sorty
对热图列中的元素进行排序
语法
说明
sorty(___,'MissingPlacement', 指定将 lcn)NaN 元素放在排序顺序的开头还是末尾。将 lcn 指定为 'first'、'last' 或 'auto'。默认设置为 'auto',即升序时将 NaN 元素放在最后,降序时放在开头。在前面的任何输入参量组合之后使用此选项。
sorty( 按升序显示第一列中的元素。如果第一列包含重复的值,则 h)sorty 根据第二列重新排列其余的行,依此类推。
示例
创建一个电力中断热图,并对特定列中的值进行排序,使它们从上到下按升序显示。
首先创建一个热图。将示例文件 outages.csv 读入到表中。示例文件包含表示美国电力中断情况的数据。该表包含六列:Region、OutageTime、Loss、Customers、RestorationTime 和 Cause。创建一个热图,x 轴显示不同的区域,*y* 轴显示不同的停电原因。在每个单元格中,显示每个区域由于特定原因经历停电的次数。
T = readtable('outages.csv'); h = heatmap(T,'Region','Cause');
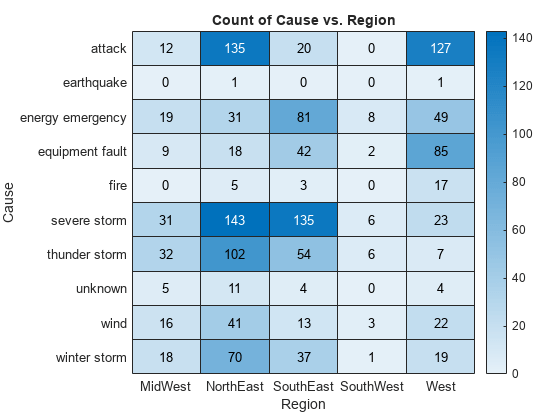
对 'NorthEast' 列中的值进行排序,使它们从上到下按升序显示。
sorty(h,'NorthEast')
创建一个电力中断热图,并通过重新排列各行,按降序显示 'NorthEast' 列中的值。
T = readtable('outages.csv'); h = heatmap(T,'Region','Cause'); sorty(h,'NorthEast','descend')

创建一个电力中断热图,并使用多个列中的值重新排列各行。对行进行排序,使 'SouthWest' 列按升序显示。由于该列包含重复的值,因此使用 'NorthEast' 列对其余的行进行排序。
T = readtable('outages.csv'); h = heatmap(T,'Region','Cause'); sorty(h,{'SouthWest','NorthEast'})
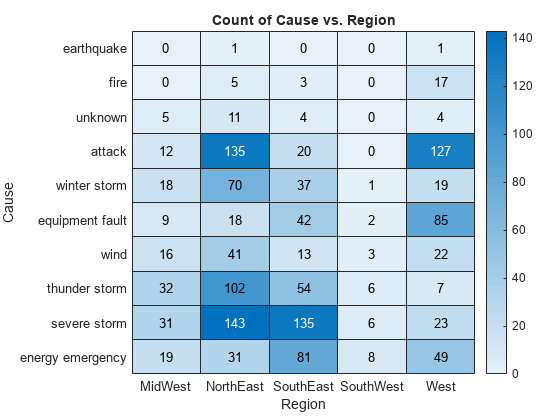
创建一个电力中断热图,并对 'NorthEast' 列中的值进行排序,使它们按升序从上到下显示。按照 y 轴上的显示顺序返回排序的颜色数据和行值(y 值)。
T = readtable('outages.csv'); h = heatmap(T,'Region','Cause'); [C,y] = sorty(h,'NorthEast')

C = 10×5
0 1 0 0 1
0 5 3 0 17
5 11 4 0 4
9 18 42 2 85
19 31 81 8 49
16 41 13 3 22
18 70 37 1 19
32 102 54 6 7
12 135 20 0 127
31 143 135 6 23
y = 10×1 cell
{'earthquake' }
{'fire' }
{'unknown' }
{'equipment fault' }
{'energy emergency'}
{'wind' }
{'winter storm' }
{'thunder storm' }
{'attack' }
{'severe storm' }
创建一个电力中断热图,并通过重新排列各列,按升序(从上到下)对左列中的值进行排序。然后还原原始顺序。
T = readtable('outages.csv'); h = heatmap(T,'Region','Cause'); sorty(h)

通过将 HeatmapChart 对象的 YDisplayData 属性设置为等于 YData 属性来还原原始行顺序。
h.YDisplayData = h.YData;

输入参数
输出参量
算法
sorty 函数可以设置以下 HeatmapChart 对象属性:
YDisplayData- 用于存储 y 轴数据的属性。ColorDisplayData- 用于存储颜色显示数据的属性。
sorty 函数还可以重置 YLimits 属性。
版本历史记录
在 R2017b 中推出