categorical
数组,包含分配给类别的值
说明
categorical 是为一组有限的离散类别(例如 High、Med 和 Low)赋值的数据类型。这些类别可以采用您指定的数学排序,例如 High > Med > Low,但这并非必须。分类数组可用来有效地存储并方便地处理非数值数据,同时还为数值赋予有意义的名称。分类数组的常见用法是用来定义构成表的各组行。
创建对象
要创建一个 categorical 数组,请执行以下操作:
使用如下所述的
categorical函数。使用
discretize函数对连续数据分 bin。以分类数组形式返回这些 bin。将两个分类数组相乘。乘积是一个分类数组,其类别是两个操作数的类别的所有可能组合。
语法
描述
输入参量
名称-值参数
输出参量
示例
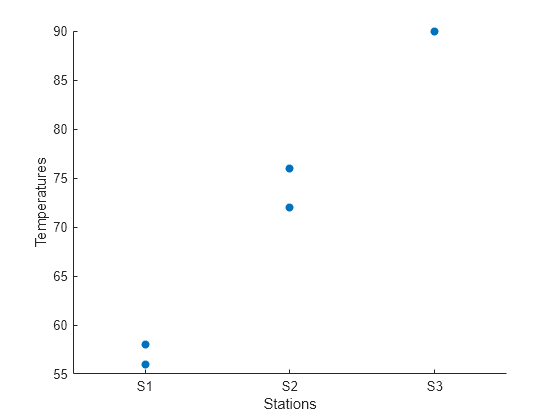
从气象站代码列表创建一个分类数组。然后将其添加到温度读数表中。使用该分类数组帮助您按类别分析表中的数据。
首先,创建一个气象站代码数组。
Stations = ["S1" "S2" "S1" "S3" "S2"]
Stations = 1×5 string
"S1" "S2" "S1" "S3" "S2"
要根据气象站代码创建一个分类数组,请使用 categorical 函数。
Stations = categorical(Stations)
Stations = 1×5 categorical
S1 S2 S1 S3 S2
显示类别。三个站代码是类别。
categories(Stations)
ans = 3×1 cell
{'S1'}
{'S2'}
{'S3'}
现在创建一个包含天气数据的表。该表包含温度、日期和站代码。
Temperatures = [58;72;56;90;76]; Dates = datetime(["2017-04-17";"2017-04-18";"2017-04-30";"2017-05-01";"2017-04-27"]); Stations = Stations'; tempReadings = table(Temperatures,Dates,Stations)
tempReadings=5×3 table
Temperatures Dates Stations
____________ ___________ ________
58 17-Apr-2017 S1
72 18-Apr-2017 S2
56 30-Apr-2017 S1
90 01-May-2017 S3
76 27-Apr-2017 S2
按气象站对表中的数据进行分类。例如,返回包含站 S2 的数据的表行。使用逻辑索引数组对表进行索引,其中 Stations 等于 S2。
TF = (tempReadings.Stations == "S2")TF = 5×1 logical array
0
1
0
0
1
tempReadings(TF,:)
ans=2×3 table
Temperatures Dates Stations
____________ ___________ ________
72 18-Apr-2017 S2
76 27-Apr-2017 S2
为了找到与气象站相关联的数据模式,需要创建一个按气象站划分的温度读数的散点图。
scatter(tempReadings,"Stations","Temperatures","filled")
将字符串数组转换为分类数组。指定该分类数组具有一组类别,其中包含原始数组中不存在的值。
首先,创建一个包含一组重复值的字符串数组。
A = ["red" "blue" "blue" "blue" "blue" "red"]
A = 1×6 string
"red" "blue" "blue" "blue" "blue" "red"
将此字符串数组转换为分类数组。指定其类别。包括 green 作为一个类别。
valueset = ["blue" "red" "green"]; C = categorical(A,valueset)
C = 1×6 categorical
red blue blue blue blue red
显示分类数组的类别。它包含一个并非来自输入字符串数组的类别。
categories(C)
ans = 3×1 cell
{'blue' }
{'red' }
{'green'}
创建一个数值数组。
A = [1 3 2; 2 1 3; 3 1 2]
A = 3×3
1 3 2
2 1 3
3 1 2
将该数值数组转换为分类数组。指定类别的值和名称。
C = categorical(A,[1 2 3],["red" "green" "blue"])
C = 3×3 categorical
red blue green
green red blue
blue red green
显示类别。
categories(C)
ans = 3×1 cell
{'red' }
{'green'}
