ksdensity
用于一元数据和二元数据的核平滑函数估计
语法
说明
示例
从两个正态分布的混合生成样本数据集。
rng('default') % For reproducibility x = [randn(30,1); 5+randn(30,1)];
绘制估计密度。
[f,xi] = ksdensity(x); figure plot(xi,f);
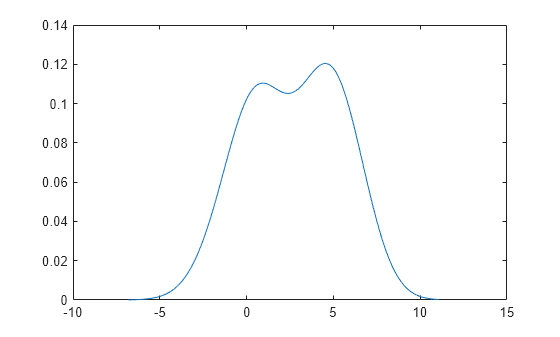
密度估计显示样本呈双峰分布。
从半正态分布生成非负样本数据集。
rng('default') % For reproducibility pd = makedist('HalfNormal','mu',0,'sigma',1); x = random(pd,100,1);
通过使用 'BoundaryCorrection' 名称-值对组参量,使用两种不同的边界校正方法(对数变换和反射)估计 pdf。
pts = linspace(0,5,1000); % points to evaluate the estimator [f1,xi1] = ksdensity(x,pts,'Support','positive'); [f2,xi2] = ksdensity(x,pts,'Support','positive','BoundaryCorrection','reflection');
绘制两个估计的 pdf。
plot(xi1,f1,xi2,f2) lgd = legend('log','reflection'); title(lgd, 'Boundary Correction Method') xl = xlim; xlim([xl(1)-0.25 xl(2)])
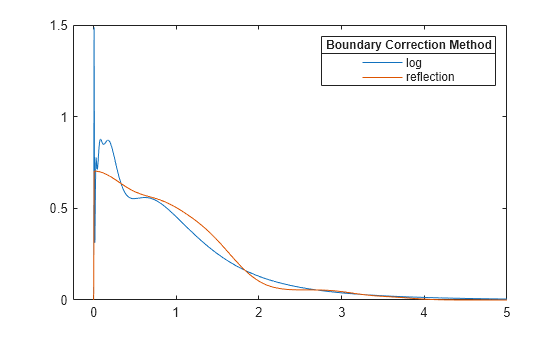
当您指定正支持或有界支持时,ksdensity 使用边界校正方法。默认边界校正方法是对数变换。当 ksdensity 将支持变换回来时,它会在核密度估计器中引入 1/x 项。因此,估计在 x = 0 附近有峰值。另一方面,反射方法不会在边界附近导致不想要的峰值。
加载样本数据。
load hospital计算并绘制在指定值集处计算的估计 cdf。
pts = (min(hospital.Weight):2:max(hospital.Weight)); figure() ecdf(hospital.Weight) hold on [f,xi,bw] = ksdensity(hospital.Weight,pts,'Support','positive',... 'Function','cdf'); plot(xi,f,'-g','LineWidth',2) legend('empirical cdf','kernel-bw:default','Location','northwest') xlabel('Patient weights') ylabel('Estimated cdf')
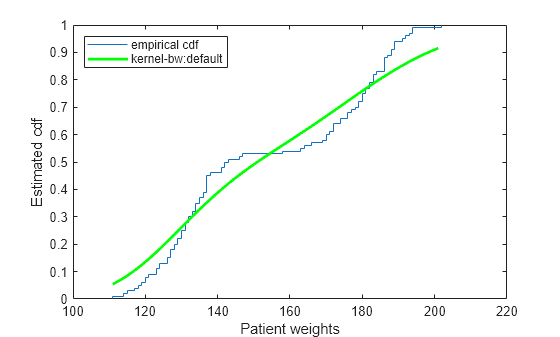
ksdensity 似乎对累积分布函数估计进行了过度平滑。带宽越小的估计可能产生越接近经验累积分布函数的估计。
返回平滑窗的带宽。
bw
bw = 0.1070
使用较小的带宽绘制累积分布函数估计。
