rlTD3Agent
Twin-delayed deep deterministic (TD3) policy gradient reinforcement learning agent
Description
The twin-delayed deep deterministic (TD3) policy gradient algorithm is an off-policy actor-critic method for environments with a continuous action-space. A TD3 agent learns a deterministic policy while also using two critics to estimate the value of the optimal policy. It features a target actor and target critics as well as an experience buffer. TD3 agents supports offline training (training from saved data, without an environment).
Use rlTD3Agent to create one of the following types of agents.
Twin-delayed deep deterministic policy gradient (TD3) agent with two Q-value functions. This agent prevents overestimation of the value function by learning two Q value functions and using the minimum values for policy updates.
Delayed deep deterministic policy gradient (delayed DDPG) agent with a single Q value function. This agent is a DDPG agent with target policy smoothing and delayed policy and target updates.
For more information, see Twin-Delayed Deep Deterministic (TD3) Policy Gradient Agent. For more information on the different types of reinforcement learning agents, see Reinforcement Learning Agents.
Creation
Syntax
Description
Create Agent from Observation and Action Specifications
agent = rlTD3Agent(observationInfo,actionInfo)observationInfo and the action specification
actionInfo. The ObservationInfo and
ActionInfo properties of agent are set to
the observationInfo and actionInfo input
arguments, respectively.
agent = rlTD3Agent(observationInfo,actionInfo,initOpts)initOpts object. For more information on
the initialization options, see rlAgentInitializationOptions.
Create Agent from Actor and Critic
Specify Agent Options
agent = rlTD3Agent(___,agentOptions)AgentOptions
property to the agentOptions input argument. Use this syntax after
any of the input arguments in the previous syntaxes.
Input Arguments
Properties
Object Functions
train | Train reinforcement learning agents within a specified environment |
sim | Simulate trained reinforcement learning agents within specified environment |
getAction | Obtain action from agent, actor, or policy object given environment observations |
getActor | Extract actor from reinforcement learning agent |
setActor | Set actor of reinforcement learning agent |
getCritic | Extract critic from reinforcement learning agent |
setCritic | Set critic of reinforcement learning agent |
generatePolicyFunction | Generate MATLAB function that evaluates policy of an agent or policy object |
Examples
Create an environment with a continuous action space, and obtain its observation and action specifications. For this example, load the environment used in the example Compare DDPG Agent to LQR Controller. The observation from the environment is a vector containing the position and velocity of a mass. The action is a scalar representing a force, applied to the mass, ranging continuously from -2 to 2 Newton.
env = rlPredefinedEnv("DoubleIntegrator-Continuous");Extract the environment observation and action specifications.
obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
The agent creation function initializes the actor and critic networks randomly. Ensure reproducibility of the section by fixing the seed of the random generator.
rng(0)
Create a TD3 agent from the environment observation and action specifications.
agent = rlTD3Agent(obsInfo,actInfo);
To check your agent, use the getAction function to return the action from a batch of 5 random observations.
obs = rand([obsInfo.Dimension 5]);
act = getAction(agent,{obs});Display the fourth element of the batch.
act{1}(4)ans = 0.0154
You can now test and train the agent within the environment. You can also use getActor and getCritic to extract the actor and critic, respectively, and getModel to extract the approximator model (by default a deep neural network) from the actor or critic.
Create an environment with a continuous action space and obtain its observation and action specifications. For this example, load the environment used in the example Train DDPG Agent with Custom Networks Using Image Observation. This environment has two observations: a 50-by-50 grayscale image and a scalar (the angular velocity of the pendulum). The action is a scalar representing a torque ranging continuously from -2 to 2 Nm.
