setvaropts
设置变量导入选项
说明
opts = setvaropts(opts,Name,Value)Name,Value 参量中的设定更新 opts 对象中的所有变量,并返回 opts 对象。
opts = setvaropts(opts,selection,Name,Value)Name,Value 参量中的指定,更新并返回 selection 参量中指定的变量的 opts。
示例
创建一个导入选项对象、为选定的变量设置选项,并使用自定义的选项和 readtable 函数导入数据。
为电子表格 patients.xls 创建一个选项对象。
opts = detectImportOptions('patients.xls');为 Smoker、Diastolic 和 Systolic 变量设置 FillValue 属性。
opts = setvaropts(opts,'Smoker','FillValue',false); opts = setvaropts(opts,{'Diastolic','Systolic'},'FillValue',0);
选择要导入的变量。
opts.SelectedVariableNames = {'Smoker','Diastolic','Systolic'};导入变量并显示摘要。
T = readtable('patients.xls',opts);
summary(T) T: 100×3 table
Variables:
Smoker: logical (34 true)
Diastolic: double
Systolic: double
Statistics for applicable variables:
NumMissing Min Median Max Mean Std
Diastolic 0 68 81.5000 99 82.9600 6.9325
Systolic 0 109 122 138 122.7800 6.7128
导入包含缺失或不完整字段的数据需要识别缺失的实例,并决定如何导入缺失的实例。可使用 importOptions 捕获这些决定,并使用 readtable 获取数据。
为文件创建一个导入选项对象、更新那些控制缺失数据导入的属性,然后使用 readtable 导入数据。请注意,数据集 airlinesmall_subset.csv 有两个数值变量(ArrDelay 和 DepDelay)包含缺失数据,由 NA 指示。

从文件中创建一个导入选项对象。
opts = detectImportOptions("airlinesmall_subset.csv");使用 TreatAsMissing 属性指定数据中作为缺失数据占位符的字符。在此示例中,两个数值变量 ArrDelay 和 DepDelay 包含缺失字段,其中包含文本 NA。
opts = setvaropts(opts,["ArrDelay","DepDelay"],"TreatAsMissing","NA");
指定导入函数导入缺失实例时要执行的操作。要了解更多选项,请参阅 ImportOptions 属性页。
opts.MissingRule = "fill";指定导入函数发现缺失实例时要使用的值。这里,变量 ArrDelay 和 DepDelay 中的缺失实例被替换为 0。
opts = setvaropts(opts,["ArrDelay","DepDelay"],"FillValue",0);
选择您要使用的变量,并使用 readtable 导入它们。
opts.SelectedVariableNames = ["ArrDelay","DepDelay"]; T = readtable("airlinesmall_subset.csv",opts);
检查 ArrDelay 和 DepDelay 中的值。验证导入函数已替换由 NA 指示的缺失值。
T(42:55,:)
ans=14×2 table
ArrDelay DepDelay
________ ________
3 -4
0 -1
11 11
0 0
0 0
0 0
-9 5
-9 -3
2 6
0 0
1 1
0 4
9 0
-2 4
readtable 函数自动检测具有 0x 和 0b 前缀的十六进制和二进制数字。要导入这些数字不带前缀的形式,请使用导入选项对象。
为文件 hexAndBinary.txt 创建一个导入选项对象。其第三列包含十六进制数字,不带 0x 前缀。
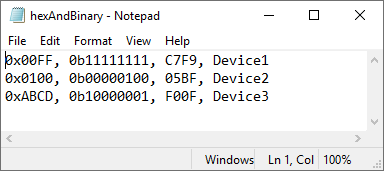
opts = detectImportOptions('hexAndBinary.txt')opts =
DelimitedTextImportOptions with properties:
Format Properties:
Delimiter: {','}
Whitespace: '\b\t '
LineEnding: {'\n' '\r' '\r\n'}
CommentStyle: {}
ConsecutiveDelimitersRule: 'split'
LeadingDelimitersRule: 'keep'
TrailingDelimitersRule: 'ignore'
EmptyLineRule: 'skip'
Encoding: 'UTF-8'
Replacement Properties:
MissingRule: 'fill'
ImportErrorRule: 'fill'
ExtraColumnsRule: 'addvars'
Variable Import Properties: Set types by name using setvartype
VariableNames: {'Var1', 'Var2', 'Var3' ... and 1 more}
VariableTypes: {'auto', 'auto', 'char' ... and 1 more}
SelectedVariableNames: {'Var1', 'Var2', 'Var3' ... and 1 more}
VariableOptions: Show all 4 VariableOptions
Access VariableOptions sub-properties using setvaropts/getvaropts
VariableNamingRule: 'modify'
Location Properties:
DataLines: [1 Inf]
VariableNamesLine: 0
RowNamesColumn: 0
VariableUnitsLine: 0
VariableDescriptionsLine: 0
To display a preview of the table, use preview
要指定第三列应作为十六进制值导入,即使缺失前缀也要导入,请使用 setvaropts 函数。将第三个变量的变量类型设置为 int32。将用于导入第三列的进制设置为 hex。
opts = setvaropts(opts,3,'NumberSystem','hex','Type','int32')
opts =
DelimitedTextImportOptions with properties:
Format Properties:
Delimiter: {','}
Whitespace: '\b\t '
LineEnding: {'\n' '\r' '\r\n'}
CommentStyle: {}
ConsecutiveDelimitersRule: 'split'
LeadingDelimitersRule: 'keep'
TrailingDelimitersRule: 'ignore'
EmptyLineRule: 'skip'
Encoding: 'UTF-8'
Replacement Properties:
MissingRule: 'fill'
ImportErrorRule: 'fill'
ExtraColumnsRule: 'addvars'
Variable Import Properties: Set types by name using setvartype
VariableNames: {'Var1', 'Var2', 'Var3' ... and 1 more}
VariableTypes: {'auto', 'auto', 'int32' ... and 1 more}
SelectedVariableNames: {'Var1', 'Var2', 'Var3' ... and 1 more}
VariableOptions: Show all 4 VariableOptions
Access VariableOptions sub-properties using setvaropts/getvaropts
VariableNamingRule: 'modify'
Location Properties:
DataLines: [1 Inf]
VariableNamesLine: 0
RowNamesColumn: 0
VariableUnitsLine: 0
VariableDescriptionsLine: 0
To display a preview of the table, use preview
读取文件并将前三列作为数值导入。readtable 函数自动检测包含第一列和第二列包含十六进制和二进制值。导入选项对象指定第三列也包含十六进制值。
T = readtable('hexAndBinary.txt',opts)T=3×4 table
Var1 Var2 Var3 Var4
_____ ____ _____ ___________
255 255 51193 {'Device1'}
256 4 1471 {'Device2'}
43981 129 61455 {'Device3'}
可使用 setvaropts 函数来更新那些控制文本数据导入的属性。首先,获取文件的导入选项对象。然后,检查并更新文本变量的选项。最后,使用 readtable 函数导入变量。
预览 patients.xls 中的数据。请注意 LastName 列中的文本数据。这里只显示前 10 行的预览。
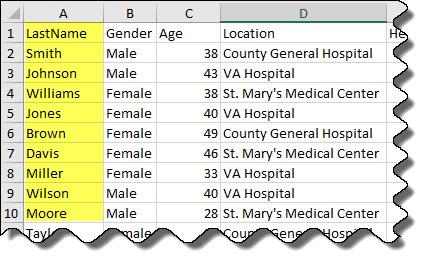
获取导入选项对象。
opts = detectImportOptions('patients.xls');获取并检查变量 LastName 的 VariableImportOptions。
getvaropts(opts,'LastName')ans =
TextVariableImportOptions with properties:
Variable Properties:
Name: 'LastName'
Type: 'char'
FillValue: ''
TreatAsMissing: {}
QuoteRule: 'remove'
Prefixes: {}
Suffixes: {}
EmptyFieldRule: 'missing'
String Options:
WhitespaceRule: 'trim'
将该变量的数据类型设置为 string。
opts = setvartype(opts,'LastName','string');
设置该变量的 FillValue 属性,将缺失值替换为 'NoName'。
opts = setvaropts(opts,'LastName','FillValue','NoName');
选择、读取并显示该变量的前 10 行的预览。
opts.SelectedVariableNames = 'LastName'; T = readtable('patients.xls',opts); T.LastName(1:10)
ans = 10×1 string
"Smith"
"Johnson"
"Williams"
"Jones"
"Brown"
"Davis"
"Miller"
"Wilson"
"Moore"
"Taylor"
可使用 setvaropts 函数来更新那些控制 logical 数据导入的属性。首先,获取文件的导入选项对象。然后,检查并更新逻辑变量的选项。最后,使用 readtable 函数导入变量。
预览 airlinesmall_subset.xlsx 中的数据。请注意 Cancelled 列中的逻辑数据。这里只显示从第 30 行到第 40 行的预览。
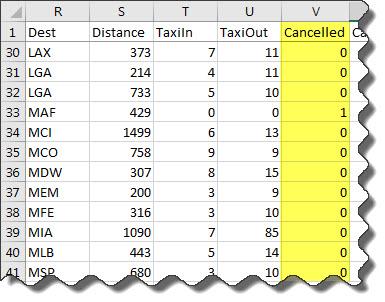
获取导入选项对象。
opts = detectImportOptions('airlinesmall_subset.xlsx');获取并检查变量 Cancelled 的 VariableImportOptions。
getvaropts(opts,'Cancelled')ans =
NumericVariableImportOptions with properties:
Variable Properties:
Name: 'Cancelled'
Type: 'double'
FillValue: NaN
TreatAsMissing: {}
QuoteRule: 'remove'
Prefixes: {}
Suffixes: {}
EmptyFieldRule: 'missing'
Numeric Options:
ExponentCharacter: 'eEdD'
DecimalSeparator: '.'
ThousandsSeparator: ''
TrimNonNumeric: 0
NumberSystem: 'decimal'
将该变量的数据类型设置为 logical。
opts = setvartype(opts,'Cancelled','logical');
设置该变量的 FillValue 属性,将缺失值替换为 true。
opts = setvaropts(opts,'Cancelled','FillValue',true);
选择、读取并显示变量摘要。
opts.SelectedVariableNames = 'Cancelled'; T = readtable('airlinesmall_subset.xlsx',opts); summary(T)
T: 1338×1 table
Variables:
Cancelled: logical (29 true)
可使用 DatetimeVariableImportOptions 属性来控制 datetime 数据的导入。首先,获取文件的 ImportOptions 对象。然后,检查并更新日期时间变量的 VariableImportOptions。最后,使用 readtable 导入变量。
预览 outages.csv 中的数据。请注意 OutageTime 和 RestorationTime 列中的日期和时间数据。这里只显示前 10 行。
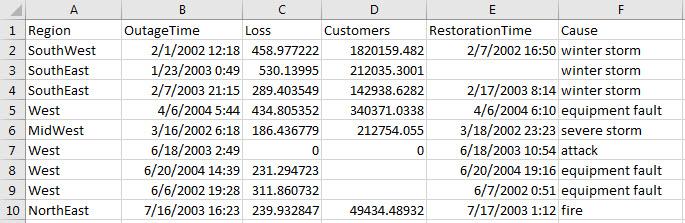
获取导入选项对象。
opts = detectImportOptions('outages.csv');获取并检查日期时间变量 OutageTime 和 RestorationTime 的 VariableImportOptions。
varOpts = getvaropts(opts,{'OutageTime','RestorationTime'})varOpts =
1×2 DatetimeVariableImportOptions array with properties:
Name
Type
FillValue
TreatAsMissing
QuoteRule
Prefixes
Suffixes
EmptyFieldRule
DatetimeFormat
DatetimeLocale
TimeZone
InputFormat
设置变量的 FillValue 属性,将缺失值替换为当前日期和时间。
opts = setvaropts(opts,{'OutageTime','RestorationTime'},...
