DBSCAN Clusterer
Cluster detections
Libraries:
Radar Toolbox
Description
Cluster data using the density-based spatial clustering of applications with noise (DBSCAN) algorithm. The DBSCAN Clusterer block can cluster any type of data. The block can also solve for the clustering threshold (epsilon) and can perform data disambiguation in two dimensions.
Examples
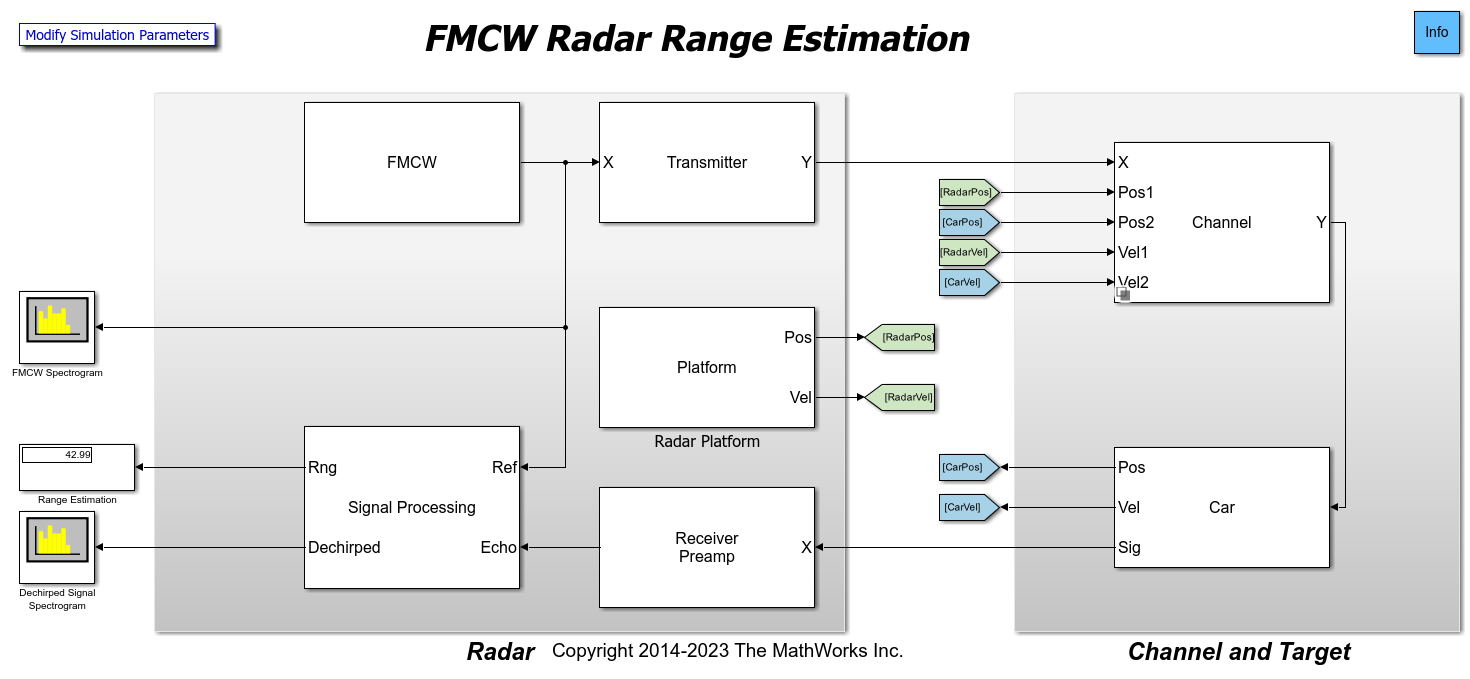
Automotive Adaptive Cruise Control Using FMCW and MFSK Technology
Model an automotive radar in Simulink® that includes adaptive cruise control.
Ports
Input
Input data, specified as a real-valued N-by-P matrix, where N is the number of data points to cluster. P is the number of feature dimensions. The DBSCAN algorithm can cluster any type of data with appropriate Minimum number of points in a cluster and Cluster threshold epsilon settings.
Data Types: double
Enable automatic update of the epsilon estimate, specified as
false or true.
When
true, the epsilon threshold is first estimated as the average of the knees of the k-NN search curves. The estimate is then added to a buffer of size L, set by the Length of cluster threshold epsilon history parameter. The final value of epsilon is calculated as the average of the L-length epsilon history buffer. If Length of cluster threshold epsilon history is set to one, the estimate is memory-less. Memory-less means that each epsilon estimate is immediately used and no moving-average smoothing occurs.When
false, a previous epsilon estimate is used. Estimating epsilon is computationally intensive and not recommended for large data sets.
Dependencies
To enable this port, set the Source of cluster threshold
epsilon parameter to Auto and set the
Maximum number of points for 'Auto' epsilon parameter.
Data Types: Boolean
Ambiguity limits, specified as a 1-by-2 real-valued vector or 2-by-2 real-valued matrix. For a single ambiguity dimension, specify the limits as a 1-by-2 vector [MinAmbiguityLimitDimension1,MaxAmbiguityLimitDimension1]. For two ambiguity dimensions, specify the limits as a 2-by-2 matrix [MinAmbiguityLimitDimension1, MaxAmbiguityLimitDimension1; MinAmbiguityLimitDimension2,MaxAmbiguityLimitDimension2].
Clustering can occur across boundaries to ensure that ambiguous detections are
appropriately clustered for up to two dimensions. The ambiguous columns of the input
port data X are defined using the Indices of ambiguous
dimensions parameter. The AmbLims parameter defines
the minimum and maximum ambiguity limits in the same units as used in the
Indices of ambiguous dimensions columns of the input data
X.
