分析显式并行通信
此示例显示了如何探查与最近邻工作单元之间的显式通信。它说明了 spmdSend、spmdReceive 和 spmdSendReceive 的用法,展示了实现该算法的慢速(不正确)和快速(最佳)方法。使用并行探查器探究该问题。要开始进行并行分析,请参阅 探查并行代码。
本示例中的数字是由 12 节点集群生成的。
示例代码涉及明确的通信。在 MATLAB® 中,明确通信与直接使用 Parallel Computing Toolbox™ 通信原语(例如 spmdSend、spmdReceive、spmdSendReceive、spmdBarrier)是同义的。如果与此类通信相关的性能问题与底层硬件无关,则可能难以追踪。利用并行探查器可以以交互方式识别许多此类问题。重要的是要记住,您可以将程序的各个部分分成单独的函数。这在分析时很有帮助,因为仅针对每个函数收集了一些数据。
算法
我们正在分析的算法是最近邻通信模式。每个 MATLAB 工作单元只需要来自自身和一个邻近实验室的数据。这种数据并行模式很适合解决许多矩阵问题,但如果操作不正确,可能会不必要地缓慢。换句话说,每个实验室都依赖于相邻实验室已提供的数据。例如,在一个四实验室集群中,实验室 1 想要向实验室 2 发送一些数据,并且需要来自实验室 4 的一些数据,因此每个实验室只依赖于另一个实验室:
1 取决于 -> 4
2 取决于 -> 1
3 取决于 -> 2
4 取决于 -> 3
可以使用 spmdSend 和 spmdReceive 实现任何给定的通信算法。spmdReceive 始终会阻止您的程序,直到通信完成为止,而 spmdSend 可能不会(如果数据较小)。不过,大多数情况下首先使用 spmdSend 没有帮助。
实现该算法的一种方法是让每个工作单元等待接收,并且只有一个工作单元通过完成发送然后接收来启动通信链。或者,我们可以使用 spmdSendReceive,乍一看可能不会发现性能上存在很大差异。
您可以查看 pctdemo_aux_profbadcomm 和 pctdemo_aux_profcomm 的代码来了解该算法的完整实现。查看第一个文件并注意它使用 spmdSend 和 spmdReceive 进行通信。
在没有必要的时候开始以 spmdSend 和 spmdReceive 的角度思考是一个常见的错误。观察这个 pctdemo_aux_profbadcomm 实现的表现可以让我们更好地了解将会发生什么。
分析 spmdSend 的实现
spmd spmdBarrier; % to ensure the workers all start at the same time mpiprofile reset; mpiprofile on; pctdemo_aux_profbadcomm; end
Worker 1: sending to 2 Worker 2: receive from 1 Worker 3: receive from 2 Worker 4: receive from 3 Worker 5: receive from 4 Worker 6: receive from 5 Worker 7: receive from 6 Worker 8: receive from 7 Worker 9: receive from 8 Worker 10: receive from 9 Worker 11: receive from 10 Worker 12: receive from 11 Worker 1: receive from 12 Worker 2: sending to 3 Worker 3: sending to 4 Worker 4: sending to 5 Worker 5: sending to 6 Worker 6: sending to 7 Worker 7: sending to 8 Worker 8: sending to 9 Worker 9: sending to 10 Worker 10: sending to 11 Worker 11: sending to 12 Worker 12: sending to 1
mpiprofile viewer将显示并行配置文件摘要。在此页面上,您可以看到在总时间图列下等待通信所花费的时间(橙色条)。以下数据显示等待花费了大量的时间。让我们看看并行探查器如何帮助识别这些等待的原因。
快速入门步骤
查看并行配置文件摘要表,然后点击工具条比较部分中的最大与最小总时间按钮。观察