'FillValue','now');选择、读取并预览这两个变量。请注意,RestorationTime 第二行的缺失值已填入当前日期和时间。
opts.SelectedVariableNames = {'OutageTime','RestorationTime'};
T = readtable('outages.csv',opts);
T(1:10,:)ans=10×2 table
OutageTime RestorationTime
________________ ________________
2002-02-01 12:18 2002-02-07 16:50
2003-01-23 00:49 2026-01-24 21:54
2003-02-07 21:15 2003-02-17 08:14
2004-04-06 05:44 2004-04-06 06:10
2002-03-16 06:18 2002-03-18 23:23
2003-06-18 02:49 2003-06-18 10:54
2004-06-20 14:39 2004-06-20 19:16
2002-06-06 19:28 2002-06-07 00:51
2003-07-16 16:23 2003-07-17 01:12
2004-09-27 11:09 2004-09-27 16:37
可使用 setvaropts 函数来更新那些控制 categorical 数据导入的属性。首先,获取文件的导入选项对象。然后,检查并更新分类变量的选项。最后,使用 readtable 函数导入变量。
预览 outages.csv 中的数据。请注意 Region 和 Cause 列中的分类数据。此表只显示前 10 行。
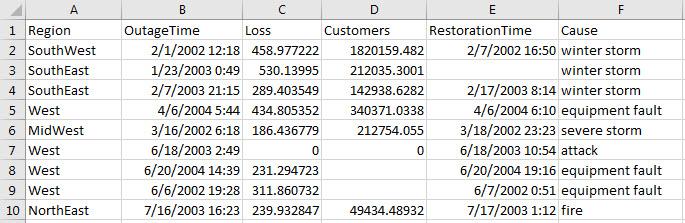
获取导入选项对象。
opts = detectImportOptions('outages.csv');获取并检查变量 Region 和 Cause 的选项。
getvaropts(opts,{'Region','Cause'})ans =
1×2 TextVariableImportOptions array with properties:
Name
Type
FillValue
TreatAsMissing
QuoteRule
Prefixes
Suffixes
EmptyFieldRule
WhitespaceRule
将变量的数据类型设置为 categorical。
opts = setvartype(opts,{'Region','Cause'},'categorical');设置变量的 FillValue 属性,将缺失值替换为类别名称 'Miscellaneous'。将 TreatAsMissing 属性设置为 'unknown'。
opts = setvaropts(opts,{'Region','Cause'},...
'FillValue','Miscellaneous',...
'TreatAsMissing','unknown');选择、读取并显示这两个变量的摘要。
opts.SelectedVariableNames = {'Region','Cause'};
T = readtable('outages.csv',opts);
summary(T)T: 1468×2 table
Variables:
Region: categorical (5 categories)
Cause: categorical (10 categories)
Statistics for applicable variables:
NumMissing
Region 0
Cause 0
导入表格数据,其中包含的变量带有不需要的前缀和后缀字符。首先,创建导入选项对象并预览数据。然后,选择感兴趣的变量并设置其变量类型和属性,以删除不需要的字符。最后,导入感兴趣的数据。
为文件创建导入选项并预览表格。
filename = 'pref_suff_trim.csv';
opts = detectImportOptions(filename);
preview(filename,opts)Warning: Column headers from the file were modified to make them valid MATLAB identifiers before creating variable names for the table. The original column headers are saved in the VariableDescriptions property. Set 'VariableNamingRule' to 'preserve' to use the original column headers as table variable names.
