goodnessOfFit
用于分析和验证辨识模型的测试数据和参考数据之间的拟合优度
说明
goodnessOfFit 返回表示测试数据集和参考数据集之间的误差范数的拟合值。如果您想将仿真模型输出与测量数据进行比较和可视化,另请参阅 compare。
示例
找到测量输出数目据和估计模型的仿真输出之间的拟合优度。
获取测量的输出值。
load iddata1 z1 yref = z1.y;
z1 是一个包含测量的输入-输出数目据的 iddata 对象。z1.y 是测量的输出。
估计二阶传递函数模型并仿真模型输出 y_est。
sys = tfest(z1,2); y_est = sim(sys,z1(:,[],:));
计算测量输出和估计输出之间的拟合优度或误差范数。将归一化均方根误差 (NRMSE) 指定为成本函数。
cost_func = 'NRMSE';
y = y_est.y;
fit = goodnessOfFit(y,yref,cost_func) fit = 0.2943
或者,您可以使用compare来计算拟合度。compare 使用 NRMSE 成本函数,并使用误差范数的补码来表示拟合百分比。因此,compare 和 goodnessOfFit 之间的拟合关系是 。compare 结果 100% 相当于 goodnessOfFit 结果 0。
指定初始条件为零,以匹配 goodnessOfFit 假设的初始条件。
opt = compareOptions('InitialCondition','z'); compare(z1,sys,opt);
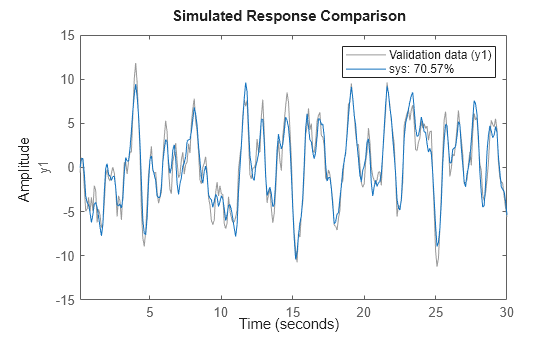
拟合结果是等效的。
找出两个模型的测量输出和估计输出之间的拟合优度。
从 z2 获取输入-输出测量值 iddata2。将测量的输出复制到参考输出 yref。
load iddata2 z2 yref = z2.y;
使用 z2 估计二阶和四阶传递函数模型。
sys2 = tfest(z2,2); sys4 = tfest(z2,4);
仿真两个系统以获得估计输出。
y_sim2 = sim(sys2,z2(:,[],:)); y2 = y_sim2.y; y_sim4 = sim(sys4,z2(:,[],:)); y4 = y_sim4.y;
根据参考和估计输出创建元胞数组。两个模型比较的参考数据集是相同的,因此创建相同的参考单元。
yrefc = {yref yref};
yc = {y2 y4};计算三个成本函数的 fit 值。
fit_nrmse = goodnessOfFit(yc,yrefc,'NRMSE')fit_nrmse = 1×2
0.1429 0.1345
fit_nmse = goodnessOfFit(yc,yrefc,'NMSE')fit_nmse = 1×2
0.0204 0.0181
fit_mse = goodnessOfFit(yc,yrefc,'MSE')fit_mse = 1×2
1.0811 0.9586
拟合值 0 表示参考输出和估计输出之间完美拟合。随着拟合优度的降低,拟合值会上升。对于所有三个成本函数,四阶模型比二阶模型产生更好的拟合效果。