filter
Filter disturbances through vector autoregression (VAR) model
Syntax
Description
Y = filter(Mdl,Z)Y containing the multivariate
response series, which results from filtering the underlying input numeric array
Z containing the multivariate disturbance series. The
series in Z are associated with the model innovations
process through the fully specified VAR(p) model
Mdl.
Tbl2 = filter(Mdl,Tbl1,Presample=Presample)Tbl2 containing the multivariate response series, which results from filtering the underlying multivariate disturbance series in the input table or timetable Tbl1. filter initializes the response series using the required table or timetable of presample data in Presample. Variables in Tbl1 are associated with the model innovations process through Mdl. (since R2022b)
filter selects the variables in Mdl.SeriesNames or all variables in Tbl1. To select different disturbance variables in Tbl1 to filter through the model, use the DisturbanceVariables name-value argument. filter selects the same variables for Presample by default, but you can select different variables by using the PresampleResponseVariables name-value argument.
[___] = filter(___,
specifies options using one or more name-value arguments in
addition to any of the input argument combinations in previous syntaxes.
Name=Value)filter returns the output argument combination for the
corresponding input arguments. For example, filter(Mdl,Z,Y0=PS,X=Exo) filters
the numeric array of disturbances Z through the
VAR(p) model Mdl, and specifies the
numeric array of presample response data PS and the numeric
matrix of exogenous predictor data Exo for the model
regression component.
Examples
Fit a VAR(4) model to the consumer price index (CPI) and unemployment rate data. Then, simulate responses by filtering a random series of Gaussian distributed disturbances through the estimated model. Supply the disturbances as a numeric matrix.
Load the Data_USEconModel data set.
load Data_USEconModelPlot the two series on separate plots.
figure; plot(DataTimeTable.Time,DataTimeTable.CPIAUCSL); title("Consumer Price Index") ylabel("Index") xlabel("Date")

figure; plot(DataTimeTable.Time,DataTimeTable.UNRATE); title("Unemployment Rate") ylabel("Percent") xlabel("Date")
Stabilize the CPI by converting it to a series of growth rates, include a missing value at the beginning of the series to maintain time consistency among the series. Create a new data set containing the transformed variables, and remove all rows containing at least one missing observation.
RCPI = [NaN; price2ret(DataTimeTable.CPIAUCSL)]; UNRATE = DataTimeTable.UNRATE; DTT = timetable(RCPI,UNRATE,RowTimes=DataTimeTable.Time); DTT = rmmissing(DTT);
Create a default VAR(4) model by using the shorthand syntax.
Mdl = varm(2,4);
Estimate the model using the entire data set.
EstMdl = estimate(Mdl,DTT.Variables);
EstMdl is a fully specified, estimated varm model object.
Generate a numobs-by-2 series of random Gaussian distributed values, where numobs is the number of observations in the data.
numobs = size(DTT,1);
rng(1) % For reproducibility
Z = mvnrnd(zeros(Mdl.NumSeries,1),eye(Mdl.NumSeries),numobs);To simulate responses, filter the disturbances through the estimated model.
Y = filter(EstMdl,Z);
Y is a 245-by-2 matrix of simulated responses. The first and second columns contain the simulated CPI growth rate and unemployment rate, respectively.
Plot the simulated and true responses.