ans=8×5 table
'Timestamp:1/1/06 0:00' '& Sun %20' '54.5448 MW' '$1.23' '-7.2222 C'
'Timestamp:1/2/06 1:00' '& Thu %20' '.3898 MW' '$300.00' '-7.3056 C'
'Timestamp:1/3/06 2:00' '& Sun %20' '51.6344 MW' '£2.50' '-7.8528 C'
'Timestamp:1/4/06 3:00' '& Sun %20' '51.5597 MW' '$0.00' '-8.1778 C'
'Timestamp:1/5/06 4:00' '& Wed %20' '51.7148 MW' '¥4.00' '-8.9343 C'
'Timestamp:1/6/06 5:00' '& Sun %20' '52.6898 MW' '$0.00' '-8.7556 C'
'Timestamp:1/7/06 6:00' '& Mon %20' '55.341 MW' '$50.70' '-8.0417 C'
'Timestamp:1/8/06 7:00' '& Sat %20' '57.9512 MW' '$0.00' '-8.2028 C'
选择感兴趣的变量,指定其类型,并检查其变量导入选项值。
opts.SelectedVariableNames = {'Time','Total_Fees','Temperature'};
opts = setvartype(opts,'Time','datetime');
opts = setvaropts(opts,'Time','InputFormat','MM/dd/uu HH:mm'); % Specify datetime format
opts = setvartype(opts,{'Total_Fees','Temperature'},'double');
getvaropts(opts,{'Time','Total_Fees','Temperature'})ans =
1×3 VariableImportOptions array with properties:
Variable Options:
(1) | (2) | (3)
Name: 'Time' | 'Total_Fees' | 'Temperature'
Type: 'datetime' | 'double' | 'double'
FillValue: NaT | NaN | NaN
TreatAsMissing: {} | {} | {}
EmptyFieldRule: 'missing' | 'missing' | 'missing'
QuoteRule: 'remove' | 'remove' | 'remove'
Prefixes: {} | {} | {}
Suffixes: {} | {} | {}
To access sub-properties of each variable, use getvaropts
将变量导入选项设置为 Prefixes、Suffixes 和 TrimNonNumeric 属性,以便从变量 Time 中删除 'Timestamp:',从变量 Temperature 中删除后缀 'C',并从变量 Total_Fees 中删除所有非数值字符。使用新的导入选项预览表格。
opts = setvaropts(opts,'Time','Prefixes','Timestamp:'); opts = setvaropts(opts,'Temperature','Suffixes','C'); opts = setvaropts(opts,'Total_Fees','TrimNonNumeric',true); preview(filename,opts)
ans=8×3 table
01/01/06 00:00 1.2300 -7.2222
01/02/06 01:00 300 -7.3056
01/03/06 02:00 2.5000 -7.8528
01/04/06 03:00 0 -8.1778
01/05/06 04:00 4 -8.9343
01/06/06 05:00 0 -8.7556
01/07/06 06:00 50.7000 -8.0417
01/08/06 07:00 0 -8.2028
使用 readtable 导入数据。
T = readtable(filename,opts);
为包含空字段的文件创建导入选项对象。使用 EmptyFieldRule 参数来管理数据中空字段的导入。首先,预览数据,然后为特定变量设置 EmptyFieldRule 参数。最后,为所有变量设置 EmptyFieldRule 并导入数据。
为包含空字段的文件创建导入选项对象。使用 preview 函数获取表的前八行。EmptyFieldRule 的默认值是 'missing'。因此,导入函数将空字段视为缺失,并将这些字段替换为该变量的 FillValue 值。使用 VariableOptions 作为第三个变量,预览数据。此处,preview 函数将第三个变量中的空字段导入为 NaN。
filename = 'DataWithEmptyFields.csv'; opts = detectImportOptions(filename); opts.VariableOptions(3) % Display the Variable Options for the 3rd Variable
ans =
NumericVariableImportOptions with properties:
Variable Properties:
Name: 'Double'
Type: 'double'
FillValue: NaN
TreatAsMissing: {}
QuoteRule: 'remove'
Prefixes: {}
Suffixes: {}
EmptyFieldRule: 'missing'
Numeric Options:
ExponentCharacter: 'eEdD'
DecimalSeparator: '.'
