Verify and Validate Machine Learning Models Using Model-Based Design
This example shows how to use Simulink® to verify and validate machine learning models. Verified machine learning is the goal of designing systems that have strong, ideally provable, assurances of correctness with respect to mathematically specified requirements [1]. Because machine learning provides the best results for many tasks, deploying machine learning models in production is important for safety-critical applications. However, doing so can be challenging because:
You must verify the system for correctness and then validate it in production.
You must certify the system based on industry-approved rules for specific applications, such as medical, aerospace, and defense. For more information about certification requirements, see More About Compliance with Industry Standards.
System design for machine learning models introduces new tasks in a typical Model-Based Design workflow, as demonstrated in this example:
Prepare data for training machine learning models. You might need to clean and prepare your data before using it to train a machine learning model. If enough data is not available, you need to use simulation-generated data.
Train machine learning models. During model training, you might need to tune your design or train and compare several machine learning models.
Verify and validate the models. If you are integrating the machine learning component into a large and complex system, you might need to perform component-level and system-level simulations and tests. You also need to measure the memory footprint and speed of the machine learning algorithm to assess its efficiency in the embedded environment.
Prepare Data
This example builds models for the acoustic scene classification (ASC) task, which classifies environments from the sounds they produce. ASC is a generic multiclass classification problem that is foundational for context awareness in devices, robots, and other applications [2].
Download Data Set
To run the example, you must first download the data set [2]. The size of the full data set is approximately 15.5 GB. Depending on your machine and internet connection, downloading the data can take about four hours.
The tempdir command creates a temporary folder, which might be autodeleted. To retain the downloaded data set, change the temporary folder (downloadFolder) to a local directory.
downloadFolder = tempdir; dataset_asc = fullfile(downloadFolder,"TUT-acoustic-scenes-2017"); if ~datasetExists(dataset_asc) disp("Downloading TUT-acoustic-scenes-2017 (15.5 GB) ...") HelperDownload_TUT_acoustic_scenes_2017(dataset_asc); end
Downloading TUT-acoustic-scenes-2017 (15.5 GB) ...
Downloading development set ... Downloading 1 of 13 ... complete. Downloading 2 of 13 ... complete. Downloading 3 of 13 ... complete. Downloading 4 of 13 ... complete. Downloading 5 of 13 ... complete. Downloading 6 of 13 ... complete. Downloading 7 of 13 ... complete. Downloading 8 of 13 ... complete. Downloading 9 of 13 ... complete. Downloading 10 of 13 ... complete. Downloading 11 of 13 ... complete. Downloading 12 of 13 ... complete. Downloading 13 of 13 ... complete. Download of development set complete. Time elapsed: 105 minutes Downloading evaluation set ... Downloading 1 of 6 ... complete. Downloading 2 of 6 ... complete. Downloading 3 of 6 ... complete. Downloading 4 of 6 ... complete. Downloading 5 of 6 ... complete. Downloading 6 of 6 ... complete. Download of evaluation set complete. Time elapsed: 35 minutes
Load Metadata
Create a table from the training set metadata. Name the table variables FileName, AcousticScene, and SpecificLocation.
trainMetaData = readtable(fullfile(dataset_asc,"TUT-acoustic-scenes-2017-development","meta"), ... Delimiter={'\t'}, ... ReadVariableNames=false); trainMetaData.Properties.VariableNames = ["FileName","AcousticScene","SpecificLocation"]; head(trainMetaData)
FileName AcousticScene SpecificLocation
__________________________ _____________ ________________
{'audio/b020_90_100.wav' } {'beach'} {'b020'}
{'audio/b020_110_120.wav'} {'beach'} {'b020'}
{'audio/b020_100_110.wav'} {'beach'} {'b020'}
{'audio/b020_40_50.wav' } {'beach'} {'b020'}
{'audio/b020_50_60.wav' } {'beach'} {'b020'}
{'audio/b020_30_40.wav' } {'beach'} {'b020'}
{'audio/b020_160_170.wav'} {'beach'} {'b020'}
{'audio/b020_170_180.wav'} {'beach'} {'b020'}
Determine a table from the test set metadata. Name the table variables FileName, AcousticScene, and SpecificLocation.
