histcounts2
二元直方图 bin 计数
语法
说明
示例
输入参数
名称-值参数
输出参量
bin 计数,以数组形式返回。
分 bin 方案包括每个 bin 的 x 维和 y 维的左边界,以及最后一个 bin 的 x 维和 y 维的右边界。
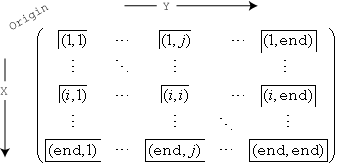
例如,bin (1,1) 包括位于每个维度中第一个边界上的值,右下角的最后一个 bin 包括位于其任何边界上的值。
x 维度的 bin 边界,以向量形式返回。第一个元素是 x 维度中第一个 bin 的左边界。最后一个元素是 x 维度中最后一个 bin 的右边界。
y 维度的 bin 边界,以向量形式返回。第一个元素是 y 维度中第一个 bin 的左边界。最后一个元素是 y 维度中最后一个 bin 的右边界。
x 维度中的 bin 索引,以数组形式返回,数组大小与 X 相同。binX 和 binY 中的对应元素说明哪个编号的 bin 包含 X 和 Y 中的对应值。binX 和 binY 中的 0 值表示元素不属于任何 bin(例如 NaN 值)。
例如,binX(1) 和 binY(1) 描述值 [X(1),Y(1)] 的 bin 位置。
y 维度中的 bin 索引,以数组形式返回,数组大小与 Y 相同。binX 和 binY 中的对应元素说明哪个编号的 bin 包含 X 和 Y 中的对应值。binX 和 binY 中的 0 值表示元素不属于任何 bin(例如 NaN 值)。
例如,binX(1) 和 binY(1) 描述值 [X(1),Y(1)] 的 bin 位置。
扩展功能
版本历史记录
在 R2015b 中推出另请参阅
histogram | histcounts | discretize | histogram2 | morebins | fewerbins