Portfolios with Missing Data
This example shows how to use the missing data algorithms for portfolio optimization and for valuation. This example works with five years of daily total return data for 12 computer technology stocks, with six hardware and six software companies. The example estimates the mean and covariance matrix for these stocks, forms efficient frontiers with both a naïve approach and the ECM approach, and then compares results.
Load the data file.
load ecmtechdemo.matThis data file contains these three quantities:
Assetsis a cell array of the tickers for the 12 stocks in the example.Datais a1254-by-12matrix of 1254 daily total returns for each of the 12 stocks.Datesis a1254-by-1column vector of the dates associated with the data.
The time period for the data extends from April 19, 2000 to April 18, 2005. The sixth stock in Assets is Google (GOOG), which started trading on August 19, 2004. So, all returns before August 20, 2004 are missing and represented as NaNs. Also, Amazon (AMZN) had a few days with missing values scattered throughout the past five years.
A naïve approach to the estimation of the mean and covariance for these 12 assets is to eliminate all days that have missing values for any of the 12 assets. Use the function ecmninit with the 'nanskip' option to do this.
[NaNMean, NaNCovar] = ecmninit(Data,'nanskip');Contrast the result of this approach with using all available data and the function ecmnmle to compute the mean and covariance. First, call ecmnmle with no output arguments to establish that enough data is available to obtain meaningful estimates.
ecmnmle(Data);
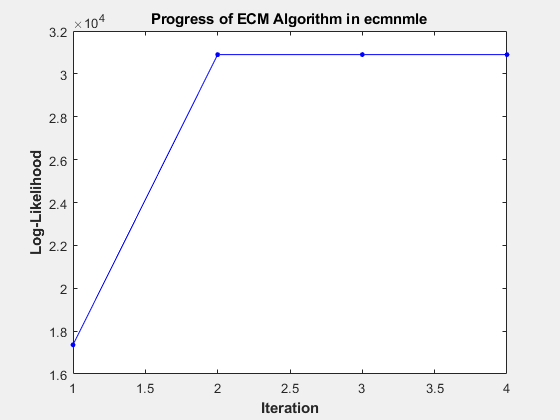
This plot shows that, even with almost 87% of the Google data being NaN values, the algorithm converges after only four iterations.
Estimate the mean and covariance as computed by ecmnmle.
[ECMMean, ECMCovar] = ecmnmle(Data)
ECMMean = 12×1
0.0008
0.0008
-0.0005
0.0002
0.0011
0.0038
-0.0003
-0.0000
-0.0003
-0.0000
-0.0003
0.0004
ECMCovar = 12×12
0.0012 0.0005 0.0006 0.0005 0.0005 0.0003 0.0005 0.0003 0.0006 0.0003 0.0005 0.0006
0.0005 0.0024 0.0007 0.0006 0.0010 0.0004 0.0005 0.0003 0.0006 0.0004 0.0006 0.0012
0.0006 0.0007 0.0013 0.0007 0.0007 0.0003 0.0006 0.0004 0.0008 0.0005 0.0008 0.0008
0.0005 0.0006 0.0007 0.0009 0.0006 0.0002 0.0005 0.0003 0.0007 0.0004 0.0005 0.0007
0.0005 0.0010 0.0007 0.0006 0.0016 0.0006 0.0005 0.0003 0.0006 0.0004 0.0007 0.0011
0.0003 0.0004 0.0003 0.0002 0.0006 0.0022 0.0001 0.0002 0.0002 0.0001 0.0003 0.0016
0.0005 0.0005 0.0006 0.0005 0.0005 0.0001 0.0009 0.0003 0.0005 0.0004 0.0005 0.0006
0.0003 0.0003 0.0004 0.0003 0.0003 0.0002 0.0003 0.0005 0.0004 0.0003 0.0004 0.0004
0.0006 0.0006 0.0008 0.0007 0.0006 0.0002 0.0005 0.0004 0.0011 0.0005 0.0007 0.0007
0.0003 0.0004 0.0005 0.0004 0.0004 0.0001 0.0004 0.0003 0.0005 0.0006 0.0004 0.0005
0.0005 0.0006 0.0008 0.0005 0.0007 0.0003 0.0005 0.0004 0.0007 0.0004 0.0013 0.0007
0.0006 0.0012 0.0008 0.0007 0.0011 0.0016 0.0006 0.0004 0.0007 0.0005 0.0007 0.0020
Given estimates for the mean and covariance of asset returns derived from the naïve and ECM approaches, estimate portfolios, and associated expected returns and risks on the efficient frontier for both approaches.