figure plot(DTT.Time,Y(:,1)) hold on plot(DTT.Time,DTT.RCPI) ylabel("Growth Rate") xlabel("Date") title("CPI Growth Rate") legend("Simulation","True")
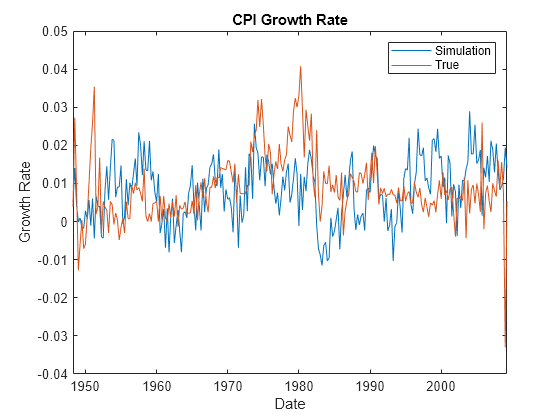
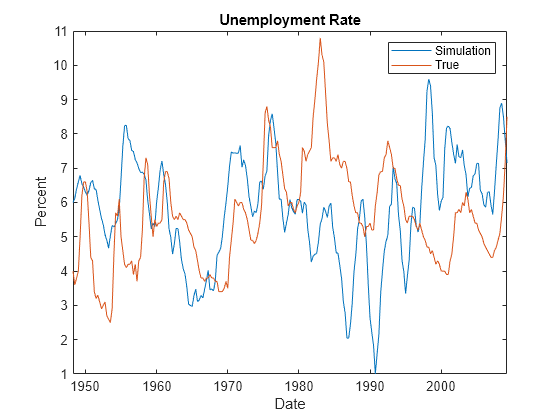
figure plot(DTT.Time,Y(:,2)) hold on plot(DTT.Time,DTT.UNRATE) ylabel("Percent") xlabel("Date") title("Unemployment Rate") legend("Simulation","True") hold off
Estimate a VAR(4) model of the consumer price index (CPI), the unemployment rate, and the gross domestic product (GDP). Include a linear regression component containing the current quarter and the last four quarters of government consumption expenditures and investment (GCE). Pass multiple multivariate Gaussian disturbance paths through the estimated model.
Load the Data_USEconModel data set. Compute the real GDP.
load Data_USEconModel
DataTimeTable.RGDP = DataTimeTable.GDP./DataTimeTable.GDPDEF*100;Plot all variables on separate plots.
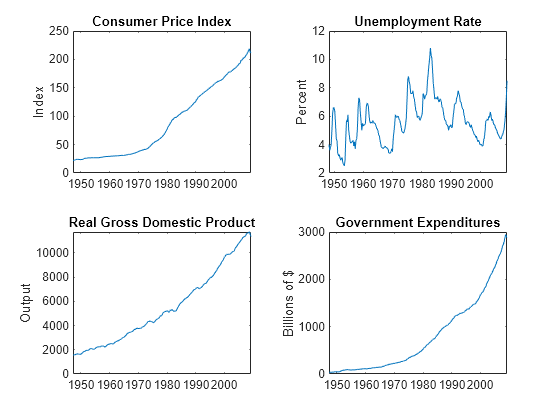
figure tiledlayout(2,2) nexttile plot(DataTimeTable.Time,DataTimeTable.CPIAUCSL); ylabel('Index') title('Consumer Price Index') nexttile plot(DataTimeTable.Time,DataTimeTable.UNRATE); ylabel('Percent') title('Unemployment Rate') nexttile plot(DataTimeTable.Time,DataTimeTable.RGDP); ylabel('Output') title('Real Gross Domestic Product') nexttile plot(DataTimeTable.Time,DataTimeTable.GCE); ylabel('Billions of $') title('Government Expenditures')
Stabilize the CPI, GDP, and GCE by converting each to a series of growth rates. Synchronize the unemployment rate series with the others by removing its first observation.
inputVariables = {'CPIAUCSL' 'RGDP' 'GCE'};
Data = varfun(@price2ret,DataTimeTable,'InputVariables',inputVariables);
Data.Properties.VariableNames = inputVariables;
Data.UNRATE = DataTimeTable.UNRATE(2:end);Expand the GCE rate series to a matrix that includes its current value and up through four lagged values. Remove the GCE variable from Data.
rgcelag4 = lagmatrix(Data.GCE,0:4); Data.GCE = [];
Create a default VAR(4) model by using the shorthand syntax.
Mdl = varm(3,4);
Mdl.SeriesNames = {'rcpi' 'unrate' 'rgdpg'};Estimate the model using the entire sample. Specify the GCE matrix as data for the regression component.
EstMdl = estimate(Mdl,Data.Variables,'X',rgcelag4);Generate 1000 paths of numobs observations from a 3-D Gaussian distribution. numobs is the number of observations in the data without any missing values.
numpaths = 1000; numseries = Mdl.NumSeries; idx = all(~ismissing([Data array2table(rgcelag4)]),2); numobs = sum(idx); rng(1); Z = mvnrnd(zeros(Mdl.NumSeries,1),eye(Mdl.NumSeries),numobs*numpaths); Z = reshape(Z,[numobs,3,numpaths]);
Filter the disturbances through the estimated model. Supply the predictor data. Return the innovations (scaled disturbances).