% Load predefined environment env = rlPredefinedEnv("SimplePendulumWithImage-Continuous"); % Obtain observation and action specifications obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
Create an agent initialization option object, specifying that each hidden fully connected layer in the network must have 128 neurons (instead of the default number, 256).
initOpts = rlAgentInitializationOptions(NumHiddenUnit=128);
The agent creation function initializes the actor and critic networks randomly. Ensure reproducibility of the section by fixing the seed of the random generator.
rng(0)
Create a DDPG agent from the environment observation and action specifications.
agent = rlTD3Agent(obsInfo,actInfo,initOpts);
Extract the deep neural networks from the actor.
actorNet = getModel(getActor(agent));
Extract the deep neural networks from the two critics. Note that getModel(critics) only returns the first critic network.
critics = getCritic(agent); criticNet1 = getModel(critics(1)); criticNet2 = getModel(critics(2));
To verify that each hidden fully connected layer has 128 neurons, you can display the layers on the MATLAB® command window,
criticNet1.Layers
or visualize the structure interactively using analyzeNetwork.
analyzeNetwork(criticNet1)
Plot the networks of the actor and of the second critic, and display the number of weights.
plot(actorNet)
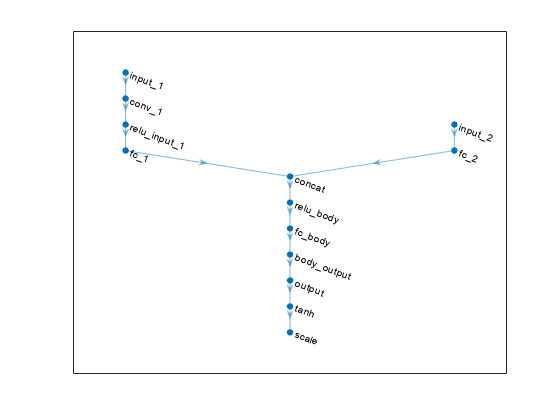
summary(actorNet)
Initialized: true
Number of learnables: 18.9M
Inputs:
1 'input_1' 50×50×1 images
2 'input_2' 1 features
plot(criticNet2)
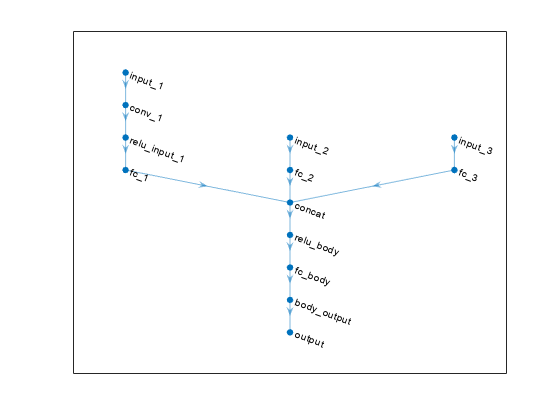
summary(criticNet2)
Initialized: true
Number of learnables: 18.9M
Inputs:
1 'input_1' 50×50×1 images
2 'input_2' 1 features
3 'input_3' 1 features
To check your agent, use the getAction function to return the action batch from a batch of 5 random observations.
obs1 = rand([obsInfo(1).Dimension 5]);
obs2 = rand([obsInfo(2).Dimension 5]);
act = getAction(agent,{obs1, obs2});Display the fifth element of the batch.
act{1}(5)ans = -0.0226
You can now test and train the agent within the environment.
Create an environment with a continuous action space and obtain its observation and action specifications. For this example, load the environment used in the example Compare DDPG Agent to LQR Controller. The observation from the environment is a vector containing the position and velocity of a mass. The action is a scalar representing a force ranging continuously from -2 to 2 Newton.
env = rlPredefinedEnv("DoubleIntegrator-Continuous");
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);TD3 agents use two Q-value function critics. A Q-value function critic takes the current observation and an action as inputs and returns a single scalar as output (the estimated discounted cumulative long-term reward for taking the action from the state corresponding to the current observation, and following the policy thereafter).
To model the parameterized Q-value function within the critics, use a neural network with two input layers (one for the observation channel, as specified by obsInfo, and the other for the action channel, as specified by actInfo) and one output layer (which returns the scalar value). Note that prod(obsInfo.Dimension) and prod(actInfo.Dimension) return the number of dimensions of the observation and action spaces, respectively, regardless of whether they are arranged as row vectors, column vectors, or matrices.
Define each network path as an array of layer objects. Assign names to the input and output layers of each path, so you can connect them.