pctdemo_aux_profbadcomm>iRecFromPrevLab条目所指示的较大橙色等待时间。这是一个早期迹象,表明相应的发送存在问题,可能是由于网络问题或算法问题。要查看工作单元与工作单元之间的通信图,请展开并行配置文件摘要的“图”部分,然后点击工具条的图部分中的热图按钮。该视图中的第一个图显示了每个工作单元收到的所有数据。在这个示例中,每个工作单元都从前一个工作单元接收相同数量的数据,所以这似乎不是一个数据分布问题。第二张图显示了各种通信时间,包括等待通信的时间。在第三张图中,“每个工作单元的通信等待时间”图显示等待时间逐步增加。下面可以看到使用 12 节点集群的每个工作单元通信等待时间示例图。最好回去检查一下源工作单元中发生的情况。
浏览工作单元 1 上发生的情况。点击顶层
pctdemo_aux_profbadcomm函数即可转到函数详细报告。向下滚动到函数列表部分,查看工作单元 1 花费时间的地方以及覆盖了哪些线路。为了与上一个工作单元进行比较,请使用工具条比较部分中的转到工作单元菜单选择上一个工作单元,然后检查繁忙线路表。
要查看所有分析过的代码行,请向下滚动到页面的最后一项。下面是该已注解的代码列表的一个示例。
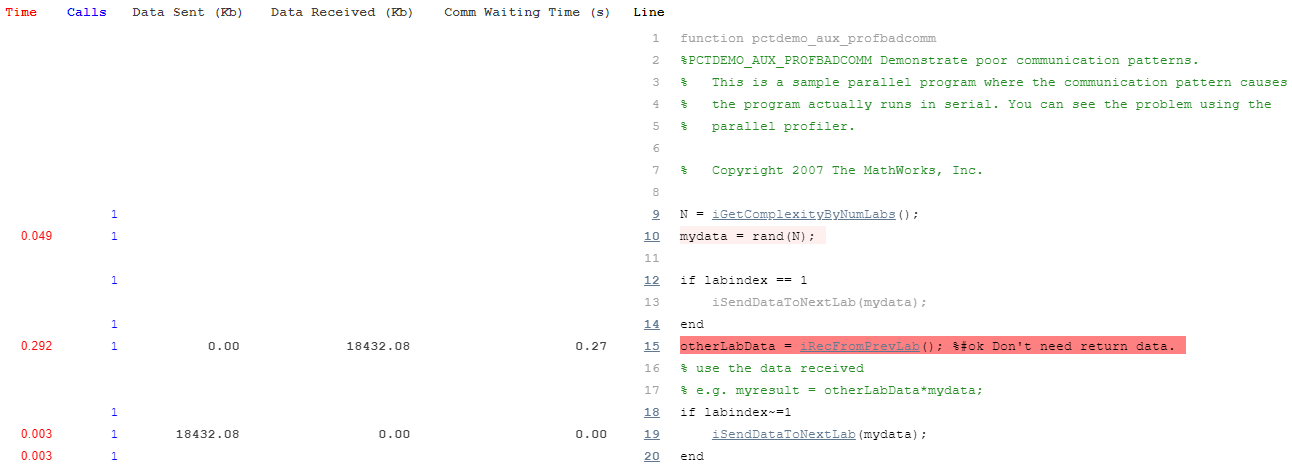
使用更大的非本地集群的通信图
为了清楚地看到我们使用 spmdSend 和 spmdReceive 时存在的问题,请查看以下来自 12 节点集群的通信时间(等待)图。
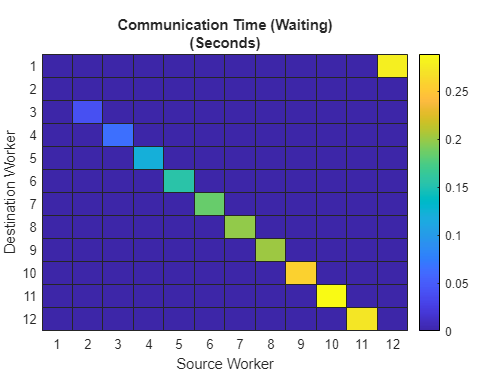
在上面的图中,您可以看到使用工作单元到工作单元通信图的所有函数都出现了不必要的等待。等待时间随着工作单元数量的增加而增加,因为 spmdReceive 会阻止,直到相应配对的 spmdSend 完成为止。因此,即使后续工作单元只需要来自直接邻居 spmdIndex 的数据,您也可以获得顺序通信。
使用 spmdSendReceive 实现此算法
您可以使用 spmdSendReceive 从您所依赖的工作单元同时发送和接收数据,以获得最短的等待时间。您可以在 pctdemo_aux_profcomm 中实现的通信模式的更正版本中看到这一点。显然,如果您需要先接收数据然后才能发送数据,则无法使用 spmdSendReceive。在这种情况下,使用 spmdSend 和 spmdReceive 来确保时间顺序。但是,像本示例这样的情况下,当发送之前不需要接收数据时,请使用 spmdSendReceive。对此版本配置文件而不重置上一版本收集的数据(使用 mpiprofile resume)。
spmd spmdBarrier; mpiprofile resume; pctdemo_aux_profcomm; end
Worker 1: sending to 2 receiving from 12 Worker 2: sending to 3 receiving from 1 Worker 3: sending to 4 receiving from 2 Worker 4: sending to 5 receiving from 3 Worker 5: sending to 6 receiving from 4 Worker 6: sending to 7 receiving from 5 Worker 7: sending to 8 receiving from 6 Worker 8: sending to 9 receiving from 7 Worker 9: sending to 10 receiving from 8 Worker 10: sending to 11 receiving from 9 Worker 11: sending to 12 receiving from 10 Worker 12: sending to 1 receiving from 11
mpiprofile viewer此修正版本将等待时间有效减少至零。为了看到这一点,请查看 pctdemo_aux_profcomm 函数的工作单元与工作单元通信的图。使用 spmdSendReceive,相同的通信模式现在几乎不需要等待,如下面的通信时间(等待)图所示。
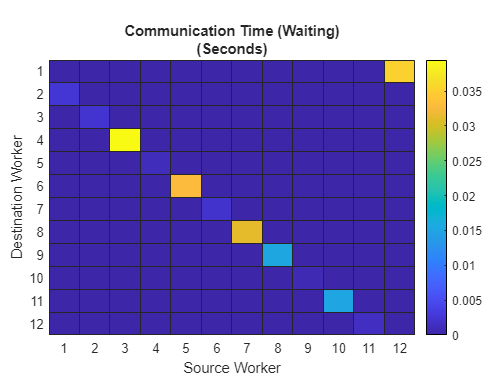
绘图着色方案
对于每个二维图像图,着色方案都根据当前任务进行标准化。因此,不要使用上图所示的着色方案与其他图进行比较,因为颜色是标准化的并且取决于最大值。对于此示例,使用最大值是比较使用 pctdemo_aux_profcomm 而不是 pctdemo_aux_profbadcomm 时等待时间的巨大差异的最佳方法。