scatterhistogram
创建带直方图的散点图

语法
说明
scatterhistogram(___, 使用一个或多个名称-值对组参量指定边缘带直方图的散点图的其他选项。请在所有其他输入参量之后指定这些选项。有关属性列表,请参阅 ScatterHistogramChart 属性。Name,Value)
scatterhistogram( 在由 parent,___)parent 指定的图窗、面板或选项卡上创建边缘带直方图的散点图。
s = scatterhistogram(___)ScatterHistogramChart 对象。创建对象后,使用 s 修改该对象。有关属性列表,请参阅 ScatterHistogramChart 属性。
示例
基于医疗患者数据表创建边缘带直方图的散点图。
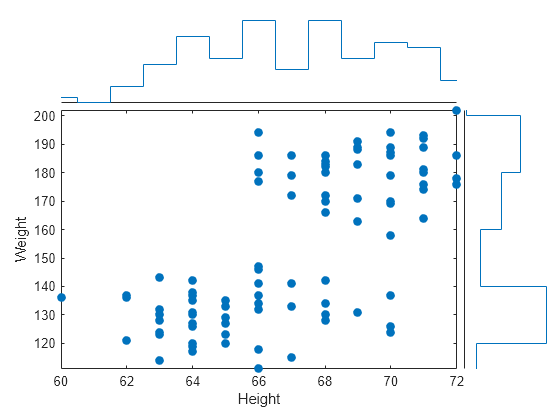
加载 patients 数据集,并基于加载到工作区中的变量子集创建一个表。然后,创建一个散点直方图,用于将 Height 值与 Weight 值进行比较。
load patients tbl = table(LastName,Age,Gender,Height,Weight); s = scatterhistogram(tbl,'Height','Weight');
使用 patients 数据集,创建一个边缘带直方图的散点图,并指定用于对数据进行分组的表变量。
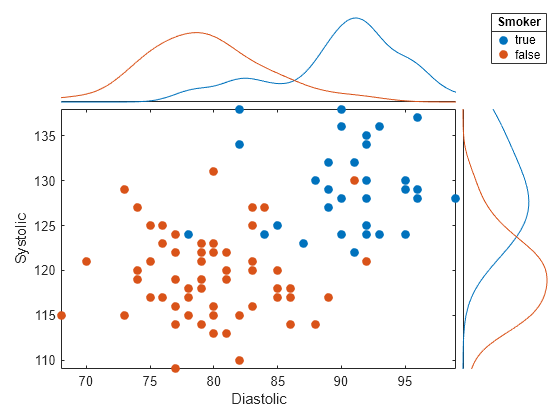
加载 patients 数据集并基于数据创建一个散点直方图。比较患者的 Systolic 和 Diastolic 值。通过将 'GroupVariable' 名称-值对组参量设置为 'Smoker',根据患者的吸烟者状态对数据进行分组。
load patients tbl = table(LastName,Diastolic,Systolic,Smoker); s = scatterhistogram(tbl,'Diastolic','Systolic','GroupVariable','Smoker');

