lettersPattern
匹配字母字符
说明
pat = lettersPatternlettersPattern 接受由 Unicode 标准定义的字母字符。
pat = lettersPattern(minCharacters,maxCharacters)minCharacters 个且小于或等于 maxCharacters 个字母组成的文本。inf 是 maxLetter 的有效值。lettersPattern 是贪婪模式,匹配的字母数量尽可能接近 maxCharacters 个。
示例
使用 lettersPattern 从包含字母、数字、空白和标点符号的字符串中提取单词。
创建字符串 txt 变量。使用 lettersPattern 将 pat 创建为匹配字母的 pattern 对象。从 txt 中提取该模式。
txt = "The 2 parties agreed. The meeting would occur at 1 PM.";
pat = lettersPattern;
words = extract(txt,pat)words = 9×1 string
"The"
"parties"
"agreed"
"The"
"meeting"
"would"
"occur"
"at"
"PM"
使用 lettersPattern 对一行文本中出现的单个字母进行计数。
创建字符串 txt 变量。使用 lettersPattern 将 pat 创建为与单个字母匹配的 pattern 对象。提取该模式。显示每个字母出现次数的直方图。
txt = "What are the letters in this sentence?";
pat = lettersPattern(1);
letters = extract(txt,pat);
letters = categorical(letters);
histogram(letters)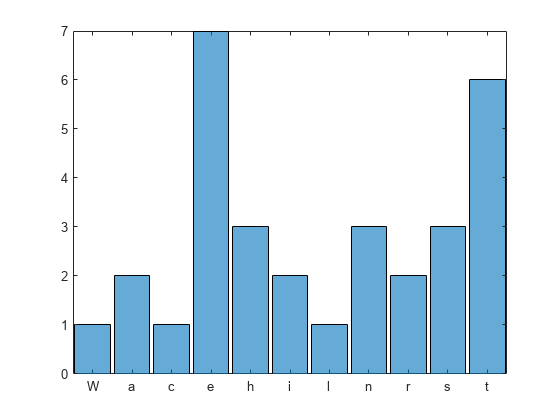
使用 lettersPattern 排除超过五个字母的单词。
使用 lettersPattern 将 pat 创建为 pattern,该模式匹配包含五个或更多字母的组。提取该模式。
txt = "Some of these words are longer than others.";
pat = lettersPattern(5,inf);
extract(txt,pat)ans = 4×1 string
"these"
"words"
"longer"
"others"
输入参数
输出参量
扩展功能
版本历史记录
在 R2020b 中推出