parallelplot
创建平行坐标图

语法
说明
parallelplot(___, 使用一个或多个名称-值对组参量指定其他选项。例如,您可以为具有数值的坐标指定数据归一化方法。有关属性列表,请参阅 ParallelCoordinatesPlot 属性。Name,Value)
parallelplot( 在 parent,___)parent 指定的图窗、面板或选项卡中创建平行坐标图。
p = parallelplot(___)ParallelCoordinatesPlot 对象。创建对象后,使用 p 修改该对象。有关属性列表,请参阅 ParallelCoordinatesPlot 属性。
示例
根据医疗患者数据表创建一个平行坐标图。
加载 patients 数据集,并基于加载到工作区中的变量子集创建一个表。使用表创建一个平行坐标图。绘图中的每个线条对应于单个患者。使用绘图观测数据中的趋势。例如,绘图表明吸烟者往往具有较高的血压值(包括舒张压和收缩压)。
load patients
tbl = table(Diastolic,Smoker,Systolic);
p = parallelplot(tbl)
p =
ParallelCoordinatesPlot with properties:
SourceTable: [100×3 table]
CoordinateVariables: {'Diastolic' 'Smoker' 'Systolic'}
GroupVariable: ''
Show all properties
默认情况下,软件会沿坐标标尺随机抖动绘图线条,使其不会完全重叠。这种抖动对于可视化分类数据特别有用,因为它使您能够更轻松地区分绘图线条。例如,沿 Smoker 坐标标尺观察绘图线条;这些绘图线条并没有完全对齐到 true 或 false 刻度线。
要禁用默认抖动,请将 Jitter 属性设置为 0。
p.Jitter = 0;

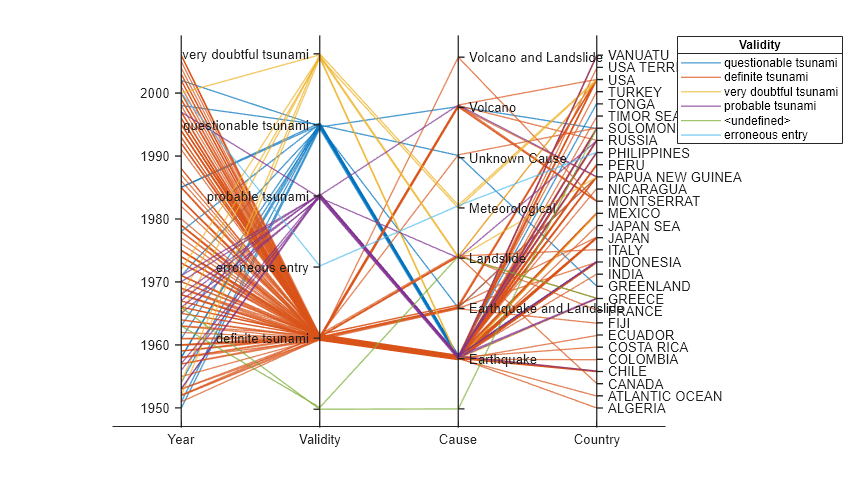
根据海啸数据表创建一个平行坐标图。指定要显示的表变量及其顺序,并根据其中一个变量对绘图中的线条进行分组。
将海啸数据以表形式读入工作区中。
tsunamis = readtable('tsunamis.xlsx');使用该表中的变量子集创建一个平行坐标图。首先,增大图窗窗口大小,以防止绘图过度拥挤。然后,要指定变量及其顺序,请使用 'CoordinateVariables' 名称-值对组参量。要根据有效性对海啸事件进行分组,请将 'GroupVariable' 名称-值对组参量设置为 'Validity'。绘图中的每个线条对应于单个海啸事件。绘图表明数据集中大多数具有 Validity 值的事件被认为是确定的海啸。
figure('Units','normalized','Position',[0.3 0.3 0.45 0.4]) coordvars = {'Year','Validity','Cause','Country'}; p = parallelplot(tsunamis,'CoordinateVariables',coordvars,'GroupVariable','Validity');
根据包含医疗患者数据的矩阵创建一个平行坐标图。对矩阵中一个列的值进行分 bin,并使用分 bin 值对绘图中的线条进行分组。
加载 patients 数据集,并根据 Age、Height 和 Weight 值创建一个矩阵。使用矩阵数据创建一个平行坐标图。为绘图中的坐标变量添加标签。绘图中的每个线条对应于单个患者。
load patients
X = [Age Height Weight];
p = parallelplot(X)p =
ParallelCoordinatesPlot with properties:
Data: [100×3 double]
CoordinateData: [1 2 3]
GroupData: []
Show all properties
p.CoordinateTickLabels = {'Age (years)','Height (inches)','Weight (pounds)'};
创建一个新分类变量,该分类变量将每个患者归入三个类别之一:short、average 或 tall。设置 bin 边界,使其包括最小和最大 Height 值。
