分析负载不平衡的共存分布式数组
此示例说明如何配置文件使用不均匀分布数组时发生的隐式通信。要开始进行并行分析,请参阅 探查并行代码。
此示例说明如何在数组分布不均匀的情况下使用并行探查器。创建共存分布式数组的最简单方法是传递 codistributor 作为参量,例如 rand(N, codistributor)。这会在 MATLAB® 工作单元之间均匀分配大小为 N 的矩阵。为了获得不平衡的数据分布,您可以获取一些共存分布式数组的列作为 spmdIndex 的函数。
本示例中的数据传输图是使用具有 12 个工作单元的本地集群生成的。其余所有内容均在具有 4 个工作单元的本地集群上运行。
算法
我们为这个共存分布式数组选择的算法相对简单。我们生成一个大矩阵,使得每个实验室都获得一个大约 512×512 的子矩阵,第一个实验室除外。第一个实验室只接收矩阵的一列,其他列分配给最后一个实验室。因此,在四实验室集群中,实验室 1 仅保留 1×512 的列,实验室 2 和 3 有其分配的分区,实验室 4 有其分配的分区加上额外的列(从实验室 1 剩下的)。最终结果是,在执行零通信元素操作(例如 sin)时工作负载不平衡,并且数据并行操作(例如 codistributed/mtimes)存在通信延迟。我们首先从数据并行操作开始 (codistributed/mtimes)。然后,我们循环执行 sqrt、sin 和内积运算,所有这些运算仅对矩阵的各个元素进行操作。
本示例的 MATLAB 文件代码可在以下位置找到:pctdemo_aux_profdistarray
在这个示例中,矩阵的大小根据 MATLAB 工作单元 (spmdSize) 的数量而不同。不过,在任何集群上运行此示例所需的计算时间(不包括通信)大约相同,因此您可以尝试使用更大的集群,而不必等待很长时间。
spmd spmdBarrier; % synchronize all the labs mpiprofile reset mpiprofile on pctdemo_aux_profdistarray(); end
Worker 1: This lab has 1024 rows and 1 columns of a codistributed array Worker 2: This lab has 1024 rows and 256 columns of a codistributed array Worker 3: This lab has 1024 rows and 256 columns of a codistributed array Worker 4: This lab has 1024 rows and 511 columns of a codistributed array Worker 1: Calling mtimes on codistributed arrays Calling embarrassingly parallel math functions (i.e. no communication is required) on a codistributed array. Done Worker 2: Calling mtimes on codistributed arrays Calling embarrassingly parallel math functions (i.e. no communication is required) on a codistributed array. Done Worker 3: Calling mtimes on codistributed arrays Calling embarrassingly parallel math functions (i.e. no communication is required) on a codistributed array. Done Worker 4: Calling mtimes on codistributed arrays Calling embarrassingly parallel math functions (i.e. no communication is required) on a codistributed array. Done
mpiprofile viewer首先,浏览并行配置文件摘要,通过点击“总时间”列确保它按执行时间排序。然后按照函数 pctdemo_aux_profdistarray 的链接查看函数详细报告。
函数详细信息报告中的忙线表
每个 MATLAB 函数条目都有自己的忙线表,如果您想同时配置文件多个程序或示例,这很有用。
在函数详细报告中,逐行观察执行的 MATLAB 代码的通信信息。
要比较分析信息,请点击 App 工具条的查看部分中的忙线按钮。在工具条的比较部分中,点击最大与最小总时间按钮,然后在转到工作单元和比较菜单中选择要比较的工作单元数量。观察繁忙线路表并检查哪些线路号耗费的时间最多。此代码中没有 for 循环,也没有增加复杂性。然而,各个实验室之间的计算量仍然存在很大差异。查看第 35 行,其中包含代码
sqrt( sin( D .* D ) );。
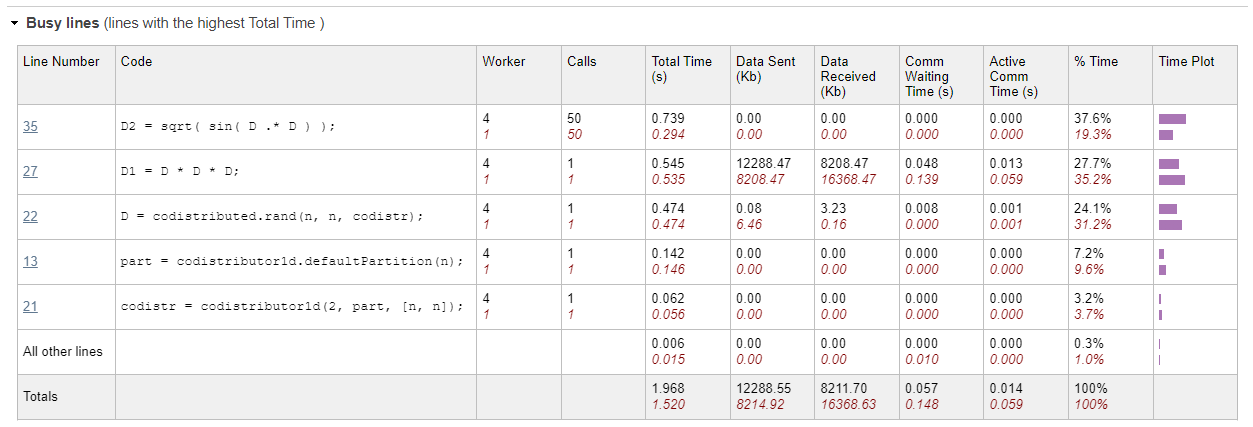
尽管这种逐元素操作不需要通信,但性能并不是最佳的,因为有些实验室比其他实验室做的工作更多。在第二行 (D*D*D) 中,两个实验室所花费的总时间相同。但是,“已接收数据”和“已发送数据”列显示发送和接收的数据量存在很大差异。所有实验室中此 mtimes 操作所花费的时间都相似,因为共存分布式数组通信隐式同步了它们之间的通信。
在忙线表的最后一列,有一个条形图显示所选字段的百分比。这些条形图还可用于直观地比较主实验室和比较实验室的总时间以及发送的数据或接收的数据。
使用绘图观察共存分布式数组操作
要获取有关共存分布式数组操作的更多具体信息,请点击函数详细报告中的相关函数名称。
要获取实验室间通信数据,请点击工具条 Plots 部分中的 Heatmap。在第一个图中,您可以看到实验室 1 传输的数据量最多,而最后一个实验室(实验室 12)传输的数据量最少。
使用热图,您还可以看到每个实验室之间传达的数据量。除第一个和最后一个实验室外,所有实验室都是恒定的。如果没有显式通信,这表明存在分布问题。在典型的共存分布式数组 mtimes 操作中,拥有数据量最少的实验室(例如实验室 1)从其相邻的实验室(例如实验室 2)接收所有所需的数据。
数据传输图
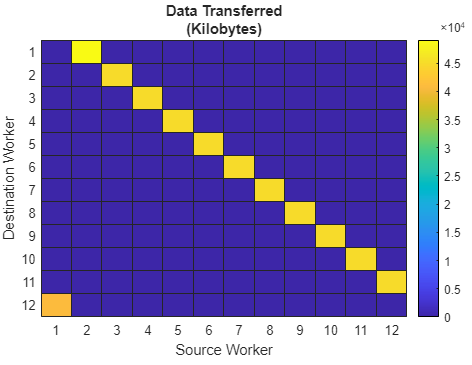
在数据传输图中,传输到最后一个实验室的数据量明显减少,而传输到第一个实验室的数据量则增加。观察通信时间图(未显示)进一步说明第一个实验室中发生了一些不同的事情。也就是说,第一个实验室在通信上花费的时间最长。
如您所见,矩阵的不均匀分布在使用数据并行共存分布式数组操作时会导致不必要的通信延迟,以及在使用任务并行(无通信)操作时导致不均匀的工作分布。此外,接收更多数据的实验室(如本示例中的第一个实验室)在共存分布式数组操作之前以最少的数据开始。