语义分割网络的代码生成
此示例说明如何为使用深度学习的图像分割应用程序生成代码。它使用 codegen 命令生成一个基于 SegNet [1] 的 DAG 网络对象执行预测的 MEX 函数。SegNet 是一种用于图像分割的深度学习网络。
第三方前提条件
必需
此示例生成 CUDA MEX,并具有以下第三方要求。
CUDA® 支持 NVIDIA® GPU 和兼容驱动。
可选
对于非 MEX 编译,如静态、动态库或可执行文件,此示例有以下附加要求。
NVIDIA 工具包。
NVIDIA cuDNN 库。
编译器和库的环境变量。有关详细信息,请参阅Third-Party Hardware (GPU Coder)和Setting Up the Prerequisite Products (GPU Coder)。
验证 GPU 环境
使用 coder.checkGpuInstall (GPU Coder) 函数验证运行此示例所需的编译器和库是否已正确设置。
envCfg = coder.gpuEnvConfig('host'); envCfg.DeepLibTarget = 'cudnn'; envCfg.DeepCodegen = 1; envCfg.Quiet = 1; coder.checkGpuInstall(envCfg);
分割网络
SegNet [1] 是一种卷积神经网络 (CNN),专为语义图像分割而设计。它是针对 CamVid [2] 数据集而训练并导入到 MATLAB® 中进行推断的深度编解码器多类像素级分割网络。SegNet [1] 经过训练,可以分割属于 11 个类的像素,包括天空、建筑物、电线杆、道路、人行道、树、标志符号、围栏、汽车、行人和骑车人。
有关在 MATLAB 中使用 CamVid [2] 数据集训练语义分割网络的信息,请参阅使用深度学习进行语义分割 (Computer Vision Toolbox)。
segnet_predict 入口函数
segnet_predict.m 入口函数以图像作为输入,并使用保存在 SegNet.mat 文件中的深度学习网络对图像执行预测。该函数将 SegNet.mat 文件中的网络对象加载到持久变量 mynet 中,并在后续的预测调用中重用该持久变量。
type('segnet_predict.m')function out = segnet_predict(in)
%#codegen
% Copyright 2018-2021 The MathWorks, Inc.
persistent mynet;
if isempty(mynet)
mynet = coder.loadDeepLearningNetwork('SegNet.mat');
end
% pass in input
out = predict(mynet,in);
获取预训练的 SegNet DAG 网络对象
net = getSegNet();
Downloading pretrained SegNet (107 MB)...
DAG 网络包含 91 个层,包括卷积层、批量归一化层、池化层、去池化层和像素分类输出层。使用 analyzeNetwork 函数显示深度学习网络架构的交互式可视化。
analyzeNetwork(net);
运行 MEX 代码生成
要为 segnet_predict.m 入口函数生成 CUDA 代码,请为 MEX 目标创建一个 GPU 代码配置对象,并将目标语言设置为 C++。使用 coder.DeepLearningConfig (GPU Coder) 函数创建一个 CuDNN 深度学习配置对象,并将其赋给 GPU 代码配置对象的 DeepLearningConfig 属性。运行 codegen 命令以指定输入大小为 [360,480,3]。该值对应于 SegNet 的输入层大小。
cfg = coder.gpuConfig('mex'); cfg.TargetLang = 'C++'; cfg.DeepLearningConfig = coder.DeepLearningConfig('cudnn'); codegen -config cfg segnet_predict -args {ones(360,480,3,'uint8')} -report
Code generation successful: View report
运行生成的 MEX
加载并显示输入图像。
im = imread('gpucoder_segnet_image.png');
imshow(im);
对输入图像调用 segnet_predict_mex。
predict_scores = segnet_predict_mex(im);
predict_scores 变量是一个三维矩阵,它具有 11 个通道,分别对应于每个类的像素级预测分数。使用最高预测分数计算通道以获得像素级标签。
[~,argmax] = max(predict_scores,[],3);
在输入图像上叠加分割标签并显示分割区域。
classes = [
"Sky"
"Building"
"Pole"
"Road"
"Pavement"
"Tree"
"SignSymbol"
"Fence"
"Car"
"Pedestrian"
"Bicyclist"
];
cmap = camvidColorMap();
SegmentedImage = labeloverlay(im,argmax,'ColorMap',cmap);
figure
imshow(SegmentedImage);
pixelLabelColorbar(cmap,classes);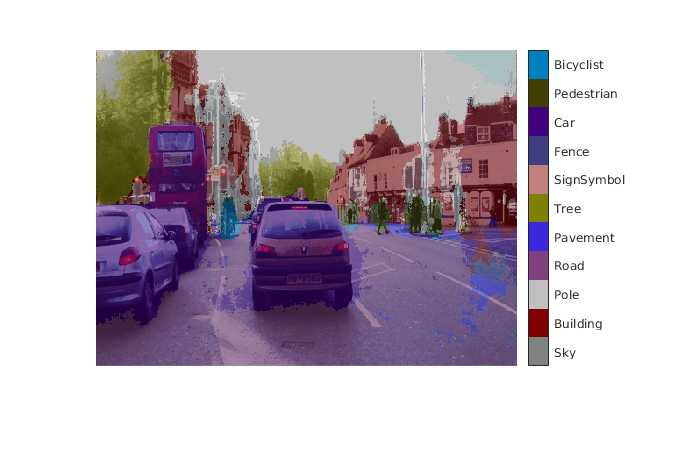
参考资料
[1] Badrinarayanan, Vijay, Alex Kendall, and Roberto Cipolla."SegNet:A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation." arXiv preprint arXiv:1511.00561, 2015.
[2] Brostow, Gabriel J., Julien Fauqueur, and Roberto Cipolla."Semantic object classes in video:A high-definition ground truth database."Pattern Recognition Letters Vol 30, Issue 2, 2009, pp 88-97.