min(Height)
ans = 60
max(Height)
ans = 72
binEdges = [60 64 68 72];
bins = {'short','average','tall'};
groupHeight = discretize(Height,binEdges,'categorical',bins);现在使用 groupHeight 值对平行坐标图中的线条分组。绘图表明 short 患者体重往往低于 tall 患者。
p.GroupData = groupHeight;

根据包含医疗患者数据的矩阵创建平行坐标图。对于每个绘图,指定要显示的矩阵列,并根据一个单独变量对绘图中的线条进行分组。
加载 patients 数据集,并基于加载到工作区的变量中的一部分创建一个矩阵。
load patients
X = [Age Height Weight];使用矩阵 X 中的列的子集创建一个平行坐标图。要指定列及其顺序,请使用 'CoordinateData' 名称-值对组参量。通过将 Smoker 值传递给 'GroupData' 名称-值对组参量,根据患者是否为吸烟者对其进行分组。绘图中的每个线条对应于单个患者。绘图表明是否为吸烟者与年龄或体重之间没有明显的关系。
coorddata = [1 3]; p = parallelplot(X,'CoordinateData',coorddata,'GroupData',Smoker)
p =
ParallelCoordinatesPlot with properties:
Data: [100×3 double]
CoordinateData: [1 3]
GroupData: [100×1 logical]
Show all properties
p.CoordinateTickLabels = {'Age','Weight'};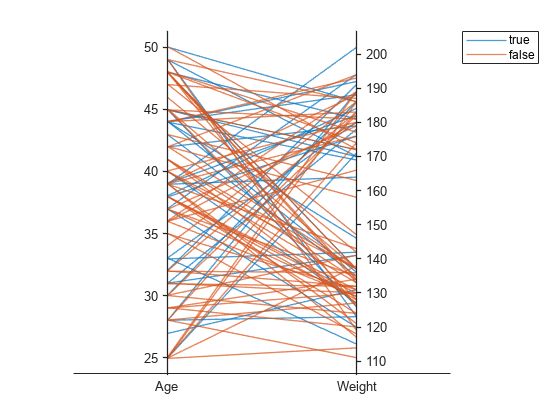
使用 X 中列的另一个子集创建另一个平行坐标图。根据患者的性别对其进行分组。绘图表明男人的身高和体重高于女人。
coorddata2 = [2 3]; p2 = parallelplot(X,'CoordinateData',coorddata2,'GroupData',Gender)
p2 =
ParallelCoordinatesPlot with properties:
Data: [100×3 double]
CoordinateData: [2 3]
GroupData: {100×1 cell}
Show all properties
p2.CoordinateTickLabels = {'Height','Weight'};
根据停电数据表创建一个平行坐标图。更改数值坐标变量的归一化方法。
将停电数据以表形式读入工作区中。显示表的前几行。
outages = readtable('outages.csv');
head(outages) Region OutageTime Loss Customers RestorationTime Cause
_____________ ________________ ______ __________ ________________ ___________________
{'SouthWest'} 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 {'winter storm' }
{'SouthEast'} 2003-01-23 00:49 530.14 2.1204e+05 NaT {'winter storm' }
{'SouthEast'} 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 {'winter storm' }
{'West' } 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 {'equipment fault'}
{'MidWest' } 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 {'severe storm' }
