Why Choose Deep Learning | Deep Learning for Engineers, Part 1
From the series: Deep Learning for Engineers
Brian Douglas
This video introduces deep learning from the perspective of solving practical engineering problems. Learn why deep learning may be the method of choice.
Published: 31 Mar 2021
In this series, we’re going to introduce deep learning, at least from the perspective of solving practical engineering problems. We’re not going to go into too much depth into neural network architectures or the algorithms that make deep learning work - there are already tons of great resources that describe all of that fantastically and I’ve left links to many of them in the description of this video. Instead, the goal of this series is to provide an introduction to the range of engineering problems that deep learning is well suited for, and why it can solve these problems when traditional methods fall short; either by being inefficient, inaccurate, or impractical.
I think it’ll be pretty interesting so I hope you stick around for it. I’m Brian, and welcome to a MATLAB Tech Talk.
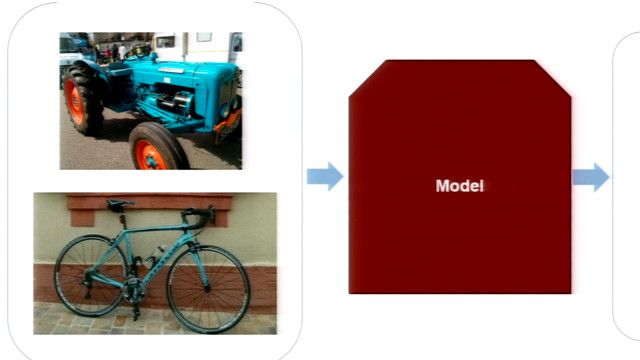
At a really high level, deep learning is a machine learning technique that teaches computers to learn by example. Specifically, we’re teaching a computer how to perform some classification task by exposing it to known scenarios and having it automatically adjust its model depending on whether it produced the right response or not. Once we have a sufficiently trained model, using enough labeled data, we could input data that we haven’t classified yet and the model will apply the most probable label to it.
Deep learning often uses deep neural networks to model the complex relationship between an input, which is some kind of data, and an output, the classification or labeling of that data.
And unlike other mathematical models that can be designed and tuned manually, deep neural networks really can’t be. They are too complex and have too many free parameters. For example, Googlenet, which is trained to recognize objects in images has about 7 million parameters. To tune networks like these requires learning algorithms. These are optimization techniques that tweak and adjust the parameters over time.
Having a trained model that can classify data is beneficial far beyond being able to label pictures of cats or objects on a desk.
For example, we might want to find and label specific objects in an image which we can use for object tracking and localization. We might want to visually inspect hardware for defects like material damage. Or we might want to diagnose health issues from an X-ray or MRI image.
But images, themselves are just one data type where complex patterns exist. We can apply these learning techniques to audio signals for speech recognition, or song identification, or determining which genre the song is from. And there are also other time series signals with complex patterns like we find in predictive maintenance applications, or finance and money markets, or biomedical industries.
In each of these cases, hopefully, you can see how valuable it can be to be able to extract, classify, and label complex patterns within the data automatically, especially if it could be done faster and more accurately than a human.
So, that’s a reason to build a classification model, but what is the motivation for designing a classification network with millions of parameters that requires deep learning to tune?
Well, to answer that, I’ll start by posing this question to you:
How would you approach writing code that can distinguish between two different complex patterns in data? And even though the answer is application dependent, as we’ll see it’s not always easy to do using rule-based approaches where a human has to craft and curate the logic themselves.
And so we turn to techniques like deep learning, which simply put is a way to develop models that produce useful input/output relationships, specifically models that can find, classify and label complex patterns in data.
It does this by identifying small features in the data, which then can be combined into larger features, and then into recognizable patterns. I think understanding this feature recognition concept will go a long way to helping you decide when it makes sense to use deep learning to build your model versus some other more traditional approach.
So, with that in mind, let’s start by getting a better understanding of what a feature is in the first place. And we’ll use sensor data as an example.
Engineers use sensors to measure the environment and we want to use the measured data to perform some future action - we want to make some informed decision based on what the sensors observe.
Therefore, we often need a function or algorithm that takes in sensor data and returns something useful. And we have tons of methods that we can use to find patterns in sensor data. For two simple examples, we might just run a linear regression to determine how the data is trending over time, or we may look for when the signal drops below some threshold to indicate that whatever that sensor was observing is no longer in view. But here’s the thing I want to point out, the complexity of this algorithm and how difficult it is to develop scales with the complexity of the patterns that you’re trying to find and label as well as how those pattern vary from one observation to another.
Let me give you a rather silly example to show this. Let’s say we’re designing a watch that has an accelerometer as one of its sensors and all we want to know is how fast the watch is accelerating. In this case, the pattern we’re looking for is essentially the true acceleration and the function that generates it might just be a low pass filter to remove any high frequency noise. So, in this case, it’s a pretty simple function, and one that we could easily design with traditional methods. By traditional methods, I’m generally referring to any method that doesn’t rely on some form of machine learning.
But now let’s look at a case where the pattern we’re looking for is more abstract. Perhaps we want to use the accelerometer to determine when the user high-fives someone. In this case, the input into our function is still acceleration - the same exact data as before, but the output is a flag that is set when a high five pattern is detected. The function that does this classification is decidedly more complex than a simple low pass filter because the pattern it is looking for is more complex.