testMetaData = readtable(fullfile(dataset_asc,"TUT-acoustic-scenes-2017-evaluation","meta"), ... Delimiter={'\t'}, ... ReadVariableNames=false); testMetaData.Properties.VariableNames = ["FileName","AcousticScene","SpecificLocation"]; head(testMetaData)
FileName AcousticScene SpecificLocation
__________________ _____________ ________________
{'audio/1245.wav'} {'beach'} {'b174'}
{'audio/1456.wav'} {'beach'} {'b174'}
{'audio/1318.wav'} {'beach'} {'b174'}
{'audio/967.wav' } {'beach'} {'b174'}
{'audio/203.wav' } {'beach'} {'b174'}
{'audio/777.wav' } {'beach'} {'b174'}
{'audio/231.wav' } {'beach'} {'b174'}
{'audio/768.wav' } {'beach'} {'b174'}
Check if the training and test sets have common recording locations.
sharedRecordingLocations = intersect(testMetaData.SpecificLocation,trainMetaData.SpecificLocation);
disp("Number of specific recording locations in both training and test sets = " + numel(sharedRecordingLocations))Number of specific recording locations in both training and test sets = 0
The specific recording locations in the test set do not intersect with the specific recording locations in the training set. This setup makes it easier to validate that the trained models can generalize to real-world scenarios.
The first variable in each metadata table contains the filenames of the data. Concatenate the filenames with the file paths.
trainFilePaths = fullfile(dataset_asc,"TUT-acoustic-scenes-2017-development",trainMetaData.FileName); testFilePaths = fullfile(dataset_asc,"TUT-acoustic-scenes-2017-evaluation",testMetaData.FileName);
Create Audio Datastores
The metadata might contain files that are not included in the data set. Remove the file paths and acoustic scene labels that correspond to the missing files.
ads = audioDatastore(dataset_asc,IncludeSubfolders=true); allFiles = ads.Files; trainIdxToRemove = ~ismember(trainFilePaths,allFiles); trainFilePaths(trainIdxToRemove) = []; trainLabels = categorical(trainMetaData.AcousticScene); trainLabels(trainIdxToRemove) = []; testIdxToRemove = ~ismember(testFilePaths,allFiles); testFilePaths(testIdxToRemove) = []; testLabels = categorical(testMetaData.AcousticScene); testLabels(testIdxToRemove) = [];
Create audio datastores for the training and test sets. Set the Labels property of the audioDatastore (Audio Toolbox) to the acoustic scene. Call countEachLabel (Audio Toolbox) to verify an even distribution of labels in both the training and test sets.
adsTrain = audioDatastore(trainFilePaths, ... Labels=trainLabels, ... IncludeSubfolders=true); display(countEachLabel(adsTrain))
15×2 table
Label Count
________________ _____
beach 312
bus 312
cafe/restaurant 312
car 312
city_center 312
forest_path 312
grocery_store 312
home 312
library 312
metro_station 312
office 312
park 312
residential_area 312
train 312
tram 312
adsTest = audioDatastore(testFilePaths, ... Labels=categorical(testMetaData.AcousticScene), ... IncludeSubfolders=true); display(countEachLabel(adsTest))
15×2 table
Label Count
________________ _____
beach 108
bus 108
cafe/restaurant 108
car 108
city_center 108
forest_path 108
grocery_store 108
home 108
library 108
metro_station 108
office 108
park 108
residential_area 108
train 108
tram 108
You can reduce the size of the data set to speed up the run time, which can affect accuracy. In general, reducing the size of the data set is a good practice for development and debugging. To reduce the size of the data set, you can set speedupExample to true. This example uses the entire data set.
speedupExample =false; if speedupExample adsTrain = splitEachLabel(adsTrain,20); adsTest = splitEachLabel(adsTest,10); end
Extract Features
You must extract features from the audio data to train machine learning models using the fitting functions in Statistics and Machine Learning Toolbox™. In this example, you extract features by using wavelet scattering. As shown in [5], wavelet scattering can provide a good representation of acoustic scenes.
Call read (Audio Toolbox) to get the data and sample rate of an audio file from the training set. Each audio file in the data set has a consistent sample rate and duration (10 seconds). Normalize the audio and listen to it. Display the corresponding label.
[data,adsInfo] = read(adsTrain); data = data./max(data,[],"all"); fs = adsInfo.SampleRate; sound(data,fs) disp("Acoustic scene = " + string(adsTrain.Labels(1)))
Acoustic scene = beach
Call reset (Audio Toolbox) to return the datastore to its initial condition.
reset(adsTrain)
Define a waveletScattering (Wavelet Toolbox) object. The invariance scale and quality factors were determined through trial and error.
sf = waveletScattering(SignalLength=size(data,1), ...
