Train Biped Robot to Walk Using Evolution Strategy-Reinforcement Learning Agents
This example shows how to train a biped robot to walk using and evolution strategy with twin-delayed deep deterministic policy gradient (TD3) reinforcement learning agent. The robot in this example is modeled in Simscape™ Multibody™.
For a related example, see Train Biped Robot to Walk Using Reinforcement Learning Agents. For more information on these agents, see Twin-Delayed Deep Deterministic (TD3) Policy Gradient Agent.
The agent is trained using an evolution strategy reinforcement learning algorithm (ES-RL). The ES-RL method [3] combines cross entropy method (CEM) with off-policy RL algorithms like SAC, DDPG or TD3. CEM-RL is built on the framework of evolutionary reinforcement learning (ERL) [4] in which the standard evolution algorithm selects and evolves a population of actors and generate the experiences in the process. These experiences are then added into the reply buffer to train the actor and critic networks.
A general flow of the ES-RL algorithm proceeds as follows:
A population of actor networks is initialized with random weights. In addition to the population, one additional actor network is initialized alongside a critic network.
The population of actors is then evaluated in an episode of interaction with the environment.
The actor and critic are updated on the data buffer populated using population actor evaluation.
Fitness of all actors is computed through interacting with the environment. The average return over the episode is used as their respective fitness index.
A selection operator selects a surviving actors in the population based on their relative fitness scores.
The surviving elite set of actor is used to generate the next population of the actor.
Fix Random Number Stream for Reproducibility
The example code might involve computation of random numbers at several stages. Fixing the random number stream at the beginning of some sections in the example code preserves the random number sequence in the section every time you run it, which increases the likelihood of reproducing the results. For more information, see Results Reproducibility.
Fix the random number stream with seed 0 and random number algorithm Mersenne Twister. For more information on controlling the seed used for random number generation, see rng.
previousRngState = rng(0,"twister");The output previousRngState is a structure that contains information about the previous state of the stream. You will restore the state at the end of the example.
Biped Robot Model
The reinforcement learning environment for this example is a biped robot. The training goal is to make the robot walk in a straight line using minimal control effort.
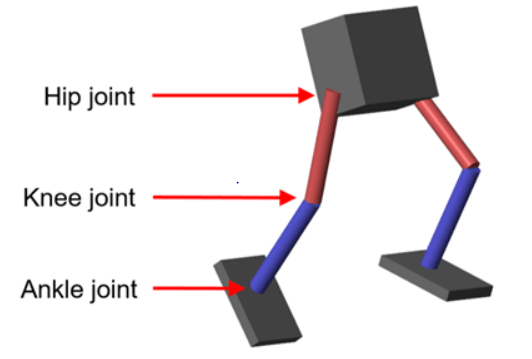
Load the parameters of the model into the MATLAB® workspace.
robotParametersRL
Open the Simulink® model.
mdl = "rlWalkingBipedRobot";
open_system(mdl)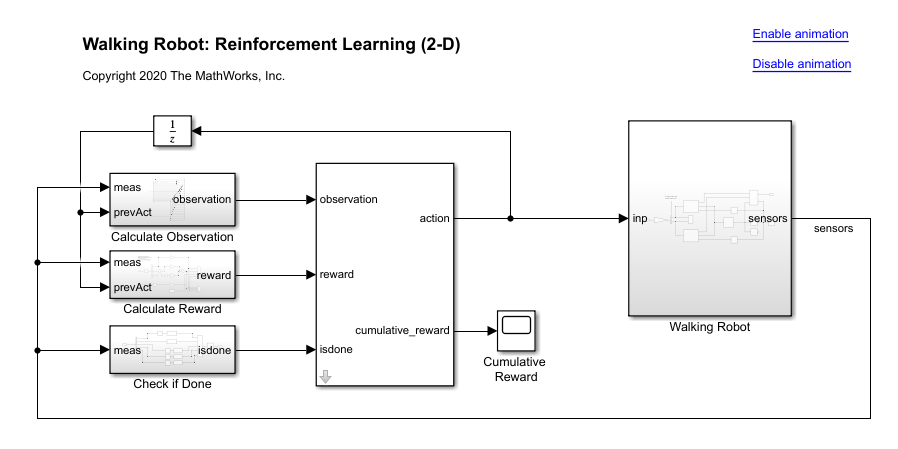
The robot is modeled using Simscape™ Multibody™.