Now here is one example of how we might use a rule-based approach to design this function. Ahead of time we could record the acceleration of a person performing a high five. We can label this particular acceleration profile as a high five since we purposefully set up the test to produce this data. Now, we could use this labeled data to come up with a representative profile that we could pattern match against the continuous stream of acceleration measurements from the sensor. Our function could look at the standard deviation between the two signals, which is hovering around 0.4 for non-high-five motions, and we could claim there was a high five when the deviation drops below some threshold.
However, we can make this problem more difficult by realizing that every high five is not the same, but that the acceleration pattern varies from instance to instance. Some people might move their hand faster or slower, or pause right before the big slap, or just high five in a strange way. Now, if we want to use our standard deviation approach we now have to do that for each profile in the set, and if the deviation between any of these profiles and the sensed acceleration drops below some threshold we claim a high five took place. But that wouldn’t cover the cases for the high fives that fall outside of these ranges and that we didn’t collect data for. So, instead of having a database of millions of profiles that we need to check, you know one for every possible type of high five, we might be a little smarter about it and realize that instead of looking at the pattern as a whole, which can have wild variations, maybe we can find a set of features that they all have in common, and check for those?
By features, I mean smaller portions of the pattern that combine to make up the entire profile. For example, we may reason that a high five profile consists of a slow acceleration at the beginning corresponding to a person raising their hand. Then another slow acceleration as they move their hand backward, followed by a quick acceleration as their hand moves forward and makes contact with another person. And even though every high five profile is different quantitatively from start to finish, each of these features might exist in some form in every profile. Therefore, we may be able to claim that any combination of a slow, slow, fast acceleration is a high five - even if we observe a new high five that we didn’t explicitly collect data for.
In this way, we’re breaking the larger pattern down into its base components, its features.
However, remember that even if we have access to lots of labeled data, writing rule-based logic that understands the relevant features of a pattern can be time consuming, inefficient, and possibly impossible for humans to do directly because it requires us to have a lot of intimate knowledge about the pattern and every variation of that pattern that we’re trying to find.
To put a more concrete example to this statement, let’s look at a camera which can generate images that have patterns that are extremely complex - much more complex than the acceleration profile that represents a high-five.
Fundamentally, the data in an image represents the color, intensity, and direction of light that reaches the detector. But this isn’t what we’re usually interested in, we’re interested in the complex patterns embedded within this data.
And, if we thought picking out relevant features of a high five was difficult, imagine trying to come up with the features that allow you optically identify a good hex nut versus a defective one. Even if you had access to thousands of images of both, it would be nearly impossible to come up with an algorithm that would distinguish one from the other. At least, it would be without deep learning.
I already mentioned how deep learning learns the relevant features and combines those features to classify the larger patterns directly from a bunch of labeled input data. But the really neat thing about deep learning, at least to me, is that the features that the layers in a deep neural network converge on and use for pattern recognition, often aren’t the features that are obvious to a human. Even though it’s helpful to think about these features as things people can understand like lines and little loops, and slow and fast accelerations, there’s no guarantee that the network will actually converge on something this recognizable.
To show you what I mean, let’s run the MATLAB example called Create Simple Deep Learning Network for Classification that ships with the Deep Learning Toolbox.
This example, trains a neural network to recognize hand written numbers. This example trains the network using 750 labeled images for each of the 10 numbers. It then is uses 250 images for each number to verify the accuracy of the network, which we can see here is about 99% accurate, so not too bad.
The network we’ve trained has an input and output layer, as well as a lot of hidden layers in between. The details of this network and the layers aren’t too important. I think for this video, it’s enough to understand that there are three convolutional layers in here, where each one is looking for particular features in the input image.
To get a sense of what the first convolutional layer is looking for, we can visualize the filter weights for the second layer. There are 8 filters in this layer. You’ll notice that some of the filters kind of look like little tiny line segments and loops, but for the most part they look like various little blobs. So somehow, this network is saying that if these blobby features show up strongly in certain locations in the image, it can use them to determine what the number is. These blobs probably aren’t something that a human would come up with but they do represent the same idea of small recognizable features.
Now, there isn’t a whole lot of interesting detail in these low resolution black and white images, but we can do the same thing with a network that is trained to recognize flowers within larger color images. To see this, let’s look at the MATLAB example Image Category Classification Using Deep Learning. The input image is a daisy, and if you apply the trained classifier on this test image it does in fact return the label 'daisy'. If we scroll back up, what we’re seeing here is a visualization of the first convolutional layer weights - these are the primitive features that help this network distinguish between a daisy and something else. Again, it seems likely that these aren’t the features that a human would come up with if they were trying to define the features of a flower. At least, I don’t think I would.
This is why deep learning is so powerful for certain engineering problems. Specifically problems that involve finding patterns in an image where the defining features are difficult to describe.
Of course, we mentioned that deep learning isn’t only useful for labeling objects in images. There are many engineering applications where you could use these techniques to find and label patterns in data. Whether that data is in the form of an image, or an audio file, or any other signal.
In each of the next few videos, we’ll look at a specific engineering topic in detail and discuss how deep learning can be applied to solve that particular problem. In the process, we’ll talk about the design workflow for deep learning systems, and where difficulties may arise throughout this workflow for the engineering problems that you might come across.
So if you don’t want to miss that or any other Tech Talk video, don’t forget to subscribe to this channel. Also, you can check out my channel, Control System Lectures, if you’re interested in other control theory topics as well. Thanks for watching, and I’ll see you next time.