SamplingFrequency=fs,InvarianceScale=0.75,QualityFactors=[4 1]);Convert the audio signal to mono, and then call featureMatrix (Wavelet Toolbox) to return the scattering coefficients for the scattering decomposition framework sf.
dataMono = mean(data,2);
scatteringCoeffients = featureMatrix(sf,dataMono,Transform="log");Average the scattering coefficients over the 10-second audio clip.
featureVector = mean(scatteringCoeffients,2);
disp("Number of wavelet features per 10-second clip = " + numel(featureVector));Number of wavelet features per 10-second clip = 286
The helper function HelperWaveletFeatureVector performs these steps for a single audio clip. Use a tall array with cellfun and HelperWaveletFeatureVector to parallelize the feature extraction steps for all the data.
When you perform calculations on tall arrays, MATLAB® uses either a parallel pool (default if you have Parallel Computing Toolbox™) or the local MATLAB session. This example uses a parallel pool. If you want to run the example using the local MATLAB session, change the global execution environment by using the mapreducer function.
Extract wavelet feature vectors for all the data in the training and test sets.
train_set_tall = tall(adsTrain);
Starting parallel pool (parpool) using the 'Processes' profile ... 17-Jan-2024 12:03:54: Job Queued. Waiting for parallel pool job with ID 2 to start ... Connected to parallel pool with 6 workers.
scatteringTrain = cellfun(@(x)HelperWaveletFeatureVector(x,sf),train_set_tall,UniformOutput=false); xTrain = gather(scatteringTrain);
Evaluating tall expression using the Parallel Pool 'Processes': - Pass 1 of 1: Completed in 21 min 31 sec Evaluation completed in 21 min 31 sec
xTrain = cell2mat(xTrain')';
test_set_tall = tall(adsTest); scatteringTest = cellfun(@(x)HelperWaveletFeatureVector(x,sf),test_set_tall,UniformOutput=false); xTest = gather(scatteringTest);
Evaluating tall expression using the Parallel Pool 'Processes': - Pass 1 of 1: Completed in 7 min 29 sec Evaluation completed in 7 min 29 sec
xTest = cell2mat(xTest')';
Train Machine Learning Models
When training machine learning models, you can train several models and then select the best model based on its accuracy on the test data. However, when the target environment is an embedded system, or you have limited resources (such as memory and hardware speed), a good practice is to keep several models and compare them further using Model-Based Design tools. You can perform verification and validation to narrow your choice and select the model that provides acceptable accuracy, is best suited for the target environment, and meets application-specific requirements.
This example involves training these seven model types:
Bilayered neural network (NN)
Linear discriminant
Random subspace ensemble with discriminant analysis learners
Bag of trees (ensemble)
Linear support vector machine (SVM)
Logistic regression
Decision tree
Train the seven models and save them in the cell array multiMdls.
MdlNames = ["Bilayered NN","Linear Discriminant","Subspace Discriminant", ... "Bag of Trees","Linear SVM","Logistic Regression","Decision Tree"]'; yTrain = grp2idx(adsTrain.Labels); yTest = grp2idx(adsTest.Labels); rng("default") % For reproducibility multiMdls = cell(7,1); % Bilayered NN multiMdls{1} = fitcnet(xTrain,yTrain,LayerSizes=25,Standardize=true); % Linear Discriminant multiMdls{2} = fitcdiscr(xTrain,yTrain); % Subspace Discriminant multiMdls{3} = fitcensemble(xTrain,yTrain, ... Method="Subspace",Learners="discriminant", ... NumLearningCycles=30,NPredToSample=25); % Bag of Trees multiMdls{4} = fitcensemble(xTrain,yTrain, ... Method="Bag",Learners="tree", ... NumLearningCycles=50); % Linear SVM multiMdls{5} = fitcecoc(xTrain,yTrain); % Logistic Regression tLinear = templateLinear(Learner="logistic"); multiMdls{6} = fitcecoc(xTrain,yTrain,Learners=tLinear); % Decision Tree multiMdls{7} = fitctree(xTrain,yTrain);
Measure Model Accuracy and Size
Test the models with the test data by using the helper function HelperMdlMetrics. This function returns a table of model metrics, including the model accuracy as a percentage and the model size in KB.
tbl = HelperMdlMetrics(multiMdls,xTest,yTest); tbl.Properties.RowNames = MdlNames;
Specify the output display format as bank so the numbers appear aligned when you display the values in the table tbl.
format("bank")Display the model accuracy and the model size.
disp(tbl)
Accuracy Model Size
________ __________
Bilayered NN 57.72 10617.50
Linear Discriminant 74.69 12519.41
Subspace Discriminant 69.20 22065.51
Bag of Trees 50.37 37593.81
Linear SVM 58.40 11452.87
Logistic Regression 21.23 1934.52
Decision Tree 40.56 10728.95
Restore the default display format.
format("default")Import Models to Simulink for Prediction
You can use the accuracy and model size metrics to select the best machine learning model for deployment in Simulink. By using more than one trained model in Simulink, you can compare model performance using additional metrics, such as speed and memory footprint, to further narrow your choice.