[f,xi] = ksdensity(hospital.Weight,pts,'Support','positive',... 'Function','cdf','Bandwidth',0.05); plot(xi,f,'--r','LineWidth',2) legend('empirical cdf','kernel-bw:default','kernel-bw:0.05',... 'Location','northwest') hold off
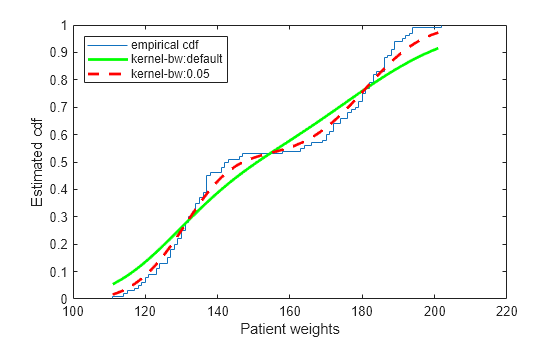
带宽越小的 ksdensity 估计越匹配经验累积分布函数。
加载样本数据。
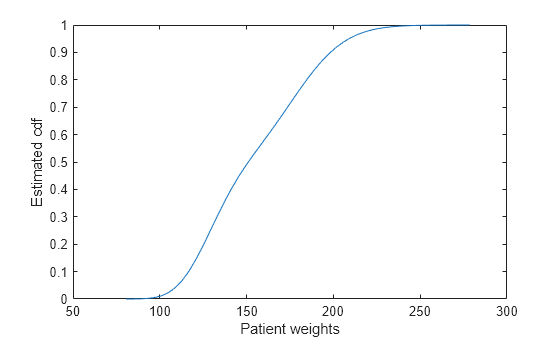
load hospital绘制在 50 个等间距点处计算的估计 cdf。
figure() ksdensity(hospital.Weight,'Support','positive','Function','cdf',... 'NumPoints',50) xlabel('Patient weights') ylabel('Estimated cdf')
从均值为 3 的指数分布生成样本数据。
rng('default') % For reproducibility x = random('exp',3,100,1);
创建一个指示删失的逻辑向量。此处,寿命长于 10 的观测值视为删失。
T = 10; cens = (x>T);
计算并绘制估计密度函数。
figure ksdensity(x,'Support','positive','Censoring',cens);

计算并绘制生存函数。
figure ksdensity(x,'Support','positive','Censoring',cens,... 'Function','survivor');

计算并绘制累积风险函数。
figure ksdensity(x,'Support','positive','Censoring',cens,... 'Function','cumhazard');

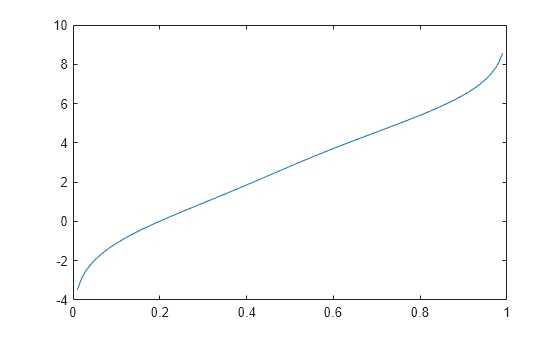
生成两个正态分布的混合,并在指定的概率值集处绘制估计的逆累积分布函数。
rng('default') % For reproducibility x = [randn(30,1); 5+randn(30,1)]; pi = linspace(.01,.99,99); figure ksdensity(x,pi,'Function','icdf');
生成两个正态分布的混合。
rng('default') % For reproducibility x = [randn(30,1); 5+randn(30,1)];
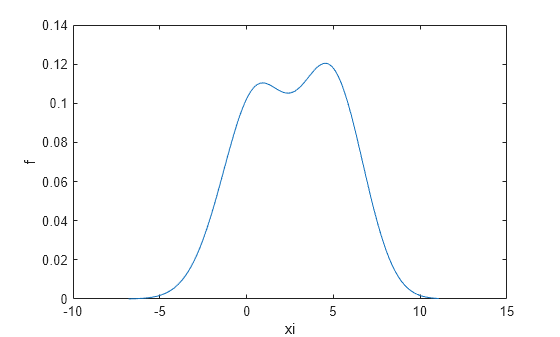
返回概率密度估计的平滑窗的带宽。
[f,xi,bw] = ksdensity(x); bw
bw = 1.5141
对于正态密度而言,默认带宽是最优的。
绘制估计密度。
figure plot(xi,f); xlabel('xi') ylabel('f') hold on
使用增加的带宽值绘制密度。
[f,xi] = ksdensity(x,'Bandwidth',1.8); plot(xi,f,'--r','LineWidth',1.5)
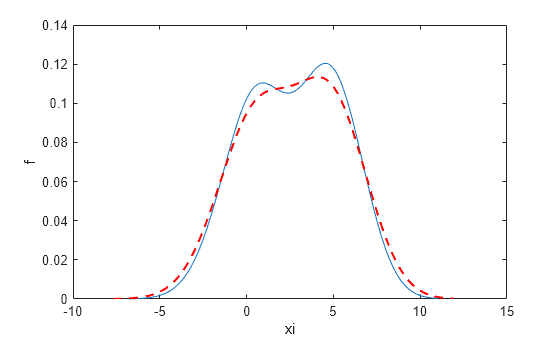
较高的带宽可进一步平滑密度估计,这可能会掩盖分布的某些特征。
现在,使用减小的带宽值绘制密度。