[ECMRisk, ECMReturn, ECMWts] = portopt(ECMMean',ECMCovar,10); [NaNRisk, NaNReturn, NaNWts] = portopt(NaNMean',NaNCovar,10);
Plot the results on the same graph to illustrate the differences.
figure(gcf) plot(ECMRisk,ECMReturn,'-bo','MarkerFaceColor','b','MarkerSize', 3); hold on plot(NaNRisk,NaNReturn,'-ro','MarkerFaceColor','r','MarkerSize', 3); title('\bfEfficient Frontiers Under Various Assumptions'); legend('ECM','NaN','Location','SouthEast'); xlabel('\bfStd. Deviation of Returns'); ylabel('\bfMean of Returns'); hold off
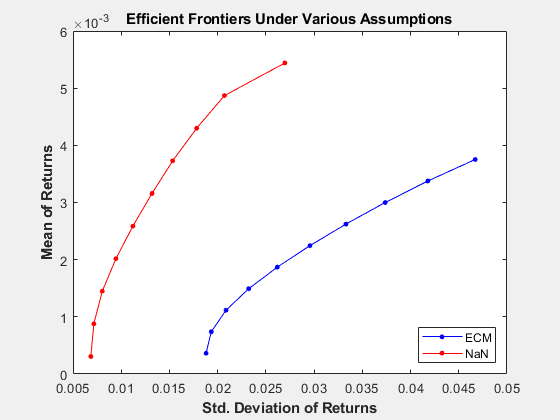
Clearly, the naïve approach is optimistic about the risk-return trade-offs for this universe of 12 technology stocks. The proof, however, lies in the portfolio weights. To view the weights:
Assets
Assets = 1×12 cell
{'AAPL'} {'AMZN'} {'CSCO'} {'DELL'} {'EBAY'} {'GOOG'} {'HPQ'} {'IBM'} {'INTC'} {'MSFT'} {'ORCL'} {'YHOO'}
ECMWts
ECMWts = 10×12
0.0358 0.0011 0.0000 0.0000 0.0000 0.0989 0.0535 0.4676 0.0000 0.3431 0.0000 0.0000
0.0654 0.0110 0.0000 0.0000 0.0000 0.1877 0.0179 0.3899 0.0000 0.3282 0.0000 0.0000
0.0923 0.0194 0.0000 0.0000 0.0000 0.2784 0.0000 0.3025 0.0000 0.3074 0.0000 0.0000
0.1165 0.0264 0.0000 0.0000 0.0000 0.3712 0.0000 0.2054 0.0000 0.2806 0.0000 0.0000
0.1407 0.0334 0.0000 0.0000 0.0000 0.4639 0.0000 0.1083 0.0000 0.2538 0.0000 0.0000
0.1648 0.0403 0.0000 0.0000 0.0000 0.5566 0.0000 0.0111 0.0000 0.2271 0.0000 0.0000
0.1755 0.0457 0.0000 0.0000 0.0000 0.6532 0.0000 0.0000 0.0000 0.1255 0.0000 0.0000
0.1845 0.0509 0.0000 0.0000 0.0000 0.7502 0.0000 0.0000 0.0000 0.0143 0.0000 0.0000
0.1093 0.0174 0.0000 0.0000 0.0000 0.8733 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
0 0 0 0 0 1.0000 0 0 0 0 0 0
NaNWts
NaNWts = 10×12
0.0000 0.0000 0.0000 0.1185 0.0000 0.0522 0.0824 0.1779 0.0000 0.5691 0.0000 0.0000
0.0576 0.0000 0.0000 0.1219 0.0000 0.0854 0.1274 0.0460 0.0000 0.5617 0.0000 0.0000
0.1248 0.0000 0.0000 0.0952 0.0000 0.1195 0.1674 0.0000 0.0000 0.4802 0.0129 0.0000
0.1969 0.0000 0.0000 0.0529 0.0000 0.1551 0.2056 0.0000 0.0000 0.3621 0.0274 0.0000
0.2690 0.0000 0.0000 0.0105 0.0000 0.1906 0.2438 0.0000 0.0000 0.2441 0.0419 0.0000