This example provides the Simulink model slexVandVPredictExample.slx, which includes prediction blocks for all the trained machine learning models in multiMdls.
Prepare Data
Create an input signal (input) in the form of an array for the Simulink model. The first column of the array contains the timeVector variable, which includes the points in time at which the observations enter the model. The other columns contain the wavelet feature vectors.
timeVector = (0:size(xTest,1)-1)'; input = [timeVector,xTest];
Save Models for MATLAB Function Blocks
Statistics and Machine Learning Toolbox provides prediction blocks for neural network, linear discriminant, ensemble (bag of trees), SVM, logistic regression, and decision tree models:
For subspace discriminant models, you must implement the prediction functionality of the models using MATLAB Function blocks. Save the model in the MATLAB formatted binary file (MAT file) by using the saveLearnerForCoder function, and then load the file in the MATLAB Function block by using the loadLearnerForCoder function.
saveLearnerForCoder(multiMdls{3},"subDiscMdl.mat")Simulate Simulink Model
Open the Simulink model slexVandVPredictExample.slx.
open_system("slexVandVPredictExample.slx")Simulate the model and export the simulation output to the workspace.
simOut = sim("slexVandVPredictExample.slx");Close the model.
close_system("slexVandVPredictExample.slx")Examine Performance Using Simulink Profiler and SIL/PIL Manager
You can examine model performance using the execution time in both the Simulink model and the generated code.
Execute Time Profile in Simulink Using Simulink Profiler
Simulink Profiler allows you to examine the model and block execution and to identify issues that can contribute to poor simulation performance. This process helps you compare the prediction blocks for the trained machine learning models in terms of simulation speed.
Open the Simulink model slexVandVPredictExample.slx.
open_system("slexVandVPredictExample.slx")Start Simulink Profiler.
On the Debug tab, select Performance Advisor > Simulink Profiler.
On the Profiler tab, click Profile.
When the simulation is complete, the Profiler Report pane opens and displays the simulation profile for the model. In the Path column, expand the Prediction subsystem. The pane lists the performance times of the prediction blocks in descending order, from slowest to fastest.

In this example, the Bag of Trees model is the slowest, and the Neural Network model is the fastest, followed by the Decision Tree and Subspace Discriminant models.
Execute Time Profile in Generated Code Using SIL/PIL Manager
During simulation, the prediction blocks that use MATLAB Function blocks typically run faster than blocks that use masked subsystem implementation. This difference occurs because the software converts MATLAB Function blocks into C code and compiles the code into mex-files before running the block for simulation. Suppose you are interested in comparing the performance of the blocks for embedded applications. After enabling the software-in-the-loop (SIL) profiling, you can generate code from all the blocks and compare their performance using SIL simulation.
To configure code execution profiling for SIL mode simulation:
Open the Configuration Parameters dialog box. In the Simulink Editor, on the Modeling tab, click Model Settings.
In the Code Generation > Verification pane, under Code execution time profiling, select the Measure task execution time check box.
For the function execution times, select Coarse (referenced models and subsystems only) from the Measure function execution times list. This option allows you to analyze generated function code for the main model components.
In the Workspace variable field, specify the variable name as
executionProfile. When you run the simulation, the software generates a variable with this name in the MATLAB base workspace. The variable, an object of typecoder.profile.ExecutionTime, contains the execution time measurements. In the Data Import/Export pane, under Save to workspace or file, select the Single simulation output check box and specify the variable name asout. The software also creates theexecutionProfilevariable in theoutvariable (Simulink.SimulationOutputobject).In the Code Generation > Verification pane, under Code execution time profiling, select Metrics only from the Save options (Embedded Coder) list. This option helps reduce bandwidth usage for the communication channel between Simulink and the target application.
In the Hardware Implementation pane, select the type of hardware to use to implement the system represented by the model. This example uses the default value
x86–64 (Windows64).Click OK.
For more information, see Create Execution-Time Profile for Generated Code (Embedded Coder).
To generate function execution data, you must insert measurement probes into the generated code. The software can insert measurement probes for an atomic subsystem only if you set the Function packaging field (on the Code Generation tab of the Block Parameters dialog box) to either Nonreusable function or Reusable function. To enable granular execution profiling for each predict block, place the prediction blocks inside a subsystem. For each prediction block that is not a MATLAB Function block:
Right-click the block, and select Subsystem & Model Reference > Create Subsystem from Selection.
