logp
Log unconditional probability density for naive Bayes classifier
Description
lp = logp(Mdl,tbl)lp) of the observations
(rows) in tbl using the naive Bayes model
Mdl. You can use lp to identify
outliers in the training data.
Examples
Compute the unconditional probability densities of the in-sample observations of a naive Bayes classifier model.
Load the fisheriris data set. Create X as a numeric matrix that contains four measurements for 150 irises. Create Y as a cell array of character vectors that contains the corresponding iris species.
load fisheriris
X = meas;
Y = species;Train a naive Bayes classifier using the predictors X and class labels Y. A recommended practice is to specify the class names. fitcnb assumes that each predictor is conditionally and normally distributed.
Mdl = fitcnb(X,Y,'ClassNames',{'setosa','versicolor','virginica'})
Mdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
DistributionNames: {'normal' 'normal' 'normal' 'normal'}
DistributionParameters: {3×4 cell}
Properties, Methods
Mdl is a trained ClassificationNaiveBayes classifier.
Compute the unconditional probability densities of the in-sample observations.
lp = logp(Mdl,X);
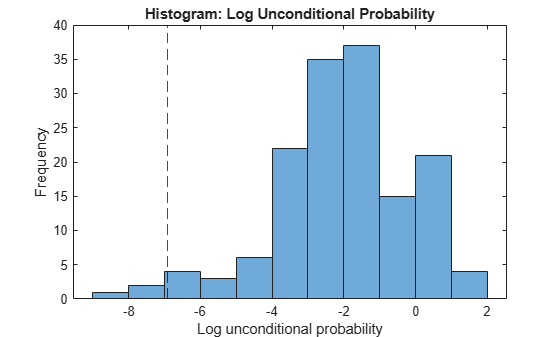
Identify indices of observations that have very small or very large log unconditional probabilities (ind). Display lower (L) and upper (U) thresholds used by the outlier detection method.
[TF,L,U] = isoutlier(lp); L
L = -6.9222
U
U = 3.0323
ind = find(TF)
ind = 4×1
61
118
119
132
Display the values of the outlier unconditional probability densities.
lp(ind)
ans = 4×1
-7.8995
-8.4765
-6.9854
-7.8969
All the outliers are smaller than the lower outlier detection threshold.
Plot the unconditional probability densities.
histogram(lp) hold on xline(L,'k--') hold off xlabel('Log unconditional probability') ylabel('Frequency') title('Histogram: Log Unconditional Probability')
Input Arguments
More About
Version History
Introduced in R2014b