{'West' } 2003-06-18 02:49 0 0 2003-06-18 10:54 {'attack' }
{'West' } 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 {'equipment fault'}
{'West' } 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 {'equipment fault'}
创建一个名为 OutageDuration 的新变量,指示每次停电持续的时间。将 OutageDuration 转换为每次停电持续的天数。将该新变量添加到 outages 表中,并将其命名为 OutageDays。
OutageDuration = outages.RestorationTime - outages.OutageTime; outages.OutageDays = days(OutageDuration);
使用 Loss、Customers 和 OutageDays 变量创建一个平行坐标图。由于坐标变量是数值,因此使用 'DataNormalization' 和 'Jitter' 名称-值对组参量将绘图中的值显示为 Z 分数,不使用任何抖动。
coordvars = {'Loss','Customers','OutageDays'};
p = parallelplot(outages,'CoordinateVariables',coordvars,'DataNormalization','zscore','Jitter',0);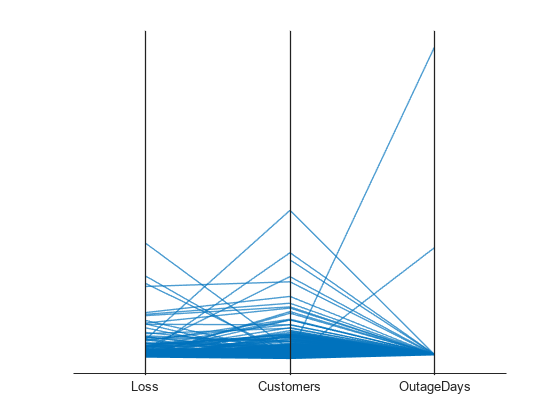
OutageDays 变量包含一个偏离 OutageDays 均值超过 30 个标准差的值和另一个偏离均值超过 10 个标准差的值。将鼠标悬停在绘图中的值上以显示数据提示。每个数据提示表示与绘图中的线条对应的表行。

在 outages 表中查找具有刚才识别的 OutageDays 极值的行。您会注意到,这两次停电的 RestorationTime 值是不正常的。
outliers = outages([1011 269],:)
outliers=2×7 table
Region OutageTime Loss Customers RestorationTime Cause OutageDays
_____________ ________________ ______ __________ ________________ ____________________ __________
{'NorthEast'} 2009-08-20 02:46 NaN 1.7355e+05 2042-09-18 23:31 {'severe storm' } 12083
{'MidWest' } 2008-02-07 06:18 2378.7 0 2019-08-14 16:16 {'energy emergency'} 4206.4
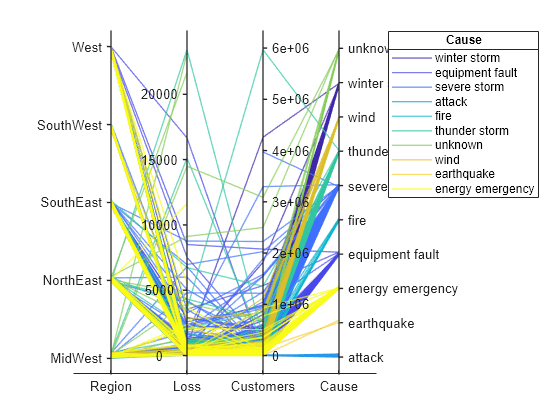
创建一个平行坐标图。对其中一个坐标变量的类别重新排序。
将停电数据以表形式读入工作区中。
outages = readtable('outages.csv');使用表中的列的子集创建一个平行坐标图。根据导致停电的事件对绘图中的线条分组。
coordvars = [1 3 4 6]; p = parallelplot(outages,'CoordinateVariables',coordvars,'GroupVariable','Cause');

通过更新源表,更改 Cause 中事件的顺序。首先,将 Cause 转换为一个 categorical 变量,指定事件的新顺序,并使用 reordercats 函数创建一个名为 orderCause 的新变量。然后,在绘图的源表中,用新 orderCause 变量替换原来的 Cause 变量。
categoricalCause = categorical(p.SourceTable.Cause);
newOrder = {'attack','earthquake','energy emergency','equipment fault', ...