[Y,E] = filter(EstMdl,Z,'X',rgcelag4);Y and E are 244-by-3-by-1000 matrices of filtered responses and scaled disturbances, respectively. The columns correspond to the CPI growth rate, unemployment rate, and GDP growth rate, respectively. filter applies the same predictor data to all paths.
For each time point, compute the mean vector of the filtered responses among all paths.
MeanFilt = mean(Y,3);
MeanFilt is a 244-by-3 matrix containing the average of the responses at each time point.
Plot the filtered responses, their averages, and the data.
Data = Data(idx,:); figure tiledlayout(2,2) for j = 1:Mdl.NumSeries nexttile plot(Data.Time,squeeze(Y(:,j,:)),'Color',[0.8,0.8,0.8]) title(Mdl.SeriesNames{j}); hold on h1 = plot(Data.Time,Data{:,j}); h2 = plot(Data.Time,MeanFilt(:,j)); hold off end hl = legend([h1 h2],'Data','Mean'); hl.Location = 'none'; hl.Position = [0.6 0.25 hl.Position(3:4)];

Since R2022b
Fit a VAR(4) model to the consumer price index (CPI) and unemployment rate data. Then, simulate responses by filtering multiple random paths of Gaussian distributed disturbances through the estimated model. Supply the disturbances in a timetable. This example is based on Filter Numeric Matrix of Disturbances Through VAR(4) Model.
Load and Preprocess Data
Load the Data_USEconModel data set.
load Data_USEconModelPreprocess the data. Regularize the time base.
RCPI = [NaN; price2ret(DataTimeTable.CPIAUCSL)]; UNRATE = DataTimeTable.UNRATE; DTT = timetable(RCPI,UNRATE,RowTimes=DataTimeTable.Time); DTT = rmmissing(DTT); dt = DTT.Time; dt = dateshift(dt,"start","quarter"); DTT.Time = dt;
Fit Model to Data
Estimate the model using the entire data set.
Mdl = varm(2,4); Mdl.SeriesNames = DTT.Properties.VariableNames; EstMdl = estimate(Mdl,DTT);
Simulate Paths of Disturbances
Generate a numobs-by-numseries-by-numpaths array of independent random Gaussian distributed values, where numobs is the number of observations in the data, numseries the number of response series 2, and numpaths is 100.
rng(1) % For reproducibility
numobs = height(DTT);
numseries = EstMdl.NumSeries;
numpaths = 100;
Z = mvnrnd(zeros(numseries,1),eye(numseries),numobs*numpaths);
Z = reshape(Z,numobs,numseries,numpaths);
DTT.ZRCPI = squeeze(Z(:,1,:));
DTT.ZUNRATE = squeeze(Z(:,2,:));
head(DTT) Time RCPI UNRATE ZRCPI ZUNRATE
_____ __________ ______ ____________ ____________
Q1-48 0.0038371 4 1×100 double 1×100 double
Q2-48 0.027284 3.6 1×100 double 1×100 double
Q3-48 0.0086581 3.8 1×100 double 1×100 double
Q4-48 -0.012807 4 1×100 double 1×100 double
Q1-49 -0.0058382 5 1×100 double 1×100 double
Q2-49 0.00041815 6.2 1×100 double 1×100 double
Q3-49 -0.0071324 6.6 1×100 double 1×100 double
Q4-49 -0.0059122 6.6 1×100 double 1×100 double
Filter Disturbances Through Model
When you filter disturbances by using a timetable, filter requires a presample. Split the timetable into presample and in-sample data sets. The presample data is the initial EstMdl.P observations, and the in-sample data set contains the remaining observations.
Presample = DTT(1:EstMdl.P,:); InSample = DTT((EstMdl.P + 1):end,:);
Simulate response paths by filtering the in-sample disturbances through the estimated model. Specify the variable names of the disturbance series, the presample data, and the response variable names in the presample.
