendStr = arrayfun(@(x) sprintf('File %d',x),1:size(stackedData,2),UniformOutput=false); legend(legendStr,Location="northeastoutside"); grid on; end