{'blue' }
C 不是有序的分类数组。因此,您只能使用相等运算符 == 和 ~= 毕竟 C 中的值。
找出属于类别 red 的元素。使用逻辑索引访问这些元素。
TF = (C == "red")TF = 3×3 logical array
1 0 0
0 1 0
0 1 0
C(TF)
ans = 3×1 categorical
red
red
red
默认情况下,categorical 函数将缺失值(如 NaN、NaT、空字符串和缺失字符串)转换为未定义的分类值。不过,当您调用 categorical 时,您可以指定缺失值所属的类别。
例如,创建一个包含空字符串和缺失字符串的字符串数组。
A = ["hi" "lo" missing "" "lo" "lo" "hi"]
A = 1×7 string
"hi" "lo" <missing> "" "lo" "lo" "hi"
首先,将该字符串数组转换为包含未定义元素的分类数组。
C = categorical(A)
C = 1×7 categorical
hi lo <undefined> <undefined> lo lo hi
categories(C)
ans = 2×1 cell
{'hi'}
{'lo'}
然后再次转换它。但是,这次指定 INDEF 作为缺失字符串的类别。
C = categorical(A,["lo" "hi" missing],["lo" "hi" "INDEF"])
C = 1×7 categorical
hi lo INDEF <undefined> lo lo hi
categories(C)
ans = 3×1 cell
{'lo' }
{'hi' }
{'INDEF'}
指定 INDEF 作为缺失字符串和空字符串的类别。
C = categorical(A,["lo" "hi" missing ""],["lo" "hi" "INDEF" "INDEF"])
C = 1×7 categorical
hi lo INDEF INDEF lo lo hi
categories(C)
ans = 3×1 cell
{'lo' }
{'hi' }
{'INDEF'}
创建一个 5×2 的数值数组。
A = [3 2;3 3;3 2;2 1;3 2]
A = 5×2
3 2
3 3
3 2
2 1
3 2
将 A 转换为有序分类数组,其中 1、2 和 3 分别表示类别 child、adult 和 senior。
valueset = [1 2 3]; catnames = ["child" "adult" "senior"]; C = categorical(A,valueset,catnames,Ordinal=true)
C = 5×2 categorical
senior adult
senior senior
senior adult
adult child
senior adult
由于 C 是有序数组,C 的类别具有数学排序方式 child < adult < senior。您可以对有序分类值使用所有关系运算符。例如,返回值大于 adult 的元素。
TF = C > "adult"TF = 5×2 logical array
1 0
1 1
1 0
0 0
1 0
C(TF)
ans = 5×1 categorical
senior
senior
senior
senior
senior
您可以通过创建一个 NaN 数组并将其转换为分类数组来预分配任意大小的分类数组。预分配数组后,可以通过指定类别名称并将类别添加到数组来初始化其类别。
首先创建一个 NaN 数组。您可以创建任意大小的数组。例如,创建一个由 NaN 值组成的 2×4 数组。
A = NaN(2,4)
A = 2×4
NaN NaN NaN NaN
NaN NaN NaN NaN
然后通过转换 NaN 数组来预分配分类数组。categorical 函数将 NaN 转换为未定义的分类值。正如 NaN 表示“非数值”,<undefined> 表示不属于某个类别的分类值。
C = categorical(A)
C = 2×4 categorical
<undefined> <undefined> <undefined> <undefined>
<undefined> <undefined> <undefined> <undefined>
事实上,此时 C 没有类别。
categories(C)
ans = 0×0 empty cell array
要初始化 C 的类别,请指定类别名称,并使用 addcats 函数将它们添加到 C 中。例如,添加 small、medium 和 large 作为 C 的三个类别。
C = addcats(C,["small" "medium" "large"])
C = 2×4 categorical
<undefined> <undefined> <undefined> <undefined>