Dependencies
To enable this port, select the Enable disambiguation of dimensions check box.
Data Types: double
Output
Cluster indices, returned as an N-by-1 integer-valued column
vector. Cluster IDs represent the clustering results of the DBSCAN algorithm. A value
equal to '-1' implies a DBSCAN noise point. Positive Idx values
correspond to clusters that satisfy the DBSCAN clustering criteria.
Dependencies
To enable this port, set the Define outputs for Simulink
block parameter to Index or
Index and ID.
Data Types: double
Alternative cluster IDs, returned as a 1-by-N row vector of
positive integers. Each value is a unique identifier indicating a hypothetical target
cluster. This argument contains unique positive cluster IDs for all points including
noise. In contrast, the Idx output argument labels noise points
with '–1'. Use this output as input to Phased Array System Toolbox™ blocks such as Range Estimator and Doppler Estimator.
Dependencies
To enable this port, set the Define outputs for Simulink
block parameter to Cluster ID or
Index and ID.
Data Types: double
Parameters
Type of cluster data output, specified as:.
Index and ID–- Enables theIdxandClustersoutput ports.Cluster ID–- Enables theClustersoutput port only.Index–- Enables theIdxoutput port only.
Epsilon source for cluster threshold:
Property— Epsilon is obtained from the Cluster threshold epsilon parameter.Auto— Epsilon is estimated automatically using a k-nearest neighbor (k-NN) search. The search is calculated with k ranging from one less than the value of Minimum number of points in a cluster to one less than the value of Maximum number of points for 'Auto' epsilon. The subtraction of one is needed because the neighborhood of a point includes the point itself.
Cluster neighborhood size for a search query, specified as a positive scalar or
real-valued 1-by-P row vector. P is the number of
clustering dimensions in the input data X.
Epsilon defines the radius around a point inside which to count the number of detections. When epsilon is a scalar, the same value applies to all clustering feature dimensions. You can specify different epsilon values for different clustering dimensions by specifying a real-valued 1-by-P row vector. Using a row vector creates a multi-dimensional ellipse search area, which is useful when the data columns have different physical meanings such as range and Doppler.
Minimum number of points required for a cluster, specified as a positive integer. This parameter defines the minimum number of points in a cluster when determining whether a point is a core point.
Maximum number of points in a cluster, specified as a positive integer. This property is used to estimate epsilon when the object performs a k-NN search.
Dependencies
To enable this parameter, set the Source of cluster threshold
epsilon parameter to Auto.
Length of the stored cluster threshold epsilon history, specified as a positive integer. When set to one, the history is memory-less. Then, each epsilon estimate is immediately used and no moving-average smoothing occurs. When greater than one, the epsilon value is averaged over the history length specified.
Example: 5
Data Types: double
Check box to enable disambiguation of dimensions, specified as
false or true. When checked, clustering occurs
across boundaries defined by the values in the input port AmbLims
at execution. Ambiguous detections are appropriately clustered. Use the
Indices of ambiguous dimensions parameter to specify those column
indices of X in which ambiguities can occur. Up to two ambiguous
dimensions are permitted. Turning on disambiguation is not recommended for large data
sets.
Data Types: Boolean
Indices of ambiguous dimensions, specified as a positive integer or 1-by-2 vector of
positive integers. This property specifies the column indices of the input port data
X in which disambiguation can occur. A positive integer
corresponds to a single ambiguous dimension in the input data matrix
X. A 1-by-2 length row vector of indices corresponds to two
ambiguous dimensions. The size and order of Indices of ambiguous
dimensions must be consistent with the AmbLims input
port value.
Example: [3 4]
Dependencies
To enable this parameter, select the Enable disambiguation of dimensions check box.
Data Types: double
Block simulation, specified as Interpreted Execution or Code
Generation. If you want your block to use the MATLAB® interpreter,
choose Interpreted Execution. If you want
your block to run as compiled code, choose Code Generation.
Compiled code requires time to compile but usually runs faster.
Interpreted execution is useful when you are developing and tuning a model. The block runs the
underlying System object™ in MATLAB. You can change and execute your model quickly. When you are satisfied
with your results, you can then run the block using Code
Generation. Long simulations run faster with generated code than in
interpreted execution. You can run repeated executions without recompiling, but if you
change any block parameters, then the block automatically recompiles before
execution.
This table shows how the Simulate using parameter affects the overall simulation behavior.
When the Simulink model is in Accelerator mode, the block mode specified
using Simulate using overrides the simulation mode.
Acceleration Modes
| Block Simulation | Simulation Behavior | ||
Normal | Accelerator | Rapid Accelerator | |
Interpreted Execution | The block executes using the MATLAB interpreter. | The block executes using the MATLAB interpreter. | Creates a standalone executable from the model. |
Code Generation | The block is compiled. | All blocks in the model are compiled. | |
For more information, see Choosing a Simulation Mode (Simulink).
Extended Capabilities
C/C++ Code Generation
Generate C and C++ code using Simulink® Coder™.
Version History
Introduced in R2021a
MATLAB Command
You clicked a link that corresponds to this MATLAB command:
Run the command by entering it in the MATLAB Command Window. Web browsers do not support MATLAB commands.
选择网站
选择网站以获取翻译的可用内容,以及查看当地活动和优惠。根据您的位置,我们建议您选择:。
您也可以从以下列表中选择网站:
如何获得最佳网站性能
选择中国网站(中文或英文)以获得最佳网站性能。其他 MathWorks 国家/地区网站并未针对您所在位置的访问进行优化。
美洲
- América Latina (Español)
- Canada (English)
- United States (English)
欧洲
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)