% Observation path obsPath = [ featureInputLayer(prod(obsInfo.Dimension),Name="obsPathInLyr") fullyConnectedLayer(32) reluLayer fullyConnectedLayer(16,Name="obsPathOutLyr") ]; % Action path actPath = [ featureInputLayer(prod(actInfo.Dimension),Name="actPathInLyr") fullyConnectedLayer(32) reluLayer fullyConnectedLayer(16,Name="actPathOutLyr") ]; % Common path commonPath = [ concatenationLayer(1,2,Name="concat") reluLayer fullyConnectedLayer(1) ]; % Create dlnetwork object and add layers. criticNet = dlnetwork; criticNet = addLayers(criticNet,obsPath); criticNet = addLayers(criticNet,actPath); criticNet = addLayers(criticNet,commonPath); % Connect layers criticNet = connectLayers(criticNet,"obsPathOutLyr","concat/in1"); criticNet = connectLayers(criticNet,"actPathOutLyr","concat/in2");
To initialize the network weights differently for the two critics, create two different dlnetwork objects. You must do this because the agent constructor function does not accept two identical critics.
criticNet1 = initialize(criticNet); criticNet2 = initialize(criticNet);
Display the number of weights.
summary(criticNet1)
Initialized: true
Number of learnables: 1.2k
Inputs:
1 'obsPathInLyr' 2 features
2 'actPathInLyr' 1 features
Create the two critics using the two networks with different weights. Alternatively, if you use exactly the same network with the same weights, you must explicitly initialize the network each time (to make sure weights are initialized differently) before passing it to rlQValueFunction. To do so, use initialize.
critic1 = rlQValueFunction(criticNet1,obsInfo,actInfo); critic2 = rlQValueFunction(criticNet2,obsInfo,actInfo);
For more information about Q-value function approximators, using rlQValueFunction.
Check the critics with a batch of 5 random observation and action inputs.
obs = rand([obsInfo.Dimension 5]);
act = rand([actInfo.Dimension 5]);
val = getValue(critic1,{obs},{act})val = 1×5 single row vector
-0.1228 -0.0543 -0.0087 -0.0883 -0.2600
val = getValue(critic2,{obs},{act})val = 1×5 single row vector
-0.3008 -0.3237 -0.1304 -0.2995 -0.3389
TD3 agents use a parameterized deterministic policy over continuous action spaces, which is learned by a continuous deterministic actor. This actor takes the current observation as input and returns as output an action that is a deterministic function of the observation.
To model the parameterized policy within the actor, use a neural network with one input layer (which receives the content of the environment observation channel, as specified by obsInfo) and one output layer (which returns the action to the environment action channel, as specified by actInfo).
Define the network as an array of layer objects.
actorNet = [
featureInputLayer(prod(obsInfo.Dimension))
fullyConnectedLayer(400)
reluLayer
fullyConnectedLayer(300)
reluLayer
fullyConnectedLayer(prod(actInfo.Dimension))
tanhLayer
];Convert to a dlnetwork object, initialize it, and display the number of weights.
actorNet = dlnetwork(actorNet); actorNet = initialize(actorNet); summary(actorNet)
Initialized: true
Number of learnables: 121.8k
Inputs:
1 'input' 2 features
Create the actor using actorNet, and the environment specification objects.
actor = rlContinuousDeterministicActor(actorNet,obsInfo,actInfo);
For more information about continuous deterministic actor approximators, see rlContinuousDeterministicActor.