Rename the subsystem to have the same name as the prediction block.
You do not need to place the MATLAB Function Blocks (subspace discriminant models) inside a subsystem. For each subsystem block and MATLAB Function block:
Open the Block Parameters dialog box. Right-click the block, and select Block Parameters (Subsystem).
On the Main tab, select the Treat as atomic unit check box.
On the Code Generation tab, change Function packaging to Nonreusable function. Then click OK.
The prediction implementations that use MATLAB Function blocks require support for variable signals to be enabled for code generation. To enable code generation support:
Open the Configuration Parameters dialog box. In the Simulink Editor, on the Modeling tab, click Model Settings.
In the Code Generation > Interface pane, under Software environment, select the variable-size signals check box.
Close the model.
close_system("slexVandVPredictExample.slx")This example provides the Simulink model slexVandVPredictSILProfilingExample.slx, which is configured for SIL profiling. Open the Simulink model.
open_system("slexVandVPredictSILProfilingExample.slx")Run the model in SIL mode and collect profiling information. On the Apps tab, in the Code Verification, Validation, and Test group, open the SIL/PIL Manager app. On the SIL/PIL tab, ensure that the SIL/PIL Mode option under the Prepare section is set to Software-in-the-loop (SIL). On the SIL/PIL tab, click Run Verification to run the simulation and log profiling metrics.
After the SIL verification is complete, in the Results section of the SIL/PIL tab, click Compare Runs and select Code Profile Analyzer. In the Code Profile Analyzer window, under the Analysis section, select Function Execution. Navigate to the end of the list of blocks to locate the prediction blocks, and compare their execution times.

As shown in the results table, the Bag of Trees model is not the slowest implementation, as it was in the Simulink Profiler results. The fastest implementation is now Decision Tree, followed by Neural Network. Linear Discriminant and Subspace Discriminant are now the slowest.
Display the total execution time for each block. In this example, the prediction blocks are sections 9 through 15 in the code execution profiling object stored in modelTimeProfile.mat.
load("modelTimeProfile.mat")
executionProfileLog = out.executionProfile;
ep = executionProfileLog.Sections(9:end);
blockNames = {ep.Name}'blockNames = 7×1 cell
{'Neural Network' }
{'Bag of Trees' }
{'Linear SVM' }
{'Logistic Regression' }
{'Decision Tree' }
{'Linear Discriminant' }
{'Subspace Discriminant'}
totalExeTimes = [ep.TotalExecutionTimeInTicks]
totalExeTimes = 1×7 uint64 row vector
9431774 47950926 113617869 111311067 1326041 1074698585 367090280
[totalExeTimesSorted,blockIndSorted] = sort(totalExeTimes); exeTimeTable = table(blockNames(blockIndSorted),totalExeTimesSorted'); disp(exeTimeTable)
Var1 Var2
_________________________ __________
{'Decision Tree' } 1326041
{'Neural Network' } 9431774
{'Bag of Trees' } 47950926
{'Logistic Regression' } 111311067
{'Linear SVM' } 113617869
{'Subspace Discriminant'} 367090280
{'Linear Discriminant' } 1074698585
Close the model.
close_system("slexVandVPredictSILProfilingExample.slx")Measure Runtime Memory Usage Using Static Code Metrics Report
Another important measure for an embedded application deployed to low-power hardware is the amount of runtime memory required for running the application on target hardware. Embedded Coder® provides features for measuring the runtime memory footprint of the application in the form of a metric report when you generate embedded C/C++ code.
The code generator performs static analysis of the generated C/C++ code and provides the metrics in the Static Code Metrics Report section of the HTML Code Generation Report. To enable this metric for each prediction block inside the Prediction subsystem, you must place each prediction block inside an atomic subsystem and change Function packaging to Nonreusable function, as described in Execute Time Profile in Generated Code Using SIL/PIL Manager. Use the Simulink model slexVandVPredictSILProfilingExample.slx, which is configured for profiling generated code. Open the Simulink model.
open_system("slexVandVPredictSILProfilingExample.slx")To generate the Static Code Metrics Report:
Open the Configuration Parameters dialog box. In the Simulink Editor, on the Modeling tab, click Model Settings.
On the Code Generation pane, under Target selection, specify the system target file as
ert.tlc.On the Code Generation > Report pane, select the Generate static code metrics check box.
Right-click the Prediction subsystem, and select C/C++ Code > Build This Subsystem.
After the code is generated, the code generation report opens. In the Content section, navigate to Static Code Metrics Report. Go to the Function Information section at the end of the report, and inspect the Accumulated Stack Size column in the table. The stack size is sorted in descending order, by default.