ThousandsSeparator: ''
TrimNonNumeric: 0
NumberSystem: 'decimal'
preview(filename,opts)
ans=8×7 table
Text Categorical Double Datetime Logical Duration String
__________ ___________ ______ __________ __________ ________ __________
{'abc' } {'a' } 1 01/14/0018 {'TRUE' } 00:00:01 {'abc' }
{0×0 char} {'b' } 2 01/21/0018 {'FALSE' } 09:00:01 {'def' }
{'ghi' } {0×0 char} 3 01/31/0018 {'TRUE' } 02:00:01 {'ghi' }
{'jkl' } {'a' } NaN 02/23/2018 {'FALSE' } 03:00:01 {'jkl' }
{'mno' } {'a' } 4 NaT {'FALSE' } 04:00:01 {'mno' }
{'pqr' } {'b' } 5 01/23/0018 {0×0 char} 05:00:01 {'pqr' }
{'stu' } {'b' } 5 03/23/0018 {'FALSE' } NaN {'stu' }
{0×0 char} {'a' } 6 03/24/2018 {'TRUE' } 07:00:01 {0×0 char}
为表中的第二个变量设置 EmptyFieldRule。首先,选择该变量,然后将 EmptyFieldRule 设置为 'auto'。此处,readtable 函数将 categorical 变量的空字段导入为 <undefined>。
opts.SelectedVariableNames = 'Categorical'; opts = setvartype(opts,'Categorical','categorical'); opts = setvaropts(opts,'Categorical','EmptyFieldRule','auto'); T = readtable(filename,opts)
T=10×1 table
Categorical
___________
a
b
<undefined>
a
a
b
b
a
a
<undefined>
接下来,为表中的所有变量设置 EmptyFieldRule 参数。首先,适当地更新变量的数据类型。对于此示例,将第五个和第七个变量的数据类型分别设置为 logical 和 string。然后,将所有变量的 EmptyFieldRule 设置为 'auto'。导入函数根据变量的数据类型导入空字段。此处,readtable 函数将 logical 变量的空字段导入为 0,将 categorical 变量的空字段导入为 <undefined>。
VariableNames = opts.VariableNames; opts.SelectedVariableNames = VariableNames; % select all variables opts = setvartype(opts,{'Logical','String'},{'logical','string'}); opts = setvaropts(opts,VariableNames,'EmptyFieldRule','auto'); T = readtable(filename,opts)
T=10×7 table
Text Categorical Double Datetime Logical Duration String
__________ ___________ ______ __________ _______ ________ _________
{'abc' } a 1 01/14/0018 true 00:00:01 "abc"
{0×0 char} b 2 01/21/0018 false 09:00:01 "def"
{'ghi' } <undefined> 3 01/31/0018 true 02:00:01 "ghi"
{'jkl' } a NaN 02/23/2018 false 03:00:01 "jkl"
{'mno' } a 4 NaT false 04:00:01 "mno"
{'pqr' } b 5 01/23/0018 false 05:00:01 "pqr"
{'stu' } b 5 03/23/0018 false NaN "stu"
{0×0 char} a 6 03/24/2018 true 07:00:01 ""
{0×0 char} a 7 03/25/2018 true 08:00:01 <missing>
{'xyz' } <undefined> NaN NaT true 06:00:01 "xyz"
除 'missing' 和 'auto' 外,还可以将 EmptyFieldRule 参数设置为 'error'。将其设置为 'error' 时,readtable 函数将按照 ImportErrorRule 参数中指定的过程导入空字段。
输入参数
名称-值参数
版本历史记录
在 R2016b 中推出