0.3414 0.0000 0.0000 0.0000 0.0000 0.2265 0.2782 0.0000 0.0000 0.0988 0.0551 0.0000
0.4235 0.0000 0.0000 0.0000 0.0000 0.2639 0.2788 0.0000 0.0000 0.0000 0.0337 0.0000
0.5245 0.0000 0.0000 0.0000 0.0000 0.3034 0.1721 0.0000 0.0000 0.0000 0.0000 0.0000
0.6269 0.0000 0.0000 0.0000 0.0000 0.3425 0.0306 0.0000 0.0000 0.0000 0.0000 0.0000
1.0000 0 0 0 0 0 0 0 0 0 0 0
The naïve portfolios in NaNWts tend to favor AAPL which happened to do well over the period from the Google IPO to the end of the estimation period, while the ECM portfolios in ECMWts tend to underweight AAPL and to recommend increased weights in GOOG relative to the naïve weights.
To evaluate the impact of the estimation error and, in particular, the effect of missing data, use ecmnstd to calculate standard errors. Although it is possible to estimate the standard errors for both the mean and covariance, the standard errors for the mean estimates alone are usually the main quantities of interest.
StdMeanF = ecmnstd(Data,ECMMean,ECMCovar,'fisher');Calculate standard errors that use the data-generated Hessian matrix (which accounts for the possible loss of information due to missing data) with the option 'hessian'.
StdMeanH = ecmnstd(Data,ECMMean,ECMCovar,'hessian');The difference in the standard errors shows the increase in uncertainty of estimation of asset expected returns due to missing data. To view the differences:
Assets
Assets = 1×12 cell
{'AAPL'} {'AMZN'} {'CSCO'} {'DELL'} {'EBAY'} {'GOOG'} {'HPQ'} {'IBM'} {'INTC'} {'MSFT'} {'ORCL'} {'YHOO'}
StdMeanH'
ans = 1×12
0.0010 0.0014 0.0010 0.0009 0.0011 0.0021 0.0009 0.0006 0.0009 0.0007 0.0010 0.0012
StdMeanF'
ans = 1×12
0.0010 0.0014 0.0010 0.0009 0.0011 0.0013 0.0009 0.0006 0.0009 0.0007 0.0010 0.0012
StdMeanH' - StdMeanF'
ans = 1×12
10-3 ×
-0.0000 0.0021 -0.0000 -0.0000 -0.0000 0.7742 -0.0000 -0.0000 -0.0000 -0.0000 -0.0000 -0.0000
The two assets with missing data, AMZN and GOOG, are the only assets to have differences due to missing information.
See Also
mvnrmle | mvnrstd | mvnrfish | mvnrobj | ecmmvnrmle | ecmmvnrstd | ecmmvnrfish | ecmmvnrobj | ecmlsrmle | ecmlsrobj | ecmmvnrstd | ecmmvnrfish | ecmnmle | ecmnstd | ecmnfish | ecmnhess | ecmnobj | convert2sur | ecmninit