大数据处理
使用分布式数组、tall 数组、数据存储或
mapreduce 在 Spark® 和 Hadoop® 集群上并行分析大数据集您可以使用 Parallel Computing Toolbox™ 将大型数组分布在多个 MATLAB® 工作单元上,以便于您运行使用集群总内存的大数据应用程序。您可以将整个数组作为单个实体进行操作,但是,工作单元仅对其所属的数组部分进行操作,并在必要时自动在它们之间传输数据。Parallel Computing Toolbox 还使您能够并行执行 MATLAB tall 数组和 datastore 计算,以便您可以分析集群内存中无法容纳的大数据集。您可以使用 MATLAB Parallel Server™ 在启用 Spark 的 Hadoop 集群上并行运行 tall 数组和 datastore 计算。这样做可以显著减少计算超大数据所需的时间。
类别
- 分布式数组
使用分布式数组和同时执行功能并行分析大数据集
- tall 数组和 mapreduce
使用 MATLAB tall 数组和数据存储或mapreduce在 Spark 和 Hadoop 集群上以及使用并行池并行分析大数据集
精选示例
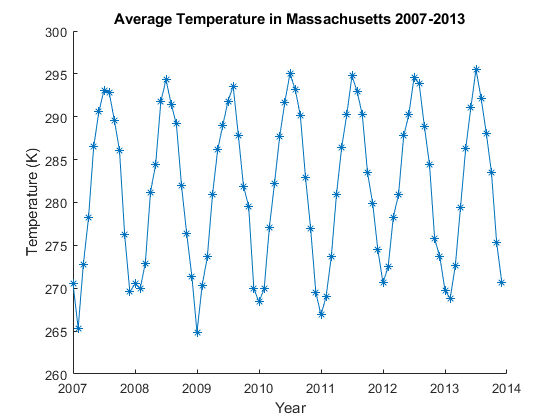
在云中处理大数据
此示例展示了如何访问云中的大型数据集,并使用 MATLAB® 大数据功能在云集群中对其进行处理。
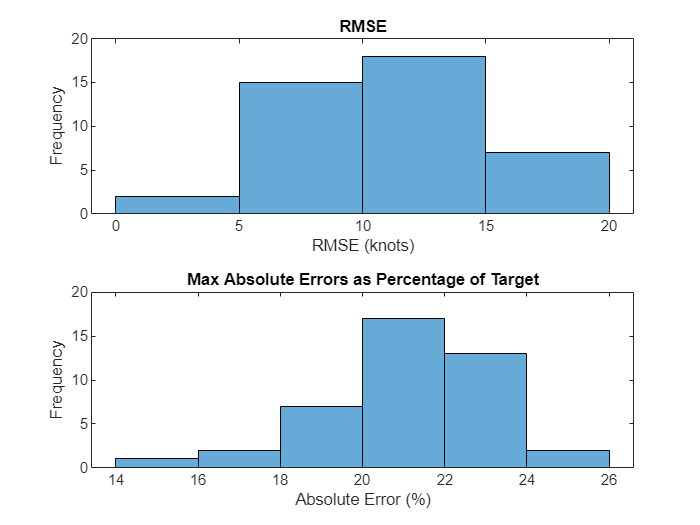
使用并行计算优化大数据集进行分析
此示例展示如何使用并行计算优化数据预处理以进行分析。