[f,xi] = ksdensity(x,'Bandwidth',0.8); plot(xi,f,'-.k','LineWidth',1.5) legend('bw = default','bw = 1.8','bw = 0.8') hold off
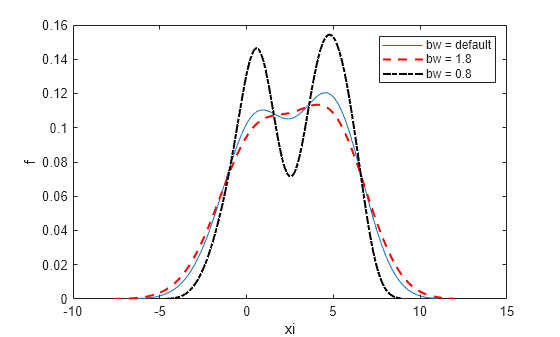
带宽越小,对密度估计的平滑程度就越低,这会夸大样本的某些特征。
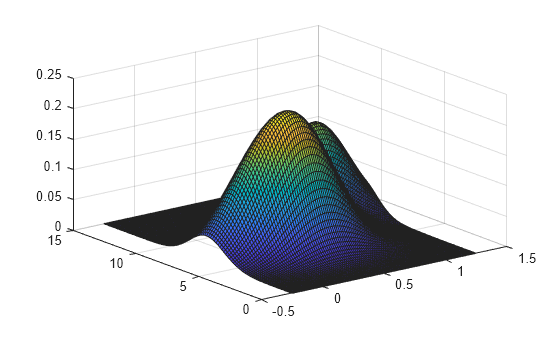
创建一个由点组成的两列向量,在这些点处计算密度。
gridx1 = -0.25:.05:1.25; gridx2 = 0:.1:15; [x1,x2] = meshgrid(gridx1, gridx2); x1 = x1(:); x2 = x2(:); xi = [x1 x2];
生成一个 30×2 的矩阵,其中包含来自二元正态分布混合的随机数。
rng('default') % For reproducibility x = [0+.5*rand(20,1) 5+2.5*rand(20,1); .75+.25*rand(10,1) 8.75+1.25*rand(10,1)];
绘制样本数据的估计密度。
figure ksdensity(x,xi);
输入参数
名称-值参数
输出参量
详细信息
替代功能
您也可以使用 MATLAB® kde 函数来估计一元数据的 pdf 或 cdf。与 ksdensity 不同,kde 不支持边界校正方法或数据删失。
参考
[1] Botev, Z. I., J. F. Grotowski, and D. P. Kroese. "Kernel Density Estimation via Diffusion." The Annals of Statistics, vol. 38, no. 5 (October 1, 2010). https://projecteuclid.org/journals/annals-of-statistics/volume-38/issue-5/Kernel-density-estimation-via-diffusion/10.1214/10-AOS799.full
[2] Bowman, A. W., and A. Azzalini. Applied Smoothing Techniques for Data Analysis. New York: Oxford University Press Inc., 1997.
[3] Hill, P. D. “Kernel estimation of a distribution function.” Communications in Statistics - Theory and Methods. Vol 14, Issue. 3, 1985, pp. 605-620.
[4] Jones, M. C. “Simple boundary correction for kernel density estimation.” Statistics and Computing. Vol. 3, Issue 3, 1993, pp. 135-146.
[5] Silverman, B. W. Density Estimation for Statistics and Data Analysis. Chapman & Hall/CRC, 1986.
扩展功能
版本历史记录
在 R2006a 之前推出