Planning Model Architecture and Modeling Patterns for ISO 26262 Compliance
The ISO 26262 standard for functional safety provides guidance on the development of automotive electronics and electrical system, including embedded software. A common challenge is to determine the strategy, software architecture, and design patterns up front in a project to achieve standard compliance and to avoid mid-project changes to these foundational areas. In this presentation, MathWorks engineers will address the following topics based on their experiences applying Simulink® to production programs that require ISO 26262 compliance.
- Key considerations for model architecture for ISO 26262 compliance
- Modeling constructs required to meet freedom from interference
- Applying the above best practices to meet AUTOSAR at the same time
Recorded: 30 Apr 2019
OK. Thank you. The purpose of this presentation is to really give you an overview of some of the best practices that we've uncovered in the consulting organization when working with organizations that are trying to adopt ISO 26262. These best practices tend to focus around two main areas. First is the Simulink model architecture that's chosen and used through the algorithm's development, and then also the modeling patterns that are used inside of the actual Simulink models.
The first thing I'd like to do is talk a little bit about what exactly is ISO 26262. It's really a functional safety standard for road vehicles. And it focuses on doing a risk-based assessment to determine where the functional safety concerns are in the electrical system, and then, through a rigorous process, you manage and mitigate those risks as much as possible. And from The MathWorks perspective, and mine in particular in the consulting services organization, we've seen a great uptick in the number of users who are interested in ISO 26262. And I think it's for a number of reasons.
So first, there's an increase in system complexity that's going into automotive vehicles. We've all seen it over the last couple of decades, how much is going into electrical systems now. The other thing that I think has changed a little bit, too, is the advent of ADAS, and then automated driving-related applications. So as some of that control is shifted away from the driver into software's hands, the functional safety concerns that are associated with that also increase. So I think companies are really looking for a way to be able to mitigate some of these risks.
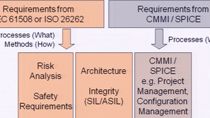
And ISO 26262 really does facilitate modern software engineering practices, such as model-based design. It's actually called out a couple of places on the standard. And we'll investigate this in a subsequent slide, too.
So when users approach us in the consulting services organization, a lot of times, they have some initial questions. So first, they want to -- first, they have an existing workflow. They want to know, is my workflow already compatible with ISO 26262? In consulting services, we help them out a lot of times looking at their existing workflow, and then bridging where those gaps are at to the actual standard.
They also want to know, how do I efficiently reach unit-level testing coverage? So ISO does a good job in the standard of splitting down activities that should happen at the integration level of software and at the unit level of software. And they want to know how to efficiently reach unit-level testing coverage, which is required by ISO.
They want to know how to achieve freedom from interference. So ISO also mentions, in many places in the standard, having freedom from interference. And what that really relates to is if I have an ASIL level A component and an ASIL level D component that are going into the same system, how do I know that those two are not going to interfere with each other? How do I know that my ASIL level A component is not going to inadvertantly write into my ASIL level D component? So they want to know how to manage that.
They want to know, can AUTOSAR work with ISO 26262? The answer to this is yes, and we'll talk about this in a slide later. And then, they want to know, is Simulink even suitable for use with ISO 26262? And if we look at the standard, ISO has 10 different sections. Section 6 focuses around software engineering. And this is one of the tables out of Section 6 that's talking about some of the activities that should go on in your individual process.
And inside of the notes section, it actually lists out multiple model-based design tools that can be used to accomplish some of these tasks. And it actually lists out directly Simulink and Stateflow, and then later on talks about using that model for code generation purposes. So when you think of model-based design in terms of ISO 26262, it's really not adversarial. It's actually listed out multiple times in the standard.
So the next thing I'd like to do is take a couple minutes to talk about how MathWorks generally supports ISO 26262. So one of the first main ways is through the IEC Certification Kit. The IEC Certification Kit provides a couple of key items. First, as a model-based design reference workflow-- so at a very high level, we take portions of the ISO standard, map that to the corresponding MathWorks products, and we have a high-level reference workflow that you can follow to be able to target ISO 26262.
The other aspect is tool qualification. So if you use tools in your design process, you're likely going to have to go through tool qualification activities. The products that are referenced in the MathWorks reference workflow are already pre-qualified. And there's already supporting artifacts inside of the IEC Certification Kit that you can rely on to do some of those initial tool qualification activities. And a number of customers have already used the IEC Certification Kit and been able to achieve ISO 26262 compliance. An example on the right-hand side of the slides shows a customer that's been able to achieve ASIL level D certification for their individual UCU.