使用边缘带直方图的散点图,以可视方式呈现分类医疗数据和数值医疗数据。
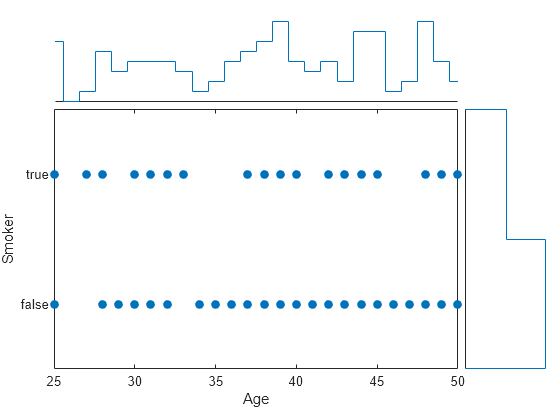
加载 patients 数据集,并将 Smoker 数据转换为分类数组。然后,创建一个散点直方图,用于将患者的 Age 值与其吸烟者状态进行比较。生成的散点图包含重叠的数据点。然而,y 轴边缘直方图指示数据集中的非吸烟者远远多于吸烟者。
load patients Smoker = categorical(Smoker); s = scatterhistogram(Age,Smoker); xlabel('Age') ylabel('Smoker')
使用鞋数据的数组创建一个边缘带直方图的散点图。根据鞋的颜色对数据进行分组,并自定义散点直方图的属性。
创建数据数组。然后,创建一个散点直方图以可视化数据。沿 x 轴和 y 轴使用自定义标签指定前两个输入参量的变量名称。您可以通过设置 ScatterHistogramChart 对象的属性来指定标题、轴标签和图例标题。
xvalues = [7 6 5 6.5 9 7.5 8.5 7.5 10 8];
yvalues = categorical({'onsale','regular','onsale','onsale', ...
'regular','regular','onsale','onsale','regular','regular'});
grpvalues = {'Red','Black','Blue','Red','Black','Blue','Red', ...
'Red','Blue','Black'};
s = scatterhistogram(xvalues,yvalues,'GroupData',grpvalues, ...
LegendVisible = "on");
s.Title = 'Shoe Sales';
s.XLabel = 'Shoe Size';
s.YLabel = 'Price';
s.LegendTitle = 'Shoe Color';更改散点直方图中的颜色以匹配分组标签。更改直方图中的 bin 宽度,便每个组的 bin 宽度都相同。
s.Color = {'Red','Black','Blue'};
s.BinWidths = 1;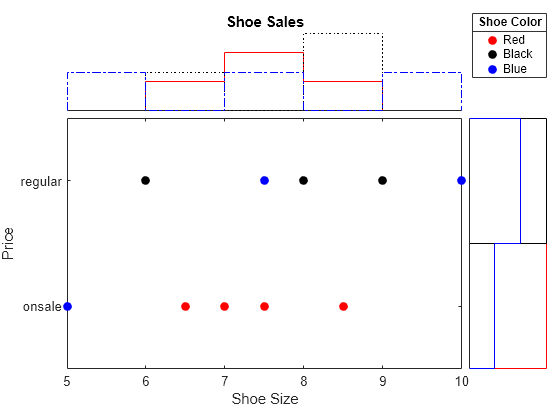
创建一个边缘带直方图的散点图。指定直方图的 bin 数和线宽、散点图的位置以及图例可见性。
加载 patients 数据集并基于数据创建一个散点直方图。比较患者的 Diastolic 和 Systolic 值,并根据患者的 SelfAssessedHealthStatus 值对数据进行分组。通过指定 NumBins 和 LineWidth 选项来调整直方图。使用 ScatterPlotLocation 选项将散点图放在图窗的 'NorthEast' 位置。通过将 LegendVisible 选项指定为 'on',确保图例可见。
load patients tbl = table(LastName,Diastolic,Systolic,SelfAssessedHealthStatus); s = scatterhistogram(tbl,'Diastolic','Systolic','GroupVariable','SelfAssessedHealthStatus', ... 'NumBins',4,'LineWidth',1.5,'ScatterPlotLocation','NorthEast','LegendVisible','on');