<undefined> <undefined> <undefined> <undefined>
虽然 C 的元素是未定义的值,但类别已由 addcats 初始化。
categories(C)
ans = 3×1 cell
{'small' }
{'medium'}
{'large' }
现在 C 已经有了类别,您可以将定义的分类值指定为 C 的元素。
C(1) = "medium"; C(8) = "small"; C(3:5) = "large"
C = 2×4 categorical
medium large large <undefined>
<undefined> large <undefined> small
推荐使用 discretize 函数为连续数据创建若干类别,尤其是当输入值间距很小时。当两个值之间的差约小于 5e-5 时,其间距很小。当值的间距很小时,categorical 函数无法根据值创建唯一类别名称。
创建一个包含 100 个随机数的数值数组。
X = rand(100,1)
X = 100×1
0.8147
0.9058
0.1270
0.9134
0.6324
0.0975
0.2785
0.5469
0.9575
0.9649
0.1576
0.9706
0.9572
0.4854
0.8003
⋮
要通过分 bin 将这些数字分成三个类别,请使用 discretize。为 bin 指定 bin 边界和类别名称。
C = discretize(X,[0 .25 .75 1],"categorical",["small" "medium" "large"])
C = 100×1 categorical
large
large
small
large
medium
small
medium
medium
large
large
small
large
large
medium
large
small
medium
large
large
large
medium
small
large
large
medium
large
medium
medium
medium
small
⋮
绘制这三个类别的数据的直方图。
histogram(C)
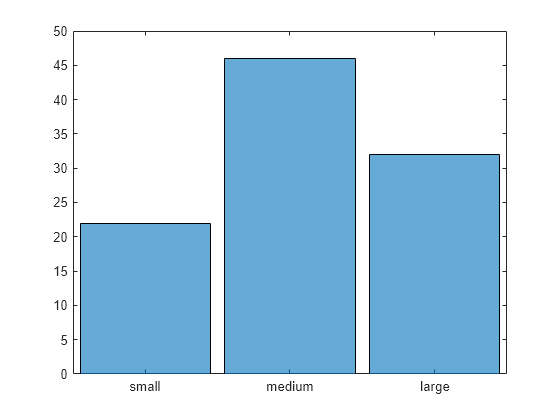
当您将两个分类数组相乘时,将得到一个包含一组新类别的分类数组。新类别是根据两个原始分类数组的类别创建的所有有序对组。这组所有可能的类别组合也称为两个原始类别组的笛卡尔积。
例如,创建两个分类数组。这些数组列出六位患者的血型和 Rh 因子。
bloodGroups = categorical(["A" "AB" "O" "O" "A" "A"], ... ["A" "B" "AB" "O"])
bloodGroups = 1×6 categorical
A AB O O A A
Rhfactors = categorical(["+" "+" "-" "-" "+" "+"])
Rhfactors = 1×6 categorical
+ + - - + +
显示这两个数组的类别。虽然这两个分类数组具有相同数量的元素,但它们可以具有不同数量的类别。
categories(bloodGroups)
ans = 4×1 cell
{'A' }
{'B' }
{'AB'}
{'O' }
categories(Rhfactors)
ans = 2×1 cell
{'+'}
{'-'}
将这两个分类数组相乘。乘积的元素来自输入数组中对应元素的组合。
bloodTypes = bloodGroups .* Rhfactors
bloodTypes = 1×6 categorical
A + AB + O - O - A + A +
但是,乘积的类别是可以根据两个数组的类别创建的所有有序对组。因此,有些类别可能无法由输出数组的任何元素来表示。
categories(bloodTypes)
ans = 8×1 cell
{'A +' }
{'A -' }
{'B +' }
{'B -' }
{'AB +'}
{'AB -'}
{'O +' }
{'O -' }
限制
如果输入数组是数值、日期时间或持续时间数组,并且您根据输入中的值创建类别名称,则
categorical会将它们舍入到五位有效数字。例如,
categorical([1 1.23456789])根据这两个值创建类别名称1和1.2346。要根据连续的数值、持续时间或日期时间数据创建类别,请使用discretize函数。如果输入数组的数值、日期时间或持续时间值间距过小,则
categorical无法根据这些值创建类别名称。一般情况下,如果输入中任意两个值之间的差约小于5e-5,则这些值的间距过小。例如,
categorical([1 1.00001])无法根据这两个数值创建类别名称,因为它们之间的差太小。要根据连续的数值、持续时间或日期时间数据创建类别,请使用discretize函数。
提示
有关接受或返回分类数组的函数列表,请参阅分类数组。
扩展功能
版本历史记录
在 R2013b 中推出