The other way that we typically support ISO 26262 is through consulting services. So as I mentioned, the IEC Certification Kit does a good job of giving you that high-level reference workflow. But a lot of times, each individual user's process or development patterns are a little bit different. So through consulting services, we tend to help users to tailor that individual development process and the verification process to their individual needs so that it matches what their organization needs to be able to achieve.
And as I mentioned in one of the previous slides, we also do gap analysis-type activities to look at existing processes, and try to see if there's any gaps in relation to ISO 26262 in the process that's being used. And then, one of the other big areas that we tend to help out on is tool qualification support.
So as I mentioned in the IEC Certification Kit, there's a lot of artifacts that help with tool qualification. But if customers build up their own tools on top of MathWorks products, they'll likely need to go through some tool qualification activities for those custom tools that they've built up. So we help customers to analyze those, and then determine what types of test cases need to be run, and how they can actually qualify that tool. And this has also been done with a number of users. There's an example on the right-hand side of the slide of a quote that we have from a user that leveraged us to help them tailor their development process to their individual needs.
So if we take a step back for a second, as I mentioned, the Certification Kit does a very good job of taking the ISO standard and mapping that ISO standard directly to the tools that can be used inside of the high-level reference workflow. So it really does a good job of saying, here's what's in ISO. Here's the products that are in MathWorks tools, and then maps those directly to each other. So it gives you that high-level reference workflow.
From the consulting services side, we tend to focus on the implementation, or we're brought in a little bit later to help users to be able to tailor their individual process to meet their individual needs. And a lot of times, we end up looking at their low-level implementation. So we're looking down at the very low level of the process that they're using, and then sometimes how they've implemented a variety of different things to be able to meet their individual needs.
And when we look at these low-level implementation details, and we start working through some of the details with users, we find out a lot of times that the questions that are coming up are not really from that low-level implementation, but they stem from something a little bit higher level. It's not so much at that high-level reference workflow, or at the low-level implementation, but a lot of it focuses around the model architecture that they've chosen.
So through these engagements, we've found a number of best practices that focus heavily around the Simulink model architecture that is chosen or used when developing algorithms. The best practices that we're going to talk about here today really are not-- we don't deem these as, if you follow these best practices, you're automatically going to be ISO 26262. But what we are saying is from what we've seen in a number of engagements, these best practices seem to ease the adoption of ISO 26262.
And these best practices that we've found to date are really broken down into four categories. One is Simulink model architecture-- so how is the model or your algorithm broken up into smaller pieces and units? How are signals routed through the individual model? So how do they come into the model, and then flow through the model? And how are they managed? Data definition-- so how are workspace objects in the workspace managed, and then both used within the model? And then, code generation configuration options-- so how do they pick the configuration parameters that they're going to use for actual code generation?
And these have all been put into a best practices paper that we have available. If you're interested in the best practice paper that we've put together, please feel free to follow the link that I have up here on the screen. Let us know, and we'll be happy to get you access to it.
So the next thing I'd like to do is go through a few of these best practices. So these slides that I have broken down-- I've tried to take a couple of the common themes that we've seen while working with users, and then tried to list out the best practice that we found based upon those themes.
So a lot of times, when we walk in and start working with users, we notice that they have difficulty with model verification. It gets increasingly difficult as their algorithm gets larger. And a lot of times, they don't realize this until late into the design cycle. And the best practice that we've found here is really, as an organization that's developing algorithms, it's extremely important to take a step back and really think, for our individual roles for our organization, what's the appropriate size of our units?
So sitting down, for example, and thinking, for an individual unit, what's the maximum number of inputs and outputs that I want to have going into a model? It's probably not 100. But it's probably more than five or 10-- and figuring out where that balance is, based upon the type of algorithm that you're building on. How do you deal with reusable libraries? So if you want to reuse portions of your algorithm, what's the best method that you're going to use within your organization-- and actually listing that down.
What's the maximum cyclomatic complexity that you want to have for an individual unit, to make sure that it's testable once you get to that point. Well, maybe, what's the maximum number of block elements that you want to have in a model? And just really thinking through this as an organization, and deciding for yourselves, here's where our thresholds are going to be is increasingly important.