The Neural Network block uses the highest amount of stack memory, followed by the Linear SVM and Subspace Discriminant blocks. The Decision Tree block uses the lowest amount of stack memory, followed closely by the Bag of Trees block.
The stack memory reported by static code metrics is the amount of memory the application uses while running. The application might include additional data, such as machine learning model parameters that are not changed at runtime. This type of data is usually stored in read-only memory, such as flash memory or ROM, and is not included in the report.
On a typical embedded system, read-only memory is usually more abundant and cheaper than runtime memory. If the machine learning model includes many parameters with large arrays, deploying the application might be problematic. The best way to find out if an application can fit the hardware is to compile, build, and deploy the application to the embedded system. The read-only application data is usually defined in the source file with the suffix "_data.c" in the code generation report. You can access this data in the Code section of the report under Data Files.
An indirect way of comparing data memory usage in machine learning models is to measure the size of the machine learning model parameters. See Measure Model Accuracy and Size for the size of the models in this example. Sort the models in ascending order by size.
sortrows(tbl,"Model Size")ans=7×2 table
Accuracy Model Size
________ __________
Logistic Regression 21.235 1934.5
Bilayered NN 57.716 10618
Decision Tree 40.556 10729
Linear SVM 58.395 11453
Linear Discriminant 74.691 12519
Subspace Discriminant 69.198 22066
Bag of Trees 50.37 37594
The Logistic Regression model is the smallest, and the Bag of Trees model is the largest. When making decisions about memory usage, look at both the stack and read-only memory footprints. Also, consider the amount of RAM (for stack) and ROM (flash or read-only memory) available on the target hardware to make the most informed decision.
Close the model.
close_system("slexVandVPredictSILProfilingExample.slx")Optimize Memory Usage with Single-Precision Data Type
The Simulink models in this example use double precision by default. When using predict blocks with masked subsystem implementation, you can choose from different data type options. By using the single-precision data type, you can significantly reduce the memory footprint of your model. Because many ARM-based processors are optimized for single-precision usage, converting to single precision can also improve execution speed.
To use the single-precision data type for machine learning model parameters and operations in the prediction algorithms, change the data type options in the block dialog boxes to single. Because this example uses numeric class labels ranging from 1 to 15, you can further reduce memory usage by choosing an integer data type for the label data.
To adjust the data type, open the block dialog box for each predict block. Then set the label data type to uint8 and set all other data types to single. For the Linear SVM, Logistic Regression, and Decision Tree blocks, enable the output score and set the data type of score to single to ensure that all operations inside the blocks use single precision.
This example provides the Simulink model slexVandVPredictSILProfilingSingleExample.slx, which uses single precision and is configured for SIL profiling. Open the Simulink model.
open_system("slexVandVPredictSILProfilingSingleExample.slx")This model is already configured for generating the Static Code Metrics Report. To generate the report, right-click the Prediction subsystem, and select C/C++ Code > Build This Subsystem.

Most of the prediction blocks use half as much stack memory as they used with double precision.
Close the model.
close_system("slexVandVPredictSILProfilingSingleExample.slx")Perform Code Coverage Analysis Using Simulink Coverage
Simulink Coverage™ performs model and code coverage analysis that measures testing completeness in models and generated code. Use Simulink Coverage to gain insight into which parts of your model are exercised during simulation, and to uncover bugs in the model or gaps in your testing.
Enable Coverage and Select Metrics
Open the Simulink model slexVandVPredictExample.slx.
open_system("slexVandVPredictExample.slx")Before you analyze coverage results for your model, you need to enable coverage and select the coverage metrics you want to see:
On the Apps tab, select Coverage Analyzer.
On the Coverage tab, click Settings to open the Configuration Parameters window.
In the left pane, click Coverage. Select Enable coverage analysis.
By default, the scope of the coverage analysis is set to Entire system. Change the scope to Subsystem. Then click the Select Subsystem button, and select the Prediction subsystem.
In the Coverage metrics section, change Structural coverage level to Block Execution. This option checks whether each block is executed during simulation.

Analyze Coverage and View Results
Next, you need to simulate the model to collect the coverage results. First, simulate the model by clicking the Analyze Coverage button on the Coverage tab. When the simulation is complete, the app highlights the model objects based on their coverage completeness.
The blocks highlighted in green are executed during the simulation. If the block is a subsystem or masked subsystem, the green highlight means all blocks inside the subsystem are executed. In this case, five out of seven blocks have full coverage.
Masked subsystems highlighted in red are partially executed, which means some blocks under the mask are not executed. In this case, the Decision Tree block is partially executed.