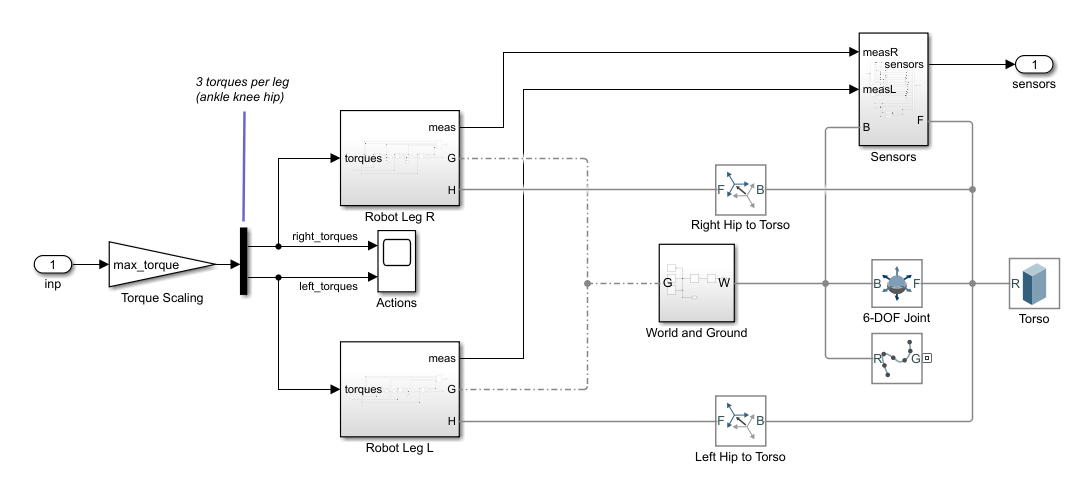
In this model:
In the neutral 0 rad position, both legs are straight and the ankles are flat.
The foot contact is modeled using the Spatial Contact Force (Simscape Multibody) block.
The agent can control 3 individual joints (ankle, knee, and hip) on both legs of the robot by applying joint torques bounded between
[-3,3] N·m. The actual computed action signals are normalized between-1 and 1.
The environment provides the following 29 observations to the agent.
Y (lateral) and Z (vertical) translations of the torso center of mass. The translation in the Z direction is normalized to a similar range as the other observations.
X (forward), Y (lateral), and Z (vertical) translation velocities.
Yaw, pitch, and roll angles of the torso.
Yaw, pitch, and roll angular velocities of the torso.
Angular positions and velocities of the three joints (ankle, knee, hip) on both legs.
Action values from the previous time step.
The episode terminates if either of the following conditions occur.
The robot torso center of mass is less than 0.1 m in the Z direction (the robot falls) or more than 1 m in the either Y direction (the robot moves too far to the side).
The absolute value of either the roll, pitch, or yaw is greater than 0.7854 rad.
The following reward function , which is provided at every time step is inspired by [2].
Here:
is the translation velocity in the X direction (forward toward goal) of the robot.
is the lateral translation displacement of the robot from the target straight line trajectory.
is the normalized vertical translation displacement of the robot center of mass.
is the torque from joint i from the previous time step.
is the sample time of the environment.
is the final simulation time of the environment.
This reward function encourages the agent to move forward by providing a positive reward for positive forward velocity. It also encourages the agent to avoid episode termination by providing a constant reward () at every time step. The other terms in the reward function are penalties for substantial changes in lateral and vertical translations, and for the use of excess control effort.
