rangesearch
Find all neighbors within specified distance using searcher object
Description
Idx = rangesearch(Mdl,Y,r)Mdl.X within radius r of each point (i.e.,
row or observation) in the query data Y using an exhaustive
search or a Kd-tree. rangesearch returns
Idx, which is a column vector of the indices of
Mdl.X within r units.
Idx = rangesearch(Mdl,Y,r,Name,Value)Mdl.X within radius
r of each observation in Y with additional
options specified by one or more Name,Value pair arguments. For
example, you can specify to use a different distance metric than is stored in
Mdl.Distance or a different distance metric parameter than is
stored in Mdl.DistParameter.
[
additionally returns the matrix Idx,D]
= rangesearch(___)D using any of the input
arguments in the previous syntaxes. D contains the distances
between the observations in Mdl.X within radius
r of each observation in Y. By default,
the function arranges the columns of D in ascending order by
closeness, with respect to the distance metric.
Examples
rangesearch accepts ExhaustiveSearcher or KDTreeSearcher model objects to search the training data for the nearest neighbors to the query data. An ExhaustiveSearcher model invokes the exhaustive searcher algorithm, and a KDTreeSearcher model defines a Kd-tree, which rangesearch uses to search for nearest neighbors.
Load Fisher's iris data set. Randomly reserve five observations from the data for query data. Focus on the petal dimensions.
load fisheriris rng(1); % For reproducibility n = size(meas,1); idx = randsample(n,5); X = meas(~ismember(1:n,idx),3:4); % Training data Y = meas(idx,3:4); % Query data
Grow a default two-dimensional Kd-tree.
MdlKDT = KDTreeSearcher(X)
MdlKDT =
KDTreeSearcher with properties:
BucketSize: 50
Distance: 'euclidean'
DistParameter: []
X: [145×2 double]
MdlKDT is a KDTreeSearcher model object. You can alter its writable properties using dot notation.
Prepare an exhaustive nearest neighbor searcher.
MdlES = ExhaustiveSearcher(X)
MdlES =
ExhaustiveSearcher with properties:
Distance: 'euclidean'
DistParameter: []
X: [145×2 double]
MdlES is an ExhaustiveSearcher model object. It contains the options, such as the distance metric, to use to find nearest neighbors.
Alternatively, you can grow a Kd-tree or prepare an exhaustive nearest neighbor searcher using createns.
Search training data for the nearest neighbor indices that correspond to each query observation that are within a 0.5 cm radius. Conduct both types of searches and use the default settings.
r = 0.15; % Search radius
IdxKDT = rangesearch(MdlKDT,Y,r);
IdxES = rangesearch(MdlES,Y,r);
[IdxKDT IdxES]ans=5×2 cell array
{[ 1 4 8 27 32 45 47 2 35 37 41 6 17 12 36 3 7 10 26 33 38 46 39 40 19 9 31]} {[ 1 4 8 27 32 45 47 2 35 37 41 6 17 12 36 3 7 10 26 33 38 46 39 40 19 9 31]}
{[ 13]} {[ 13]}
{[6 17 39 40 1 4 8 27 32 45 47 19 2 35 37 41 16 3 7 10 26 33 38 46 15 21 30]} {[6 17 39 40 1 4 8 27 32 45 47 19 2 35 37 41 16 3 7 10 26 33 38 46 15 21 30]}
{[ 64 66]} {[ 64 66]}
{1×0 double } {1×0 double }
IdxKDT and IdxES are cell arrays of vectors corresponding to the indices of X that are within 0.15 cm of the observations in Y. Each row of the index matrices corresponds to a query observation.
Compare the results between the methods.
cellfun(@isequal,IdxKDT,IdxES)
ans = 5×1 logical array
1
1
1
1
1
In this case, the results are the same.