And this is becoming ever easier in MathWorks products. On the right-hand side of the screen, I have a snapshot of Model Metrics Dashboard. If you run it on your model, it'll actually give you a high-level view of all of a lot of those metrics that I've just listed out. It'll tell you the MATLAB lines of code, the number of Stateflow lines of code in your model, the number of blocks, what the cyclomatic complexity of your model is. It'll give you all of those things in a high-level overview.
So as you're walking into a model review, I would highly recommend having those thresholds already listed down before you begin development. And use this as a view to sit down with your colleagues and decide, OK, is this unit an appropriate size before we keep moving it through the development process?
And these types of metrics have been talked about in a number of papers. The two thresholds that I listed for cyclomatic complexity and the number of elements in the model was actually listed in the model quality objectives paper that was released a couple of years ago. And this was users from industry along with MathWorks coming together, and then listing down a set of guidelines. So if you don't have a good starting point, this is a great place to start to find out what the appropriate limits are for your organization.
So another item that we've seen quite a bit is users realize quite late that they have poor modularity in their algorithm. So they have portions of their algorithm that they want to be able to reuse, but they can't, just based upon the way that it's been built up. And they end up with one large portion of their algorithm.
Sometimes, they're unable to perform unit-level testing, as I mentioned, and they don't realize this late into the development cycle. Sometimes, they have configuration management difficulties. And this stems from, sometimes, that they have multiple users that need to work on a section of the algorithm, but they have one large model file. So they have to manage those changes, and then merge them together, sometimes manually. And sometimes, they don't realize until late in the development cycle that they are going to have difficulty achieving freedom from interference.
So the best practice that we've found here is at that lowest unit level, at that lowest testable unit, use a model reference. This does a couple of things. It allows you to easily be able to see the interfaces that are going to go into that section of the code. And then, when you generate code for that individual model reference, you're going to be left with a separate set of CNH files. And then, the interfaces that are listed at that level of the unit are going to match what you see in the code. So doing back-to-back unit testing, both in the model and at the code level, becomes easier.
The other thing that this helps with, too, is that multiple users can work on different units. So if one user is responsible for one section of the algorithm, they can work on that individual model file. If another user is responsible for another section, they can work on their own individual model file.
And one other point with this, too, is-- and I have an example here on the right-hand side of the slide. So this example actually has three units in it. You can see on the far-right corner, that's a unit that's at the higher level of the model. And then, at that lower level of the model, there's two separate units that are related to each other. So if you have functionality or features that are going to be related to each other, the other best practice that we've found is to use a virtual subsystem to group those together.
So for example, let's say I have an ABS feature. And in that ABS feature, I'm going to have two different units-- one that calculates filtered real speed, and another one that maybe actuates the brakes. I can group both of those together into a virtual subsystem so that my model makes sense logically. But then, at that lower unit level for each of those, I can reuse them if I use a model reference. And then, also, it's easier to test those at that level, also.
So if we take this one level higher-- and this is taking off where we left off on the last slide. If we go one level higher, the other best practice that we've found here is to really split your functionality based upon the ASIL level. So if you have functionality that's going to be rated at different ASIL levels, at the top level of your controls model, split the functionality at that level. So if I have an ASIL level D component, make a separate model reference for that functionality, and group the functionality accordingly. If I have a separate section that's going to be QM-controlled, then have a separate model reference for that, and split that into a separate model reference.
This does a couple of things. So when I go to generate code, I can generate code for each of these individually. And I'll have separate segmented sections of the code so that I have my model reference code for my ASIL level D functionality that's segmented into my model reference code for my QM functionality that's segmented separately.
And then, this also does the task of exposing the interfaces that are going to go between these different ASIL levels. So a lot of times, you want to control and then manage the signals that need to go between ASIL levels so that you can look for risks associated with those, and then test those out appropriately. And this really exposes the signals that are going to pass between those different levels.
So in summary, when you're splitting up your model, from what we've found at this point, at that top level of the controls model, a model reference seems to work out best. At the integration level, a virtual subsystem seems to work out OK. You could use a model reference, but from what we've seen, it seems to be not necessary. And then, at the lower unit level, use a model reference to ease some of the configuration management difficulties and the testability aspects of the algorithm.
So as I mentioned, at the top level of the model, if you split your functionality based upon ASIL level, at the top level of the model, now, you're going to easily be able to see the signals that are going between those different levels. So a lot of times, what users first need to do is they need to look at this top level of the controls model, and they need to think through, OK. I have a QM signal that's providing the signal. And then, I want to use that signal inside my ASIL component.