Create Environment Object
Create the observation specification.
numObs = 29;
obsInfo = rlNumericSpec([numObs 1]);
obsInfo.Name = "observations";Create the action specification.
numAct = 6;
actInfo = rlNumericSpec([numAct 1],LowerLimit=-1,UpperLimit=1);
actInfo.Name = "foot_torque";Create the environment object for the walking robot model.
blk = mdl + "/RL Agent";
env = rlSimulinkEnv(mdl,blk,obsInfo,actInfo);Specify the helper function walkerResetFcn as the reset function for the environment. For more information, see Reset Function for Simulink Environments.
env.ResetFcn = @(in) walkerResetFcn(in, ... upper_leg_length/100, ... lower_leg_length/100, ... h/100);
Create TD3 Agent
This example trains a TD3 RL agent using Evolution Strategy based gradient free optimization technique to learn biped locomotion. The TD3 algorithm is an extension of DDPG with improvements that make it more robust by preventing overestimation of Q values [3].
Two critic networks — TD3 agents learn two critic networks independently and use the minimum value function estimate to update the actor (policy). Doing so avoids overestimation of Q values through the maximum operator in the critic update.
Addition of target policy noise — Adding clipped noise to value functions smooths out Q function values over similar actions. Doing so prevents learning an incorrect sharp peak of noisy value estimate.
Delayed policy and target updates — For a TD3 agent, delaying the actor network update allows more time for the Q function to reduce error (get closer to the required target) before updating the policy. Doing so prevents variance in value estimates and results in a higher quality policy update.
The createTD3Agent helper function perform the following actions.
Create the actor and critic networks.
Specify training options for actor and critic.
Create actor and critic using the networks and options defined.
Configure agent specific options.
Create agent.
Create the TD3 agent.
agent = createTD3Agent(numObs,obsInfo,numAct,actInfo,Ts);
The structure of the actor and critic networks used for this agent are the same as the ones used for DDPG agent. For details on the creating the TD3 agent, see the createTD3Agent helper function. For information on configuring TD3 agent options, see rlTD3AgentOptions.
Specify Evolution Strategy Training Options and Train Agent
Fix the random generator seed for reproducibility.
rng(0,"twister");The ES-RL training requires the following few important train options to be set.
PopulationSize, number of actor that are evaluated in each generation. We choose 20 actorsPercentageEliteSize, This is the size of the surviving elite population which form parent for next generation actors. For this example, set the size of the elite to 50% of the total population.MaxGenerationssets maximum number of generations for population to evolve. For this example MaxGenerations is set to 2000.MaxStepsPerEpisode, sets maximum simulation steps for each run of episode for each actor.TrainEpochssets the number for epochs of gradient based update of the reinforcement learning agent.WeightedMixingset the update method for mean and standard deviation.Display the training progress in the Reinforcement Learning Training Monitor (set the
Plotsoption) and for the command line display (set theVerboseoption).Terminate the training when the agent reaches an average score of 250.
For more information and additional options, see rlEvolutionStrategyTrainingOptions.
maxGeneration = 2000; maxSteps = floor(Tf/Ts); trainOpts = rlEvolutionStrategyTrainingOptions( ... "MaxGeneration", maxGeneration, ... "MaxStepsPerEpisode", maxSteps, ... "ScoreAveragingWindowLength", 10, ... "Plots", "none", ... "StopTrainingCriteria", "GenerationReward", ... "StopTrainingValue", 250, ... "PopulationSize",25, ... "PercentageEliteSize",50, ... "ReturnedPolicy", 'BestPolicy', ... "Verbose",1, ... "SaveAgentCriteria",'none'); trainOpts.TrainEpochs = 50; trainOpts.EvaluationsPerIndividual = 1; trainOpts.PopulationUpdateOptions.UpdateMethod = "WeightedMixing"; trainOpts.PopulationUpdateOptions.InitialStandardDeviation = 0.25; trainOpts.PopulationUpdateOptions.InitialStandardDeviationBias = 0.25;
Train the agent using the trainWithEvolutionStrategy function. This process is computationally intensive and takes several hours to complete. To save time while running this example, load a pretrained agent by setting doTraining to false. To train the agent yourself, set doTraining to true.