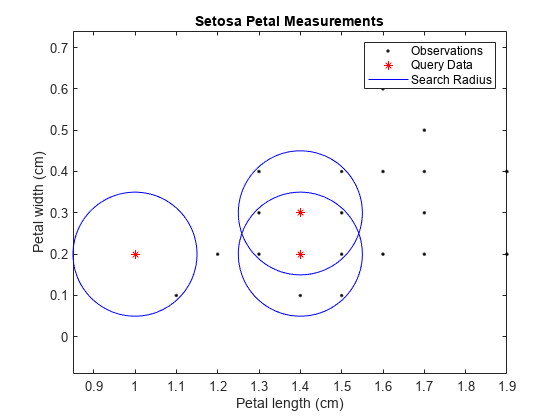
Plot the results for the setosa irises.
setosaIdx = strcmp(species(~ismember(1:n,idx)),'setosa'); XSetosa = X(setosaIdx,:); ySetosaIdx = strcmp(species(idx),'setosa'); YSetosa = Y(ySetosaIdx,:); figure; plot(XSetosa(:,1),XSetosa(:,2),'.k'); hold on; plot(YSetosa(:,1),YSetosa(:,2),'*r'); for j = 1:sum(ySetosaIdx) c = YSetosa(j,:); circleFun = @(x1,x2)r^2 - (x1 - c(1)).^2 - (x2 - c(2)).^2; fimplicit(circleFun,[c(1) + [-1 1]*r, c(2) + [-1 1]*r],'b-') end xlabel 'Petal length (cm)'; ylabel 'Petal width (cm)'; title 'Setosa Petal Measurements'; legend('Observations','Query Data','Search Radius'); axis equal hold off
Load Fisher's iris data set.
load fisheririsRemove five irises randomly from the predictor data to use as a query set.
rng(1); % For reproducibility n = size(meas,1); % Sample size qIdx = randsample(n,5); % Indices of query data X = meas(~ismember(1:n,qIdx),:); Y = meas(qIdx,:);
Prepare a default exhaustive nearest neighbor searcher.
Mdl = ExhaustiveSearcher(X)
Mdl =
ExhaustiveSearcher with properties:
Distance: 'euclidean'
DistParameter: []
X: [145×4 double]
Mdl is an ExhaustiveSearcher model.
Find the indices of the training data (X) that are within 0.15 cm of each point in the query data (Y). Specify that the distances are with respect to the Mahalanobis metric.
r = 1; Idx = rangesearch(Mdl,Y,r,'Distance','mahalanobis')
Idx=5×1 cell array
{[26 38 7 17 47 4 27 46 25 10 39 20 21 2 33]}
{[ 6 21 25 4 19]}
{[ 1 34 33 22 24 2]}
{[ 84]}
{[ 69]}
Idx{3}ans = 1×6
1 34 33 22 24 2
Each cell of Idx corresponds to a query data observation and contains in X a vector of indices of the neighbors within 0.15cm of the query data. rangesearch arranges the indices in ascending order by distance. For example, using the Mahalanobis distance, the second nearest neighbor of Y(3,:) is X(34,:).
Load Fisher's iris data set.
load fisheririsRemove five irises randomly from the predictor data to use as a query set.
rng(4); % For reproducibility n = size(meas,1); % Sample size qIdx = randsample(n,5); % Indices of query data X = meas(~ismember(1:n,qIdx),:); Y = meas(qIdx,:);
Grow a four-dimensional Kd-tree using the training data. Specify to use the Minkowski distance for finding nearest neighbors.
Mdl = KDTreeSearcher(X);
Mdl is a KDTreeSearcher model. By default, the distance metric for finding nearest neighbors is the Euclidean metric.
Find the indices of the training data (X) that are within 0.5 cm from each point in the query data (Y).
r = 0.5; [Idx,D] = rangesearch(Mdl,Y,r);
Idx and D are five-element cell arrays of vectors. The vector values in Idx are the indices in X. The X indices represent the observations that are within 0.5 cm of the query data, Y. D contains the distances that correspond to the observations.
Display the results for query observation 3.
Idx{3}ans = 1×2
127 122
D{3}ans = 1×2
0.2646 0.4359
The closest observation to Y(3,:) is X(127,:), which is 0.2646 cm away. The next closest is X(122,:), which is 0.4359 cm away. All other observations are greater than 0.5 cm away from Y(5,:).
Input Arguments
Name-Value Arguments
Output Arguments
Tips
knnsearch finds the k
(positive integer) points in Mdl.X that are
k-nearest for each Y point. In contrast,
rangesearch finds all the points in Mdl.X
that are within distance r (positive scalar) of each
Y point.
Alternative Functionality
rangesearch is an object function that requires an ExhaustiveSearcher or a KDTreeSearcher model object, query data, and a distance. Under equivalent
conditions, rangesearch returns the same results as rangesearch when you specify the name-value pair argument
'NSMethod','exhaustive' or
'NSMethod','kdtree', respectively.
Extended Capabilities
Version History
Introduced in R2011b