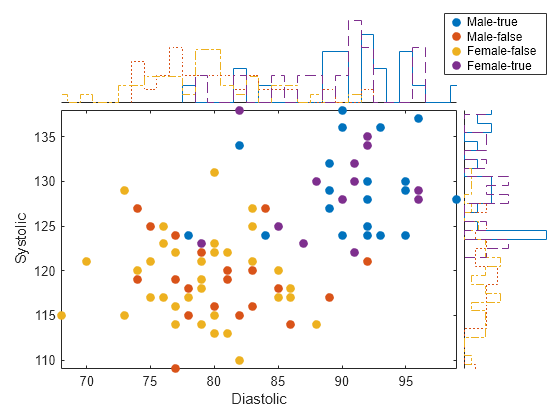
创建一个边缘带直方图的散点图。使用两个不同变量的组合对数据进行分组。
加载 patients 数据集。合并 Smoker 和 Gender 数据以创建一个新变量。创建一个散点直方图,用于比较患者的 Diastolic 和 Systolic 值。使用新变量 SmokerGender 对散点直方图中的数据进行分组。
load patients [idx,genderStatus,smokerStatus] = findgroups(string(Gender),string(Smoker)); SmokerGender = strcat(genderStatus(idx),"-",smokerStatus(idx)); s = scatterhistogram(Diastolic,Systolic,'GroupData',SmokerGender,'LegendVisible','on'); xlabel('Diastolic') ylabel('Systolic')
创建一个边缘带核密度直方图的散点图。
加载 patients 数据集。基于 Diastolic、Systolic 和 Smoker 变量创建一个表。
load patients.mat
tbl = table(Diastolic,Systolic,Smoker); 创建一个散点直方图,用于比较患者的 Diastolic 和 Systolic 压力值。使用患者吸烟状态对数据进行分组,并显示边缘核密度图。该图显示与非吸烟者相比吸烟者的平均收缩压和舒张压更高。
s = scatterhistogram(tbl,"Diastolic","Systolic", ... GroupVariable="Smoker",HistogramDisplayStyle="smooth", ... LineStyle="-");
输入参数
名称-值参数
将可选参量对组指定为 Name1=Value1,...,NameN=ValueN,其中 Name 是参量名称,Value 是对应的值。名称-值参量必须出现在其他参量之后,但对各个参量对组的顺序没有要求。
如果使用的是 R2021a 之前的版本,请使用逗号分隔每个名称和值,并用引号将 Name 引起来。
示例: scatterhistogram(tbl,xvar,yvar,'GroupVariable',grpvar,'HistogramDisplayStyle','stairs') 将 grpvar 指定为分组变量,并在散点图旁边显示阶梯图。
注意
此处所列的属性只是一部分。有关完整列表,请参阅 ScatterHistogramChart 属性。
从这些标记选项中进行选择。
| 标记 | 描述 | 生成的标记 |
|---|---|---|
"o" | 圆圈 |
|
"+" | 加号 |
|
"*" | 星号 |
|
"." | 点 |
|
"x" | 叉号 |
|
"_" | 水平线条 |
|
"|" | 垂直线条 |
|
"square" | 方形 |
|
"diamond" | 菱形 |
|
"^" | 上三角 |
|
"v" | 下三角 |
|
">" | 右三角 |
|
"<" | 左三角 |
|
"pentagram" | 五角形 |
|
"hexagram" | 六角形 |
|
"none" | 无标记 | 不适用 |


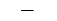
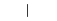

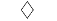


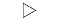
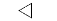
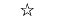

默认情况下,scatterhistogram 为散点图中的每个组指定标记符号 'o'。当组的总数超过指定的符号数量时,scatterhistogram 将循环使用指定的符号。
示例: s = scatterhistogram(__,'MarkerStyle','x')
示例: s.MarkerStyle = {'x','o'}
输出参量
详细信息
提示
要以交互方式浏览
ScatterHistogramChart对象中的数据,请使用以下选项。其中一些选项在实时编辑器中不可用。缩放/平移 - 使用滚轮或 + 和 - 键进行缩放。点击并拖动散点图以进行平移。
scatterhistogram根据当前散点图范围内的数据更新边缘直方图。数据提示 - 将鼠标悬停在散点图或边缘直方图上以显示数据提示。
如果基于表创建边缘带直方图的散点图,则可以自定义散点图的数据提示。
要在数据提示中添加或删除行,请右键点击散点图上的任意位置,然后指向修改数据提示。然后,选择或取消选择一个变量。
要添加或删除多行,请右键点击图,指向修改数据提示,然后选择更多。然后,通过点击 >> 添加变量,或通过点击 << 删除变量。