Check the actor with a random observation input.
getAction(actor,{rand(obsInfo.Dimension)})ans = 1×1 cell array
{[-0.0235]}
Specify training options for the critics.
criticOptions = rlOptimizerOptions( ... Optimizer="adam", ... LearnRate=1e-3, ... GradientThreshold=1, ... L2RegularizationFactor=2e-4);
Specify training options for the actor.
actorOptions = rlOptimizerOptions( ... Optimizer="adam", ... LearnRate=1e-3, ... GradientThreshold=1, ... L2RegularizationFactor=1e-5);
Specify agent options, including training options for actor and critics.
agentOptions = rlTD3AgentOptions; agentOptions.DiscountFactor = 0.99; agentOptions.TargetSmoothFactor = 5e-3; agentOptions.TargetPolicySmoothModel.Variance = 0.2; agentOptions.TargetPolicySmoothModel.LowerLimit = -0.5; agentOptions.TargetPolicySmoothModel.UpperLimit = 0.5; agentOptions.CriticOptimizerOptions = criticOptions; agentOptions.ActorOptimizerOptions = actorOptions;
Create TD3 agent using actor, critics, and options.
agent = rlTD3Agent(actor,[critic1 critic2],agentOptions);
You can also create an rlTD3Agent object with a single critic. In this case, the object represents a DDPG agent with target policy smoothing and delayed policy and target updates.
delayedDDPGAgent = rlTD3Agent(actor,critic1,agentOptions);
To check your agents, use the getAction function to return the action batch for from a batch of 5 random observations.
Check the TD3 agent.
obs = rand([obsInfo.Dimension 5]);
act = getAction(agent,{obs})act = 1×1 cell array
{1×1×5 double}
Display the fourth element in the batch.
act{1}(4)ans = -0.0163
Check the delayed DDPG agent.
act = getAction(delayedDDPGAgent,{obs})act = 1×1 cell array
{1×1×5 double}
Display the fourth element in the batch.
act{1}(4)ans = -0.0163
You can now test and train either agent within the environment.
For this example, load the environment used in the example Compare DDPG Agent to LQR Controller. The observation from the environment is a vector containing the position and velocity of a mass. The action is a scalar representing a force ranging continuously from -2 to 2 Newton.
env = rlPredefinedEnv("DoubleIntegrator-Continuous");Obtain observation and action specifications.
obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
TD3 agents use two Q-value function critics. To model the parameterized Q-value function within the critics, use a recurrent neural network with two input layers (one for the observation channel, as specified by obsInfo, and the other for the action channel, as specified by actInfo) and one output layer (which returns the scalar value).
Define each network path as an array of layer objects. To create a recurrent network, use a sequenceInputLayer as the input layer and include at least one lstmLayer.
% Define observation path. obsPath = [ sequenceInputLayer(prod(obsInfo.Dimension),Name="obsInLyr") fullyConnectedLayer(400) reluLayer fullyConnectedLayer(300,Name="obsOutLyr") ]; % Define action path. actPath = [ sequenceInputLayer(prod(actInfo.Dimension),Name="actInLyr") fullyConnectedLayer(300,Name="actOutLyr") ]; % Define common path. commonPath = [ concatenationLayer(1,2,Name="cat") reluLayer lstmLayer(16); fullyConnectedLayer(1) ]; % Create dlnetwork object and add layers. criticNet = dlnetwork; criticNet = addLayers(criticNet,obsPath); criticNet = addLayers(criticNet,actPath); criticNet = addLayers(criticNet,commonPath); % Connect paths. criticNet = connectLayers(criticNet,"obsOutLyr","cat/in1"); criticNet = connectLayers(criticNet,"actOutLyr","cat/in2");
To initialize the network weights differently for the two critics, create two different dlnetwork objects. You must do this because the agent constructor function does not accept two identical critics.
criticNet1 = initialize(criticNet); criticNet2 = initialize(criticNet);
Display the number of weights.
summary(criticNet1)
Initialized: true
Number of learnables: 161.6k
Inputs:
1 'obsInLyr' Sequence input with 2 channels
2 'actInLyr' Sequence input with 1 channels
Create the critics using the same network structure. The TD3 agent initializes the two networks using different default parameters.
critic1 = rlQValueFunction(criticNet1,obsInfo,actInfo); critic2 = rlQValueFunction(criticNet2,obsInfo,actInfo);
Check the critics with a random observation and action input.
getValue(critic1,{rand(obsInfo.Dimension)},{rand(actInfo.Dimension)})ans = single
-0.0060
getValue(critic2,{rand(obsInfo.Dimension)},{rand(actInfo.Dimension)})ans = single
0.0481
Because the critics have a recurrent network, the (continuous deterministic) actor must have a recurrent network as approximation model too. The network that models the parameterized policy, must take the observation and return the action.