Coverage information is not available for the Subspace Discriminant MATLAB Function block.

If a subsystem is highlighted in red, you can navigate to the subsystem to find the specific blocks that are not executed. To find out what parts of the prediction algorithm are not executed, click the arrow on the lower left of the Decision Tree block to see the internal blocks under the block mask.
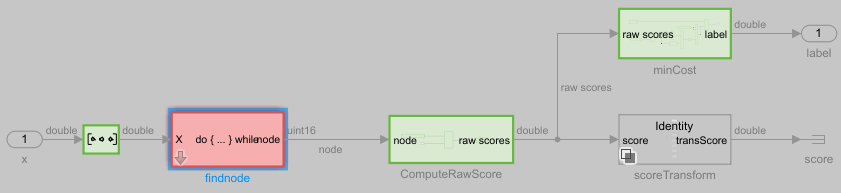
In this case, the subsystem block named findnode has a condition that is not executed. This condition is executed if the Decision Tree block has been pruned, which is not the case for this decision tree model. Therefore, you can ignore the red flag because the rest of the prediction algorithm is executed.
Simulink Coverage can measure code coverage and indicate the untested elements of your design. You can collect coverage for the C/C++ code in supported model elements, MATLAB Function blocks, or the code generated from models in SIL mode or processor-in-the-loop (PIL) mode. For more information, see Code Coverage for Models in Software-in-the-Loop (SIL) Mode and Processor-in-the-Loop (PIL) Mode (Simulink Coverage).
Close the model.
close_system("slexVandVPredictExample.slx")Run Back-to-Back Test Using Simulink Test
Simulink Test™ provides tools for authoring, managing, and executing systematic, simulation-based tests of models, generated code, and simulated or physical hardware. Simulink Test includes simulation, baseline, and equivalence test templates that let you perform functional, unit, regression, and back-to-back testing using SIL, PIL, and real-time hardware-in-the-loop (HIL) modes.
You can compare results between your model and generated code by running equivalence tests in different environments, such as model simulation and SIL, PIL, or HIL execution. Equivalence tests are sometimes referred to as back-to-back tests.
Create test cases and test harnesses automatically by using the Test for Component wizard.
Set the current working folder to a writable folder.
Open the
slexVandVPredictSILProfilingExample.slxmodel.Open the Configuration Parameters dialog box. In the Simulink Editor, on the Modeling tab, click Model Settings.
On the Code Generation pane, under Build Process, deselect the Generate code only option.
Navigate to the Prediction subsystem, and select the Neural Network subsystem.
On the Apps tab, in the Model Verification, Validation, and Test section, click Simulink Test.
On the Tests tab, click Simulink Test Manager.
Select New > Test for Model Component. The Create Test for Model Component wizard opens.
To add the Neural Network subsystem you selected in the model, click Use currently selected components. The Selected Components pane displays the Prediction subsystem and the Neural Network subsystem. Remove the Prediction subsystem from the list of Selected Components.
Click Next to specify how to obtain the test harness inputs. Select Use component input from the top model as test input. This option runs the model and creates the test harness inputs using the inputs to the selected model component.
Click Next to select the testing method. Click Perform back-to-back testing. For Simulation1, use
Normal. For Simulation2, use Software-in-the-Loop (SIL).Click Next to specify the test harness input source, format, and location for saving the test data and generated tests. For Specify the file format, select
MAT. Use the default locations for Specify the location to save test data and Test File Location.Click Done. The wizard creates the test harness and test case, and then closes.
Click Run to run the back-to-back test.
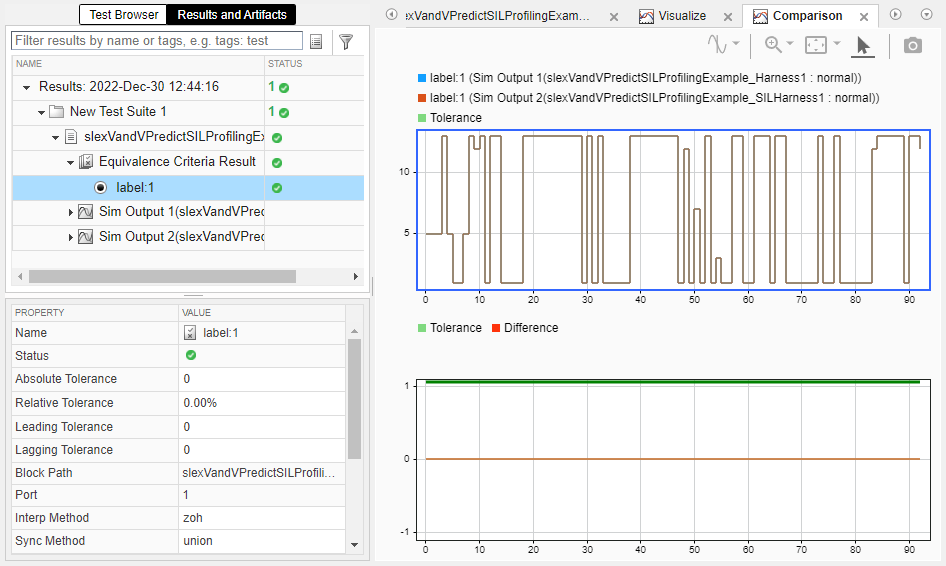
Expand the Results hierarchy in the Results and Artifacts panel. Select label:1 under Equivalence Criteria Result. The upper plot shows that the output signals align, and the lower plot shows no difference between the output signals.
