kde
说明
示例
生成一些正态分布数据。
rng(0,"twister") % For reproducibility a = randn(100,1);
估计样本数据的 pdf。
[fp,xfp] = kde(a);
fp 包含估计的 pdf 在 xfp 中的计算点处的值。
估计样本数据的 cdf。
[fc,xfc] = kde(a,ProbabilityFcn="cdf");fc 包含估计的 cdf 在 xfc 中的计算点处的值。xfc 和 xfp 包含相同的计算点,因为它们都是使用 a 中的样本数据计算的。
在计算点处计算正态分布的 pdf 和 cdf。
np = (1/sqrt(2*pi))*exp(-.5*(xfp.^2)); nc = 0.5*(1+erf(xfc/sqrt(2)));
绘制估计的 pdf 与正态分布 pdf 的对比图。
plot(xfp,fp,"-",xfp,np,"--") legend("kde estimate","Normal density")
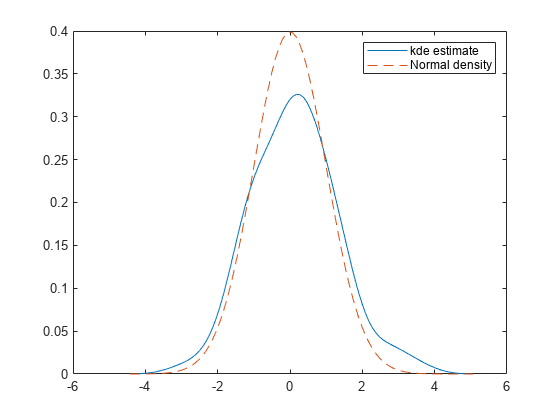
绘制估计的 pdf 与正态分布 pdf 的对比图。
figure plot(xfc,fc,"-",xfc,nc,"--") legend("kde estimate","Normal cumulative",Location="northwest")
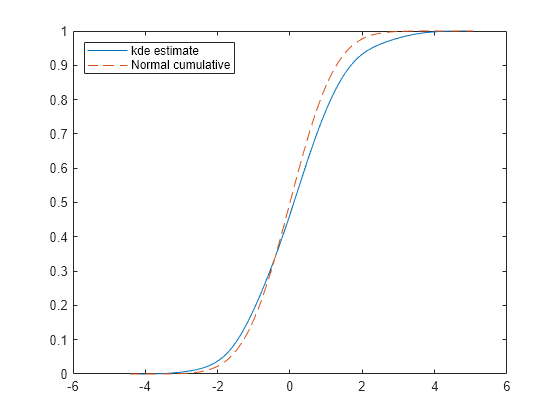
绘图显示,估计的 pdf 和 cdf 的形状与标准正态分布的 pdf 和 cdf 的形状相似。
生成一些正态分布数据。
rng(0,"twister") % For reproducibility a = randn(100,1);
估计样本数据的 pdf。默认情况下,kde 使用正态逼近方法计算核平滑函数的带宽。
[fn,xfn,bwn] = kde(a);
fn 包含估计的 pdf 在 xfn 中的计算点处的值,bwn 是核平滑函数的带宽。
使用插入法估计 pdf,并显示与每个估计的 pdf 关联的带宽。
[p,xp,bwp] = kde(a,Bandwidth="plug-in");
[bwn,bwp]ans = 1×2
0.4958 0.5751
使用正态逼近方法计算的带宽小于使用插入法计算的带宽。
绘制估计的 pdf。
plot(xfn,fn) hold on plot(xp,p) legend("normal-approx","plug-in")
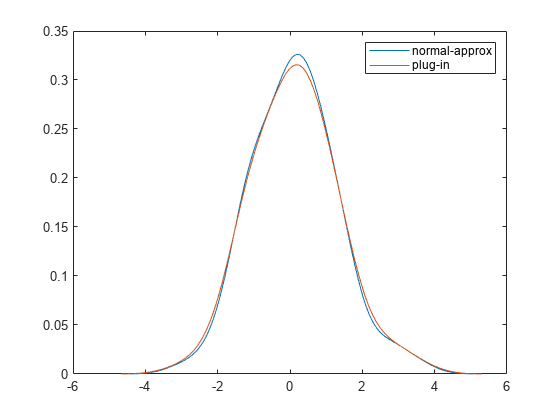
估计的 pdf 具有正态分布的典型形状。与正态逼近方法对应的 pdf 峰值高于与插入法对应的 pdf 峰值。
生成一些双峰样本数据。
rng(0,"twister") % For reproducibility a = [randn(100,1)-5; randn(20,1)+5];
使用默认 "normal" 核平滑函数估计样本数据的 pdf。使用 "box"、"triangle" 和 "parabolic" 核平滑函数计算 pdf 的另外三个估计值。
[f1,xf1] = kde(a); [f2,xf2] = kde(a,Kernel="box"); [f3,xf3] = kde(a,Kernel="triangle"); [f4,xf4] = kde(a,Kernel="parabolic");
xf1、xf2、xf3 和 xf4 包含相同的计算点,因为它们都是使用 a 中的样本数据计算的。f1、f2、f3 和 f4 包含每个估计的 pdf 在计算点处的值。
绘制估计的 pdf。
tiledlayout(2,2) nexttile plot(xf1,f1) % normal nexttile plot(xf2,f2) % box nexttile plot(xf3,f3) % triangle nexttile plot(xf4,f4) % parabolic

绘图显示,四个估计的 pdf 具有相似的垂直范围,且每个估计的 pdf 有两个峰值。使用 "box" 核计算的 pdf 在四个估计的 pdf 中显得最不平滑。
输入参数
名称-值参数
输出参量
详细信息
参考
[1] Botev, Z. I., J. F. Grotowski, and D. P. Kroese. "Kernel Density Estimation via Diffusion." The Annals of Statistics, vol. 38, no. 5 (October 1, 2010). https://projecteuclid.org/journals/annals-of-statistics/volume-38/issue-5/Kernel-density-estimation-via-diffusion/10.1214/10-AOS799.full
[2] Bowman, A. W., and A. Azzalini. "Applied Smoothing Techniques for Data Analysis." New York: Oxford University Press Inc., 1997.
[3] Hill, P. D. "Kernel estimation of a distribution function." Communications in Statistics - Theory and Methods. 14, no. 3(January 1985): 605–620.
[4] Jones, M. C. "Simple boundary correction for kernel density estimation." Statistics and Computing. no. 3(September 1993): 135–146.
[5] Silverman, B. W. "Density Estimation for Statistics and Data Analysis." Chapman & Hall/CRC, 1986.
版本历史记录
在 R2023b 中推出另请参阅
函数
histogram|histcounts(Statistics and Machine Learning Toolbox) |ksdensity(Statistics and Machine Learning Toolbox)
主题
- Kernel Distribution (Statistics and Machine Learning Toolbox)
- Nonparametric and Empirical Probability Distributions (Statistics and Machine Learning Toolbox)