Define the network as an array of layer objects.
actorNet = [
sequenceInputLayer(prod(obsInfo.Dimension))
fullyConnectedLayer(400)
lstmLayer(8)
reluLayer
fullyConnectedLayer(300)
reluLayer
fullyConnectedLayer(prod(actInfo.Dimension))
tanhLayer
];Convert to dlnetwork object, initialize it, and display the number of weights.
actorNet = dlnetwork(actorNet); actorNet = initialize(actorNet); summary(actorNet)
Initialized: true
Number of learnables: 17.3k
Inputs:
1 'sequenceinput' Sequence input with 2 channels
Create the actor using actorNet, and the environment specification objects.
actor = rlContinuousDeterministicActor(actorNet,obsInfo,actInfo);
Check the actor with a random observation input.
getAction(actor,{rand(obsInfo.Dimension)})ans = 1×1 cell array
{[0.0014]}
Specify training options for the critics.
criticOptions = rlOptimizerOptions( ... Optimizer="adam", ... LearnRate=1e-3, ... GradientThreshold=1, ... L2RegularizationFactor=2e-4);
Specify training options for the actor.
actorOptions = rlOptimizerOptions( ... Optimizer="adam", ... LearnRate=1e-3, ... GradientThreshold=1, ... L2RegularizationFactor=1e-5);
Specify agent options, including training options for actor and critics. To use a TD3 agent with recurrent neural networks, you must specify a SequenceLength greater than 1.
agentOptions = rlTD3AgentOptions; agentOptions.DiscountFactor = 0.99; agentOptions.SequenceLength = 32; agentOptions.TargetSmoothFactor = 5e-3; agentOptions.TargetPolicySmoothModel.Variance = 0.2; agentOptions.TargetPolicySmoothModel.LowerLimit = -0.5; agentOptions.TargetPolicySmoothModel.UpperLimit = 0.5; agentOptions.CriticOptimizerOptions = criticOptions; agentOptions.ActorOptimizerOptions = actorOptions;
Create TD3 agent using actor, critics, and options.
agent = rlTD3Agent(actor,[critic1 critic2],agentOptions);
You can also create an rlTD3Agent object with a single critic. In this case, the object represents a DDPG agent with target policy smoothing and delayed policy and target updates.
delayedDDPGAgent = rlTD3Agent(actor,critic1,agentOptions);
To check your agents, use the getAction function to return the action from a random observation.
getAction(agent,{rand(obsInfo.Dimension)})ans = 1×1 cell array
{[0.0018]}
getAction(delayedDDPGAgent,{rand(obsInfo.Dimension)})ans = 1×1 cell array
{[0.0015]}
To evaluate the agent using sequential observations, use the sequence length (time) dimension. For example, obtain actions for a sequence of 9 observations.
obs = rand([obsInfo.Dimension 1 9]);
[action,state] = getAction(agent,{obs});Display the action corresponding to the seventh element of the observation.
action = action{1};
action(1,1,1,7)ans = -0.0034
You can now test and train the agent within the environment.
Version History
Introduced in R2020a
See Also
Apps
Functions
getAction|getActor|getCritic|getModel|generatePolicyFunction|generatePolicyBlock|getActionInfo|getObservationInfo
Objects
rlTD3AgentOptions|rlAgentInitializationOptions|rlQValueFunction|rlContinuousDeterministicActor|rlContinuousGaussianActor|rlDDPGAgent|rlSACAgent|rlPPOAgent
Blocks
Topics
- Train TD3 Agent for PMSM Control
- Identify Vulnerabilities in DC Microgrids
- Train Biped Robot to Walk Using Reinforcement Learning Agents
- Train Reinforcement Learning Agent Offline to Control Quanser QUBE Pendulum
- Twin-Delayed Deep Deterministic (TD3) Policy Gradient Agent
- Reinforcement Learning Agents
- Train Reinforcement Learning Agents