More About Compliance with Industry Standards
IEC Certification Kit provides tool qualification artifacts, certificates, and test suites, and generates traceability matrices. The kit helps you qualify MathWorks® code generation and verification tools, and streamline certification of your embedded systems to ISO® 26262, IEC 61508, EN 50128, ISO 25119, and related functional-safety standards such as IEC 62304 and EN 50657.
IEC 62304 (Medical device software – Software life cycle processes) is an international standard that describes the software development and maintenance processes required for medical device software. For example, if you require FDA approval for your hearing aid software you can use IEC Certification Kit to validate your design.
For FDA approval, medical device manufacturers must validate the software tools they use in the development of a medical device by demonstrating that the tools have an acceptably low risk of harm, even in the presence of an incorrect output. IEC Certification Kit allows you to perform relevant verification and validation tasks and document the results. For more information, see FDA Software Validation.
For more information on how to use IEC Certification Kit, see Get Started (IEC Certification Kit).
Helper Functions
HelperWaveletFeatureExtractor
function features = HelperWaveletFeatureVector(x,sf) % Copyright 2019-2023 The MathWorks, Inc. x = mean(x,2); features = featureMatrix(sf,x,Transform="log"); features = mean(features,2); end
HelperMdlMetrics
The HelperMdlMetrics function takes a cell array of trained models (Mdls) and test data sets (X and Y) and returns a table of model metrics that includes the model accuracy as a percentage and the model size in KB. The helper function uses the whos function to estimate the model size. However, the size returned by the whos function can be larger than the actual model size required in the generated code for deployment. For example, the generated code does not include information that is not needed for prediction. Consider a CompactClassificationECOC model that uses logistic regression learners. The binary learners in a CompactClassificationECOC model object in the MATLAB workspace contain the ModelParameters property. However, the model prepared for deployment in the generated code does not contain this property.
function tbl = HelperMdlMetrics(Mdls,X,Y) numMdl = length(Mdls); metrics = NaN(numMdl,2); for i = 1 : numMdl Mdl = Mdls{i}; MdlInfo = whos("Mdl"); metrics(i,:) = [(1-loss(Mdl,X,Y))*100 MdlInfo.bytes/1024]; end tbl = array2table(metrics, ... VariableNames=["Accuracy","Model Size"]); end
References
[1] Seshia, Sanjit A., et al. "Toward Verified Artificial Intelligence." Communications of the ACM, Vol. 65, No. 7, July 2022, pp. 46–55.
[2] A. Mesaros, T. Heittola, and T. Virtanen. "Acoustic Scene Classification: an Overview of DCASE 2017 Challenge Entries." In proc. International Workshop on Acoustic Signal Enhancement, 2018.
[3] Huszar, Ferenc. "Mixup: Data-Dependent Data Augmentation." InFERENCe. November 03, 2017. Accessed January 15, 2019. https://www.inference.vc/mixup-data-dependent-data-augmentation/.
[4] Han, Yoonchang, Jeongsoo Park, and Kyogu Lee. "Convolutional neural networks with binaural representations and background subtraction for acoustic scene classification." The Detection and Classification of Acoustic Scenes and Events (DCASE) (2017): pp. 1–5.
[5] Lostanlen, Vincent, and Joakim Anden. "Binaural scene classification with wavelet scattering." Technical Report, DCASE2016 Challenge, 2016.
[6] A. J. Eronen, V. T. Peltonen, J. T. Tuomi, A. P. Klapuri, S. Fagerlund, T. Sorsa, G. Lorho, and J. Huopaniemi, "Audio-based context recognition." IEEE Trans. on Audio, Speech, and Language Processing, Vol 14, No. 1, Jan. 2006, pp. 321–329.