'fire','severe storm','thunder storm','wind','winter storm','unknown'};
orderCause = reordercats(categoricalCause,newOrder);
p.SourceTable.Cause = orderCause;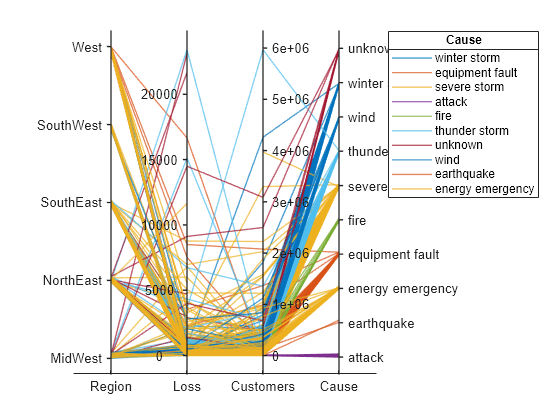
由于 Cause 变量包含七个以上的类别,因此绘图中的一些组具有相同的颜色。通过更改 p 的 Color 属性,为每个组分配不同颜色。
p.Color = parula(10);
输入参数
名称-值参数
将可选参量对组指定为 Name1=Value1,...,NameN=ValueN,其中 Name 是参量名称,Value 是对应的值。名称-值参量必须出现在其他参量之后,但对各个参量对组的顺序没有要求。
如果使用的是 R2021a 之前的版本,请使用逗号分隔每个名称和值,并用引号将 Name 引起来。
示例: parallelplot(data,'GroupData',grpdata,'DataNormalization','zscore','Jitter',0) 指定使用 grpdata 对 data 中的数值数据进行分组,并将数据显示为 Z 分数,且不使用任何抖动。
绘图标题,指定为字符向量、字符串数组、字符向量元胞数组或分类数组。默认情况下,绘图没有标题。
要创建一个多行标题,请指定字符串数组或字符向量元胞数组。数组中的每个元素对应一行文本。
如果将标题指定为分类数组,MATLAB® 将使用数组中的值,而不是类别。
示例: p = parallelplot(__,'Title','My Title Text')
示例: p.Title = 'My Title Text'
示例: p.Title = {'My','Title'}
具有数值的坐标的归一化方法,指定为以下选项之一。
| 方法 | 描述 |
|---|---|
'range' | 沿具有独立最小值和最大值的坐标标尺显示原始数据 |
'none' | 沿具有相同最小值和最大值的坐标标尺显示原始数据 |
'zscore' | 沿每个坐标标尺显示 Z 分数(均值为 0,标准差为 1) |
'scale' | 沿每个坐标标尺显示按标准差缩放的值 |
'center' | 沿每个坐标标尺显示均值为 0 的中心化数据 |
'norm' | 沿每个坐标标尺显示 2-范数值 |
有关这些方法的详细信息,请参阅 normalize。
对于作为逻辑向量、日期时间数组、持续时间数组、分类数组、字符串数组或字符向量元胞数组的坐标变量,parallelplot 沿坐标标尺均匀分布唯一的可能值,而不考虑归一化方法。
示例: p = parallelplot(__,'DataNormalization','none')
示例: p.DataNormalization = 'zscore'
沿坐标标尺的数据位移距离,指定为区间 [0,1] 中的数值标量。Jitter 值决定绘图线条从实际值出发沿坐标标尺位移的最大距离,其中位移是均匀随机量。如果您将 Jitter 属性设置为 1,则相邻抖动区域会恰好彼此接触。将 Jitter 属性设置为 0 可显示实际数据值。
一定程度的抖动对可视化分类数据特别有帮助,因为抖动使您能够更轻松地区分绘图线条。但是,Jitter 值会影响所有坐标变量,包括数值变量。
示例: p = parallelplot(__,'Jitter',0.5)
示例: p.Jitter = 0.2
组颜色,指定为下列形式之一:
指定颜色名称、短名称或十六进制颜色代码的字符向量。十六进制颜色代码以井号 (