The first thing that they're going to usually have to decide is, is this even OK, that I have an ASIL component that's using something that's coming from a QM component? If it is OK, I probably need to add an additional logic to protect for any types of adverse impacts if that signal's incorrect, or not giving us a correct value because it's at a lower ranking. And then, if both of those are OK, the next thing I need to think through is, OK, how am I going to actually share and exchange data between these two individual components?
So the best practice that we've found here is to really use-- a get/set function seems to enable users to implement their own protection strategies. So embedded coder has a shipping storage class for get/set functions. And if you tag the signals at the top level of your ASIL components, what this will do is when you generate code, you'll be left with-- whenever you want to read a value, you'll be left with a get function. Whenever you want to write a value, you'll be left with a set function.
And this allows you to fill out that function body for your own protection needs or whatever strategy you've chosen. So for example, we've seen users inside of the get function that will actually first unlock memory, get a copy of the memory, then re-lock memory. Then, that's the methodology that they chose to be able to protect those individual signals.
So as I mentioned, it doesn't really directly put protection into those signals, but it enables you the flexibility to protect signals in the manner that you want. And in a number of consulting engagements, we've expanded the storage class to actually generate the function bodies of those functions for the individual user's needs. So that's not difficult to do, either.
And the last best practice that I want to talk a little bit about is bus signal. So after seeing a lot of models from a lot of different users, I know when you get to the top level of a controls model, there's a lot of signals that are coming into the controls model. There's a lot of management that you have to do to be able to manage all of those different signals. So it's natural to want to gravitate towards a bus signal.
But a lot of times, what we've found out, when we look at user's models, is that sometimes, they have inefficient bus segmentation. So they split buses before thinking through what type of bus hierarchy they should have. Sometimes, it's inconsistent across developers. So one developer decides to split buses in one manner. Another developer decides to split buses in another manner. And sometimes, this also leads to difficulty where they're constantly splitting those buses using the signals, and then regrouping those buses back into signals later on. And this is sometimes inefficient in code generation, and it's also difficult to view the model when it's split this way.
So the best practice that we have here is to really take a step back, again, in your organization, and think through that hierarchy of your buses and how you want to build them up so that each developer is developing in a consistent way. When someone's looking at a different user's model, then it's going to be done in a consistent manner. And that seems to help out quite a bit.
The example that I have here, on the right-hand side of the slide, has worked out well in a couple of consulting engagements that we've had where at the top level of the bus structure, first have the ASIL level. One layer down inside of the bus, have the feature that's providing the signal. Another layer under that, have the rate that the signal is being updated, if there's multiple rates inside of that feature. And then, at the lowest level, have the individual signal that you're going to split off. And again, I'm not saying that you have to use this exact structure. But the most important thing here is to think as an organization of how you want to split those buses, and then manage them.
And then, one last important point to talk through a little bit is AUTOSAR. So the best practices that we've shown here, and that are in the paper, work out just fine with AUTOSAR. So that's something that's not a concern. In many cases, AUTOSAR actually mitigates the need to do some of these best practices.
So for example, I mentioned using get/set storage classes to be able to exchange data between units. In AUTOSAR, if you're going to exchange data, you typically go through a sender and receiver report, and the sender and receiver port goes through the RTE. And this is really just a function call to both get the value and to set the value. So this is already ingrained in the AUTOSAR architecture. And another key point here, also, is the reference workflow that I talked about in the start of this presentation. This also works just fine with AUTOSAR. So if you use the IEC Certification Kit and the reference workflow that's provided, this is also supported with AUTOSAR.
So in summary, the best practices that we had time to talk through here today were really best practices that we uncovered through a number of consulting engagements. And it's common themes that we've seen-- that users run into some of these things later on in their development process. All of the-- oh. I'm one slide behind.
All of the best practices that I've gone through are listed here in this bulleted list. All of the items that are listed in orange are items that I had a chance to talk through today. All the items that are listed in black are items that are actually in the paper that I didn't have a chance to talk through today. But they're all in the paper. If you'd like access to the paper, please feel free to contact us at the link below, and we'll be happy to get you that paper. And if you would like to talk to us about anything related to ISO 26262 or your ISO endeavors, feel free to stop by the ISO booth that we have outside of this room. Thanks.
[APPLAUSE]