doTraining =false; if doTraining % Set UseParallel to false trainOpts.UseParallel = 0; % Train the agent. trainingStats = trainWithEvolutionStrategy(agent,env,trainOpts); else % Load a pretrained agent. load("rlWalkingBipedRobotESTD3.mat","saved_agent") end
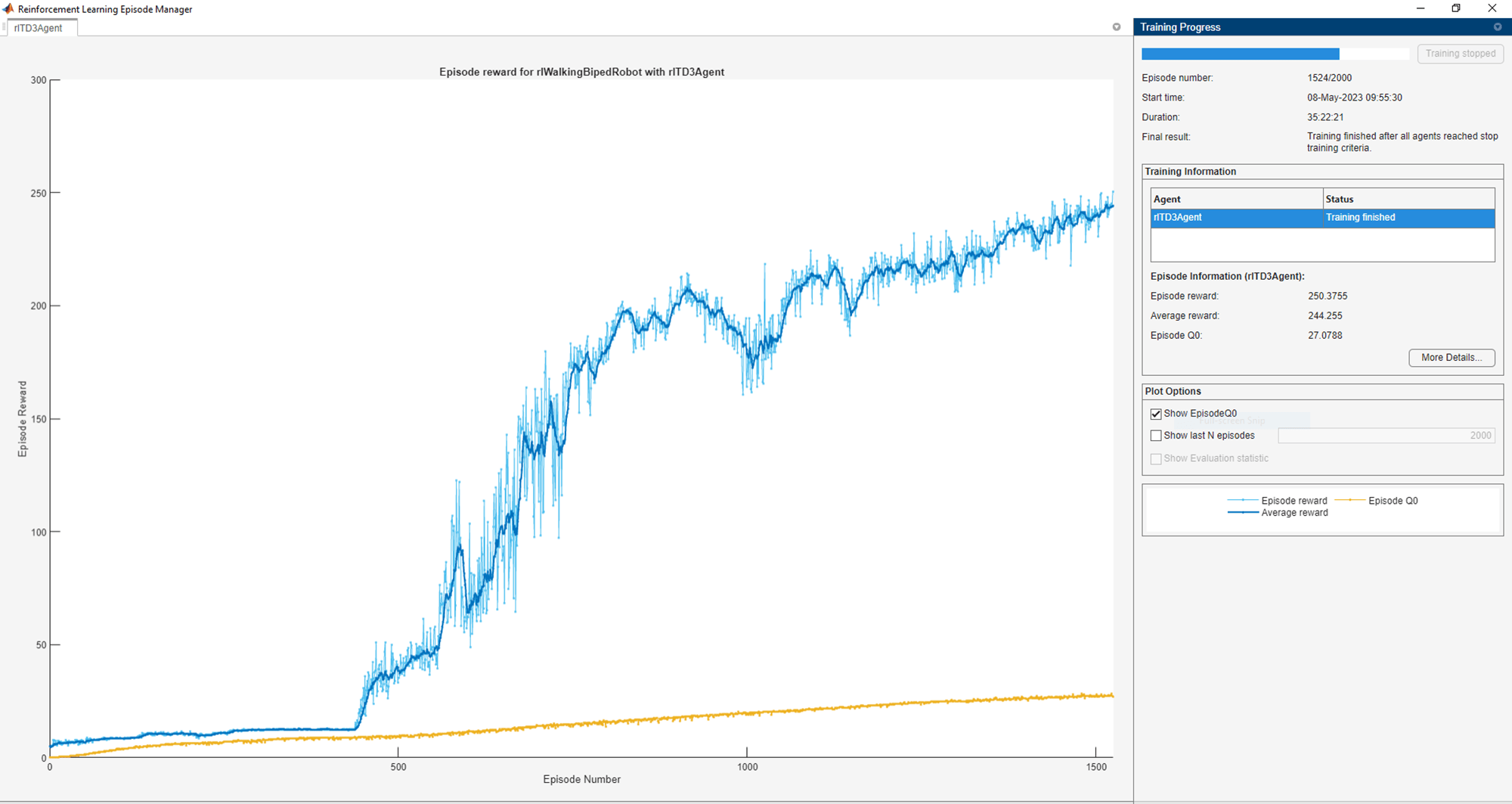
By default, the agent uses a greedy (hence deterministic) policy in simulation. To use the exploratory policy instead, set the UseExplorationPolicy property to true.