#) 开头,后跟三个或六个0到F范围内的十六进制数字。这些值不区分大小写。因此,颜色代码'#FF8800'与'#ff8800'、'#F80'与'#f80'是等效的。指定一个或多个颜色名称、短名称或十六进制颜色代码的字符串数组或字符向量元胞数组。
范围 [0,1] 内的 RGB 值的三列矩阵。三列代表 R 值、G 值和 B 值。
从这些预定义的颜色、其等效 RGB 三元组及其十六进制颜色代码中进行选择。
| 颜色名称 | 短名称 | RGB 三元组 | 十六进制颜色代码 | 外观 |
|---|---|---|---|---|
"red" | "r" | [1 0 0] | "#FF0000" |
|
"green" | "g" | [0 1 0] | "#00FF00" |
|
"blue" | "b" | [0 0 1] | "#0000FF" |
|
"cyan" | "c" | [0 1 1] | "#00FFFF" |
|
"magenta" | "m" | [1 0 1] | "#FF00FF" |
|
"yellow" | "y" | [1 1 0] | "#FFFF00" |
|
"black" | "k" | [0 0 0] | "#000000" |
|
"white" | "w" | [1 1 1] | "#FFFFFF" |
|








下表列出了浅色和深色主题中绘图的默认调色板。
| 调色板 | 调色板颜色 |
|---|---|
在 R2025a 之前的版本中: 大多数绘图默认使用这些颜色。 |
|
|
|


您可以使用 orderedcolors 和 rgb2hex 函数获取这些调色板的 RGB 三元组和十六进制颜色代码。例如,获取 "gem" 调色板的 RGB 三元组并将其转换为十六进制颜色代码。
RGB = orderedcolors("gem");
H = rgb2hex(RGB);在 R2023b 之前的版本中: 使用 RGB = get(groot,"FactoryAxesColorOrder") 获取 RGB 三元组。
在 R2024a 之前的版本中: 使用 H = compose("#%02X%02X%02X",round(RGB*255)) 获取十六进制颜色代码。
默认情况下,parallelplot 最多分配七种唯一的组颜色。当组的总数超过指定的颜色数量时,parallelplot 将循环使用指定的颜色。
示例: p = parallelplot(__,'Color',{'blue','black','green'})
示例: p.Color = [0 0 1; 0 0.5 0.5; 0.5 0.5 0.5]
示例: p.Color = {'#EDB120','#77AC30','#7E2F8E'}
输出参量
详细信息
提示
要以交互方式浏览
ParallelCoordinatesPlot对象中的数据,请使用以下选项(有些选项在实时编辑器中不可用):缩放 - 使用滚轮进行缩放。
平移 - 点击并拖动平行坐标图以进行平移。
数据提示 - 将鼠标悬停在平行坐标图上以显示数据提示。软件突出显示绘图中对应的线条。有关示例,请参阅在绘图中更改数据归一化。
重新排列坐标 - 点击并水平拖动坐标刻度标签,将对应的坐标标尺移至另一位置。有关示例,请参阅 使用平行坐标图探索表数据。
如果基于表创建平行坐标图,则可以自定义其数据提示。平行坐标图上的数据提示始终显示所选点的值,即使您已删除所有行也是如此。
要在数据提示中添加或删除行,请右键点击图上的任意位置,然后指向修改数据提示。然后,选择或取消选择一个变量。
要添加或删除多行,请右键点击图,指向修改数据提示,然后选择更多。然后,通过点击 >> 添加变量,或通过点击 << 删除变量。
版本历史记录
在 R2019a 中推出