permutationInvariantSISNR
Syntax
Description
metric = permutationInvariantSISNR(proc,ref)
metric = permutationInvariantSISNR(proc,ref,Name=Value)permutationInvariantSISNR(proc,ref,SubtractMean=false) does not
subtract the means from individual signals before computing the permutation invariant
SI-SNR.
Examples
Create an audio signal that combines the speech of two speakers. Scale one of the speech signals by one half before summing them.
[s,fs] = audioread("MultipleSpeakers-16-8-4channel-5secs.flac");
s = s(:,1:2).*[1,0.5];
x = sum(s,2);
x = x./max(abs(x));Use separateSpeakers to perform speaker separation on the mixed signal. Call the function again with no output arguments to plot the separated signals.
y = separateSpeakers(x,fs,NumSpeakers=2); separateSpeakers(x,fs,NumSpeakers=2)
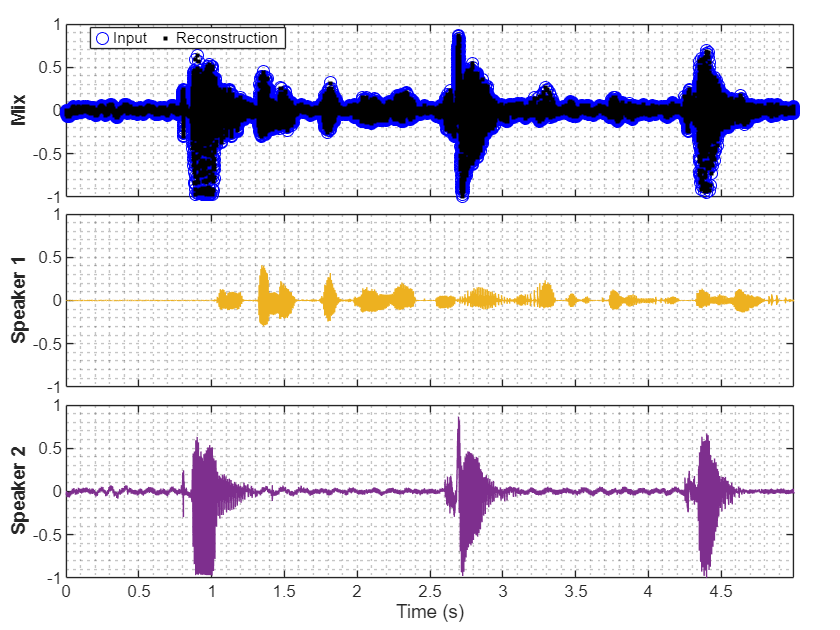
Measure the SI-SNR to evaluate the speaker separation. Call sisnr comparing the separated signals with both possible permutations of the ground truth signals.
snr1 = mean(sisnr(y,s))
snr1 = single
-39.8843
snr2 = mean(sisnr(y,fliplr(s)))
snr2 = single
21.1212
Use permutationInvariantSISNR to measure the SI-SNR of the best permutation aligning the separated signals with the ground truth.
pi_snr = permutationInvariantSISNR(y,s)
pi_snr = single
21.1212
Create an audio signal that combines the speech of three speakers with different scaling factors.
[s,fs] = audioread("MultipleSpeakers-16-8-4channel-5secs.flac");
s = s(:,1:3).*[1,0.5,0.1];
x = sum(s,2);
x = x./max(abs(x));Use separateSpeakers with NumSpeakers set to 1 to perform one-and-rest speaker separation on the mixed signal. Call the function again with no output arguments to plot the separated signals.
[y,r] = separateSpeakers(x,fs,NumSpeakers=1); separateSpeakers(x,fs,NumSpeakers=1)
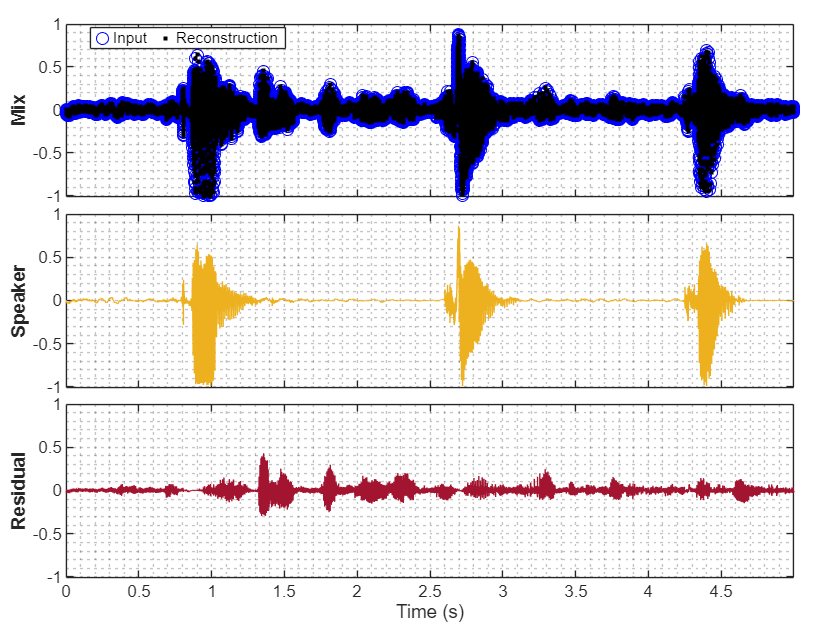
Measure the permutation invariant SI-SNR of the separated signal and residual with PermutationType set to "OR-PIT".
proc = [y r];
pi_snr = permutationInvariantSISNR(proc,s,PermutationType="OR-PIT")pi_snr = single
18.1792
Call permutationInvariantSISNR again with an additional output argument to get the index of the reference signal used as the "one" signal to calculate the SI-SNR. Use this index to listen to the signal.
[~,refOrder] = permutationInvariantSISNR(proc,s,PermutationType="OR-PIT")refOrder = 1
groundTruthSeparatedSpeaker = s(:,refOrder); sound(groundTruthSeparatedSpeaker,fs)
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
References
[1] Kolbaek, Morten, Dong Yu, Zheng-Hua Tan, and Jesper Jensen. “Multitalker Speech Separation With Utterance-Level Permutation Invariant Training of Deep Recurrent Neural Networks.” IEEE/ACM Transactions on Audio, Speech, and Language Processing 25, no. 10 (October 2017): 1901–13. https://doi.org/10.1109/TASLP.2017.2726762.
[2] Takahashi, Naoya, Sudarsanam Parthasaarathy, Nabarun Goswami, and Yuki Mitsufuji. “Recursive Speech Separation for Unknown Number of Speakers.” In Interspeech 2019, 1348–52. ISCA, 2019. https://doi.org/10.21437/Interspeech.2019-1550.
[3] Yu, Dong, Morten Kolbaek, Zheng-Hua Tan, and Jesper Jensen. “Permutation Invariant Training of Deep Models for Speaker-Independent Multi-Talker Speech Separation.” In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 241–45. New Orleans, LA: IEEE, 2017. https://doi.org/10.1109/ICASSP.2017.7952154.
Extended Capabilities
Version History
Introduced in R2024b