To validate the performance of the trained agent, simulate it within the biped robot environment. For more information on agent simulation, see rlSimulationOptions and sim.
simOptions = rlSimulationOptions(MaxSteps=maxSteps); experience = sim(env,saved_agent,simOptions);
Parallel Training Options
Fix the random generator seed for reproducibility.
rng(0,"twister");ES-RL can train the agents in parallel. The actor evaluation over the environment can be parallelized to accelerate the computation and achieve faster training time. To train the agent in parallel set UseParallel option to true. The training curve for ES-RL with parallel train for biped locomotion is shown below, the training time is reduced significantly compared to non-parallel train option.
maxGeneration = 2000; maxSteps = floor(Tf/Ts); trainOpts = rlEvolutionStrategyTrainingOptions( ... "MaxGeneration", maxGeneration, ... "MaxStepsPerEpisode", maxSteps, ... "ScoreAveragingWindowLength", 10, ... "Plots", "none", ... "StopTrainingCriteria", "AverageReward", ... "StopTrainingValue", 350, ... "PopulationSize",25, ... "PercentageEliteSize",50, ... "ReturnedPolicy", 'BestPolicy', ... "Verbose",1, ... "SaveAgentCriteria",'AverageReward'); trainOpts.TrainEpochs = 50; trainOpts.EvaluationsPerIndividual = 1; % Set UseParallel to True for parallel training trainOpts.UseParallel =false; trainOpts.PopulationUpdateOptions.UpdateMethod = "WeightedMixing"; trainOpts.PopulationUpdateOptions.InitialStandardDeviation = 0.25; trainOpts.PopulationUpdateOptions.InitialStandardDeviationBias = 0.25;
To simulate a parallel pretrained agent set doTraining to false. To train the parallel agent yourself, set doTraining to true.
doTraining =false; if doTraining % Train the agent. trainingStats = trainWithEvolutionStrategy(agent,env,trainOpts); else % Load a pretrained agent. load("rlWalkingBipedRobotTD3_ParallelTraining.mat","agent") end