Tbl2 = filter(EstMdl,InSample,DisturbanceVariables=["ZRCPI" "ZUNRATE"], ... Presample=Presample,PresampleResponseVariables=EstMdl.SeriesNames); size(Tbl2)
ans = 1×2
241 8
head(Tbl2)
Time RCPI UNRATE ZRCPI ZUNRATE RCPI_Responses UNRATE_Responses RCPI_Innovations UNRATE_Innovations
_____ __________ ______ ____________ ____________ ______________ ________________ ________________ __________________
Q1-49 -0.0058382 5 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double
Q2-49 0.00041815 6.2 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double
Q3-49 -0.0071324 6.6 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double
Q4-49 -0.0059122 6.6 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double
Q1-50 0.0012698 6.3 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double
Q2-50 0.010101 5.4 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double
Q3-50 0.01908 4.4 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double
Q4-50 0.025954 4.3 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double 1×100 double
Tbl2 is a 241-by-2 matrix of in-sample data, paths of simulated disturbances, paths of filtered responses (variables names appended with _Responses), and paths of innovations (variables with name appended with _Innovations).
Plot the paths of simulated responses with the true responses.
figure p1 = plot(Tbl2.Time,Tbl2.RCPI_Responses,Color=[0.5 0.5 0.5]); hold on p2 = plot(Tbl2.Time,Tbl2.RCPI,LineWidth=2); ylabel("Growth Rate") xlabel("Date") title("CPI Growth Rate") legend([p1(1) p2],["Simulated" "Observed"]) hold off

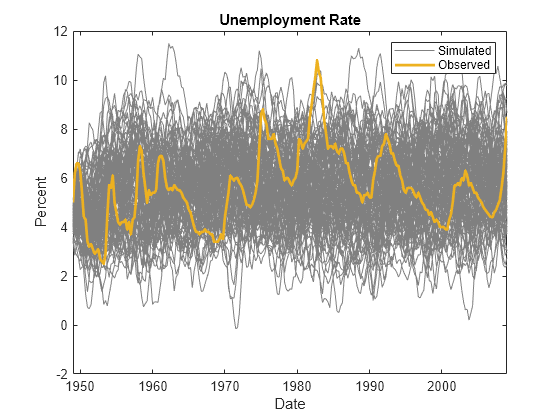
figure p1 = plot(Tbl2.Time,Tbl2.UNRATE_Responses,Color=[0.5 0.5 0.5]); hold on p2 = plot(Tbl2.Time,Tbl2.UNRATE,LineWidth=2); ylabel("Percent") xlabel("Date") title("Unemployment Rate") legend([p1(1) p2],["Simulated" "Observed"]) hold off
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
filtercomputes filtered responsesYand innovationsEusing this process for each pagejinZ.If
Scaleistrue, thenE(:,:,=j)L*Z(:,:,, wherej)L=chol(Mdl.Covariance,'lower'). Otherwise,E(:,:,=j)Z(:,:,. Set et =j)E(:,:,.j)Y(:,:,is yt in this system of equations.j)For variable definitions, see More About.
filtergeneralizessimulate. Both functions filter a disturbance series through a model to produce responses and innovations. However, whereassimulategenerates a series of mean-zero, unit-variance, independent Gaussian disturbancesZto form innovationsE=L*Z,filterenables you to supply disturbances from any distribution.filteruses this process to determine the time origin t0 of models that include linear time trends:If you specify
Zand you do not specify a presample by using theY0name-value argument, t0 = 0.Otherwise, if you specify
Tbl1or you supply a presample,filtersets t0 tosize(–Y0,1)Mdl.P, whereY0Y0orPresample. Therefore, the times in the trend component are t = t0 + 1, t0 + 2,..., t0 +numobs, wherenumobsis the effective sample size (size(Z,1), afterfilterremoves missing values, orheight(Tbl1)). This convention is consistent with the default behavior of model estimation, in whichestimateremoves the firstMdl.Presponses, reducing the effective sample size. Althoughfilterexplicitly uses the firstMdl.Ppresample responses inY0Y0Z, excluding missing values, orTbl1) determines t0.
References
[1] Hamilton, James D. Time Series Analysis. Princeton, NJ: Princeton University Press, 1994.
[2] Johansen, S. Likelihood-Based Inference in Cointegrated Vector Autoregressive Models. Oxford: Oxford University Press, 1995.
[3] Juselius, K. The Cointegrated VAR Model. Oxford: Oxford University Press, 2006.
[4] Lütkepohl, H. New Introduction to Multiple Time Series Analysis. Berlin: Springer, 2005.