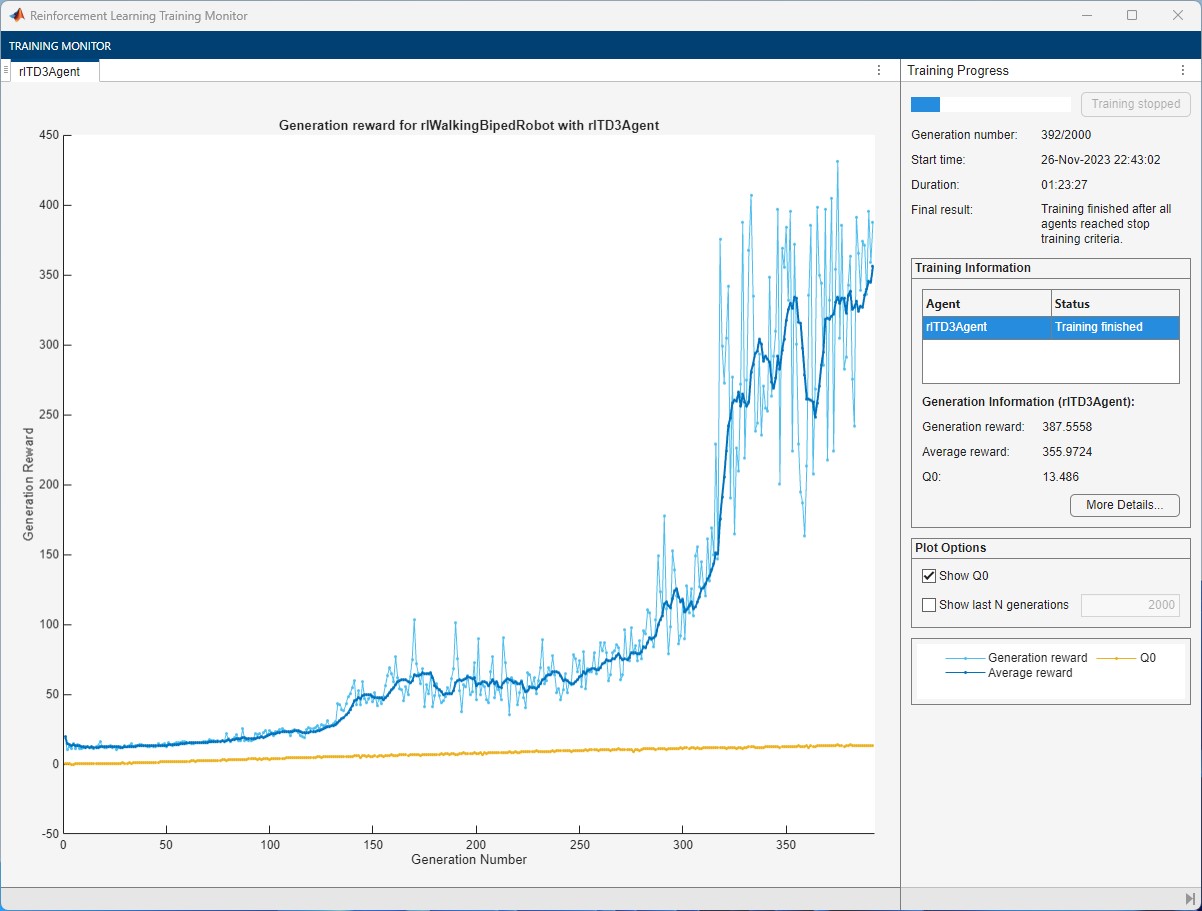
Simulate Parallel-Trained Agent
Fix the random generator seed for reproducibility.
rng(0,"twister");By default, the agent uses a greedy (hence deterministic) policy in simulation. To use the exploratory policy instead, set the UseExplorationPolicy property to true.
To validate the performance of the trained agent, simulate it within the biped robot environment. For more information on agent simulation, see rlSimulationOptions and sim.
simOptions = rlSimulationOptions(MaxSteps=maxSteps); experience = sim(env,agent,simOptions);

Display the cumulative reward over the simulation episode.
sum(experience.Reward.Data)
Training the agent for longer allows the critics to steadily improve their estimates and potentially converge to the true Q-value function.
Restore the random number stream using the information stored in previousRngState.
rng(previousRngState);
References
[1] Lillicrap, Timothy P., Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. "Continuous Control with Deep Reinforcement Learning." Preprint, submitted July 5, 2019. https://arxiv.org/abs/1509.02971.
[2] Heess, Nicolas, Dhruva TB, Srinivasan Sriram, Jay Lemmon, Josh Merel, Greg Wayne, Yuval Tassa, et al. "Emergence of Locomotion Behaviours in Rich Environments." Preprint, submitted July 10, 2017. https://arxiv.org/abs/1707.02286.
[3] Fujimoto, Scott, Herke van Hoof, and David Meger. "Addressing Function Approximation Error in Actor-Critic Methods." Preprint, submitted October 22, 2018. https://arxiv.org/abs/1802.09477
[4] Pourchot, Aloïs, and Olivier Sigaud. "CEM-RL: Combining evolutionary and gradient-based methods for policy search." https://arxiv.org/abs/1810.01222
[5] Khadka, Shauharda, and Kagan Tumer. "Evolution-guided policy gradient in reinforcement learning." Advances in Neural Information Processing Systems 31 (2018). https://arxiv.org/abs/1805.07917